

We are thrilled to announce the release of Typhoon 2, a transformative leap forward in Thai natural language processing (NLP) and multimodal AI capabilities. Building upon our work with Typhoon 1.5 and 1.5X, this new version introduces powerful updates across text-based models and multimodal models, all designed to support advanced applications in Thai and beyond.
What’s Included in this Release?

Typhoon 2 models are available in 1B, 3B, 7B, 8B, and 70B sizes (both pretrained and instruct models), with significant enhancements optimized for the Thai language. Experimental results demonstrate that Typhoon 2 models surpass Typhoon-1.5 in key benchmarks such as ThaiExam, M3Exam, and IFEval, achieving competitive performance compared to state-of-the-art large language models.
The Typhoon 2 models feature extended context lengths of up to 128,000 tokens, enabling the processing of longer documents and complex interactions. In addition, the small models (1B and 3B) are capable of performing simple tasks like summarization and translation locally on-device.
Typhoon 2 also introduces exciting advancements in multimodal AI with research previews of Typhoon2-Audio and Typhoon2-Vision, setting the stage for more integrated and versatile applications.
Typhoon2-Audio features an end-to-end architecture capable of processing both text and audio inputs while generating text and audio outputs simultaneously. With improved audio understanding, it supports more detailed audio analysis and enhanced instruction-following performance. Its capabilities extend to multi-turn conversations, system prompt handling, and robust text-to-speech functionality, making it a powerful tool for speech-centric applications.
Meanwhile, Typhoon2-Vision elevates visual data processing with enhanced comprehension and built-in OCR capabilities, enabling seamless text extraction from images and documents. These multimodal innovations unlock new possibilities across domains such as healthcare, legal services, and education, fostering a more interconnected approach to AI-driven workflows.
The release also includes the IFEval-TH evaluation dataset and a comprehensive technical report, providing the community with tools and insights to better understand and leverage Typhoon 2.
Typhoon 2 Performance
To gain insight into Typhoon 2’s performance, we evaluated its capabilities on a variety of benchmarks, with the objective of evaluating Typhoon 2 from a variety of situations.
Language & Knowledge
- ThaiExam: A Thai language benchmark based on examinations for high school students and investment professionals in Thailand
- M3Exam: A benchmark sourced from real and official human exam questions for evaluating LLMs in a multilingual, multimodal, and multilevel context.
Small Models

| Model | ThaiExam | O-NET | IC | A-Level | TGAT | TPAT | M3Exam | Math | Science | Social | Thai |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Typhoon2-1B | 26.83% | 19.75% | 16.84% | 17.32% | 49.23% | 31.03% | 26.1% | 21.71% | 25.6% | 32.83% | 24.27% |
| Llama3.1-1B | 25.38% | 18.51% | 20% | 26.77% | 32.3% | 29.31% | 25.3% | 23.52% | 25.36% | 27.48% | 24.82% |
| Qwen2.5-1.5B | 42.31% | 33.33% | 43.15% | 27.55% | 66.15% | 41.37% | 38.14% | 30.76% | 34.54% | 49.12% | 38.13% |
1B Parameter Model Thai Language & Knowledge Performance
| Model | ThaiExam | O-NET | IC | A-Level | TGAT | TPAT | M3Exam | Math | Science | Social | Thai |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Typhoon2-3B | 44.53% | 40.12% | 40% | 26.77% | 69.23% | 46.55% | 41.84% | 24.43% | 41.3% | 60.07% | 41.56% |
| Qwen2.5-3B | 49.64% | 48.76% | 51.57% | 32.28% | 70.76% | 44.82% | 46.35% | 36.65% | 42.27% | 59.32% | 47.18% |
| Llama3.1-3B | 40.42% | 30.86% | 46.31% | 20.47% | 63.07% | 41.37% | 36.81% | 21.71% | 36.23% | 50.74% | 38.54% |
3B Parameter Model Thai Language & Knowledge Performance
| Model | ThaiExam | O-NET | IC | A-Level | TGAT | TPAT | M3Exam | Math | Science | Social | Thai |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Typhoon2-7B | 58.86% | 58.64% | 65.26% | 55.11% | 66.15% | 49.13% | 59.9% | 42.98% | 59.42% | 75.62% | 61.59% |
| Qwen2.5-7B | 55.74% | 51.23% | 60% | 41.73% | 72.3% | 53.44% | 55.65% | 46.15% | 54.1% | 66.54% | 55.82% |
| Typhoon-1.5-8B | 48.82% | 41.35% | 41.05% | 40.94% | 70.76% | 50% | 43.88% | 22.62% | 43.47% | 62.81% | 46.63% |
| Typhoon2-8B | 51.2% | 49.38% | 47.36% | 43.3% | 67.69% | 48.27% | 47.52% | 27.6% | 44.2% | 68.9% | 49.38% |
| Llama3.1-8B | 45.8% | 38.27% | 46.31% | 34.64% | 61.53% | 48.27% | 43.33% | 27.14% | 40.82% | 58.33% | 47.05% |
7B & 8B Parameter Model Thai Language & Knowledge Performance
The small Typhoon2 models demonstrate consistent improvements over LLaMA3.2–1B and LLaMA3.2–3B in ThaiExam and M3Exam benchmarks. While Qwen2.5 models lead slightly in some areas, Typhoon2’s 7B model achieves the highest scores in most categories, such as ThaiExam, O-NET, and TGAT, making it a strong choice for language comprehension and reasoning tasks in the Thai context.
Large Models

| Model | ThaiExam | O-NET | IC | A-Level | TGAT | TPAT | M3Exam | Math | Science | Social | Thai |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Typhoon1.5X-70B | 62.964% | 60.49% | 71.57% | 53.54% | 72.3% | 56.89% | 62.54% | 45.7% | 62.56% | 77.73% | 64.19% |
| Llama3.1-70B | 60.744% | 62.34% | 67.36% | 53.54% | 66.15% | 54.31% | 60.35% | 38.91% | 62.56% | 76.99% | 62.96% |
| Typhoon2-70B | 63.387% | 65.43% | 69.47% | 59.84% | 66.15% | 56.03% | 62.33% | 42.98% | 63.28% | 78.6% | 64.47% |
70B Parmater Model Thai Performance
The Typhoon2–70B model delivers the highest overall performance on ThaiExam and closely competes with Qwen2.5–72B on M3Exam and math benchmarks. Its strong scores across all categories confirm its dominance for Thai-specific tasks, offering a clear edge over LLaMA3.1–70B while rivaling the performance of proprietary models like GPT-4 in specific domains.
Instruction Following
- Function Calling Accuracy: Evaluates a model’s ability to interpret structured natural language prompts and interact with tools or APIs effectively
- IFEval-EN (Instruction-Following Evaluation in English): Benchmark designed to assess proficiency of LLMs in adhering to natural language instructions.
- IFEval-TH (Instruction-Following Evaluation in Thai): Instruction-following evaluation benchmark, with instructions translated into Thai
- MT-Bench-EN (Multi-task Benchmark in English): Evaluation framework design to assess LLM performance across diverse tasks and usability dimensions.
- MT-Bench-TH (VISTEC) (Multi-task Benchmark in Thai): MT-Bench evaluation with the test dataset translated into Thai
- Code Switching Accuracy: Evaluates a model’s ability to process mixed-language inputs (e.g., Thai and English), particularly important in multilingual settings like Thailand, where users often use both languages in conversation
Function Calling
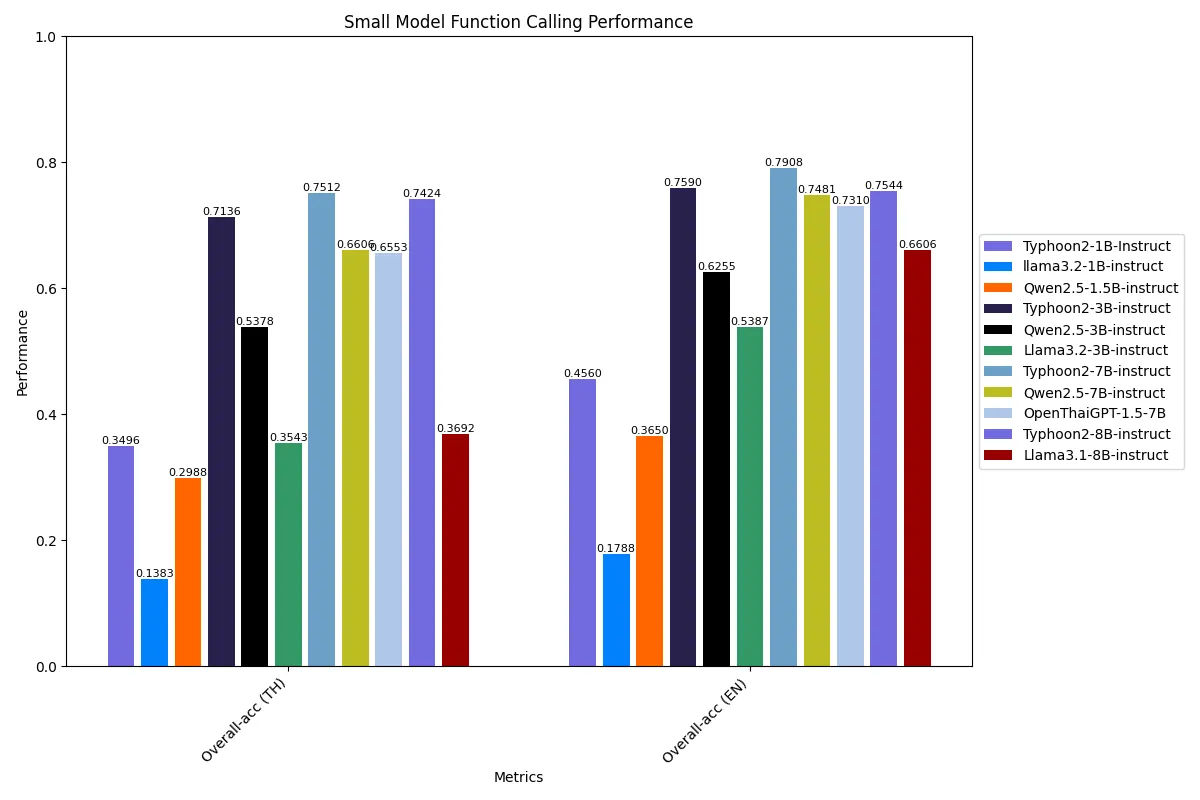
1B, 3B, 7B, and 8B Function Calling Performance
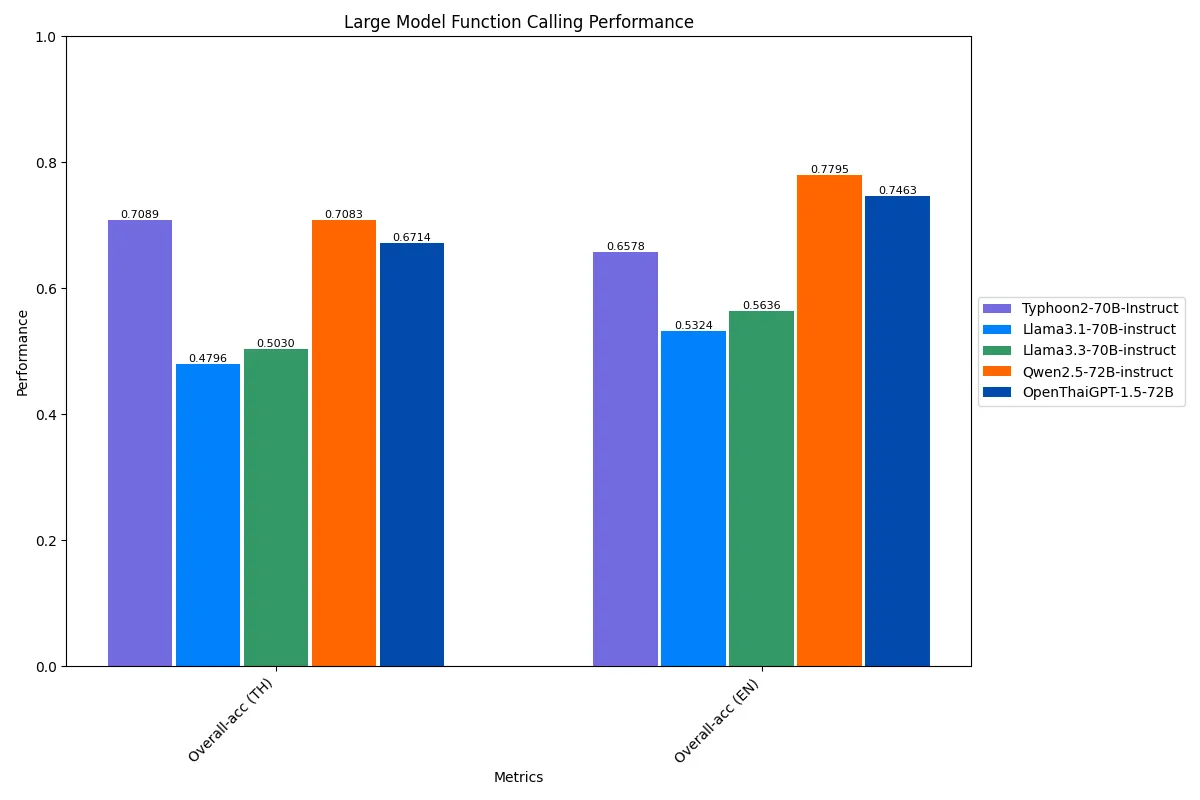
70B Model Function Calling Performance
Typhoon 2 demonstrates superior function-calling accuracy across both Thai and English contexts, consistently outperforming comparable open-source models like Qwen2.5 and LLaMA3. Among small models, the Typhoon2–7B model leads with 75.12% (TH) and 79.08% (EN), setting a new standard for mid-sized models in structured task execution.
For large models, the Typhoon2–70B maintains this strong performance, achieving 70.89% in Thai, on par with Qwen2.5–72B and far exceeding Llama3.1–70B. These results highlight Typhoon2’s reliability for applications requiring tool integration and structured instruction execution, making it particularly well-suited for automation workflows and real-world use cases requiring precise API interaction.
Instruction-Following
Small Models

1B, 3B, 7B, and 8B Instruction Following Performance
| Model | IFEval - TH | IFEval - EN | MT-Bench-TH | MT-Bench-EN | Thai-code switching @ temp 0.7 | Thai-code switching @ temp 1.0 |
|---|---|---|---|---|---|---|
| Typhoon2-1B-instruct | 52.46% | 53.35% | 39.725% | 52.125% | 96.4% | 88% |
| Qwen2.5-1.5B-instruct | 44.42% | 48.45% | 29.395% | 69.343% | 82.6% | 20.6% |
| llama3.2-1B-instruct | 31.76% | 51.15% | 25.824% | 62.29% | 97.8% | 22.6% |
1B Parameter Model Instruction-Following Performance
| Model | IFEval - TH | IFEval - EN | MT-Bench-TH | MT-Bench-EN | Thai-code switching @ temp 0.7 | Thai-code switching @ temp 1.0 |
|---|---|---|---|---|---|---|
| Typhoon2-3B-instruct | 68.36% | 72.18% | 53.352% | 72.06% | 99.2% | 96% |
| Qwen2.5-3B-instruct | 58.86% | 67.25% | 46.263% | 78.46% | 78.6% | 38% |
| llama3.2-3B-instruct | 44.84% | 71.98% | 43.241% | 77.25% | 93.8% | 21.2% |
3B Parameter Model Instruction-Following Performance
| Model | IFEval - TH | IFEval - EN | MT-Bench-TH | MT-Bench-EN | Thai-code switching @ temp 0.7 | Thai-code switching @ temp 1.0 |
|---|---|---|---|---|---|---|
| Typhoon1.5-8B-instruct | 58.68% | 71.33% | 51.813% | 73.375% | 98.6% | 98.8% |
| Typhoon2-7B-instruct | 74.37% | 73.34% | 61.86% | 80.94% | 99.2% | 96.8% |
| Typhoon2-8B-instruct | 72.6% | 76.43% | 57.417% | 75.84% | 98.8% | 98% |
| Qwen2.5-7B-instruct | 68.47% | 76.82% | 60% | 85.37% | 85.8% | 20.4% |
| Llama3.1-8B-instruct | 58.04% | 77.64% | 51.09% | 81.18% | 93% | 11.2% |
| OpenThaiGPT1.5-7B | 67.38% | 75.47% | 56.92% | 81.06% | 93.8% | 28% |
| Pathumma1.0-7B | 50.6% | 46.21% | 48.461% | 72.75% | 99.2% | 91.2% |
| gpt-4o-0724-mini | 77.37% | 84.46% | 75.164% | 92% | 99.2% | 98.2% |
| Gemini Flash | 79.11% | 87.81% | 76.373% | 89.343% | 97.6% | 97.6% |
7B, 8B, and Proprietary Model Instruction-Following Performance
**Typhoon 2’**s small models excel in instruction-following tasks, particularly at the 3B and 7B levels. The 7B model delivers the highest performance across IFEval-TH, MT-Bench-TH, and Code Switching Accuracy, outperforming competitors like Qwen2.5–7B. Its ability to handle bilingual inputs makes it an ideal choice for Thai-English mixed-use cases.
Large & Proprietary Models
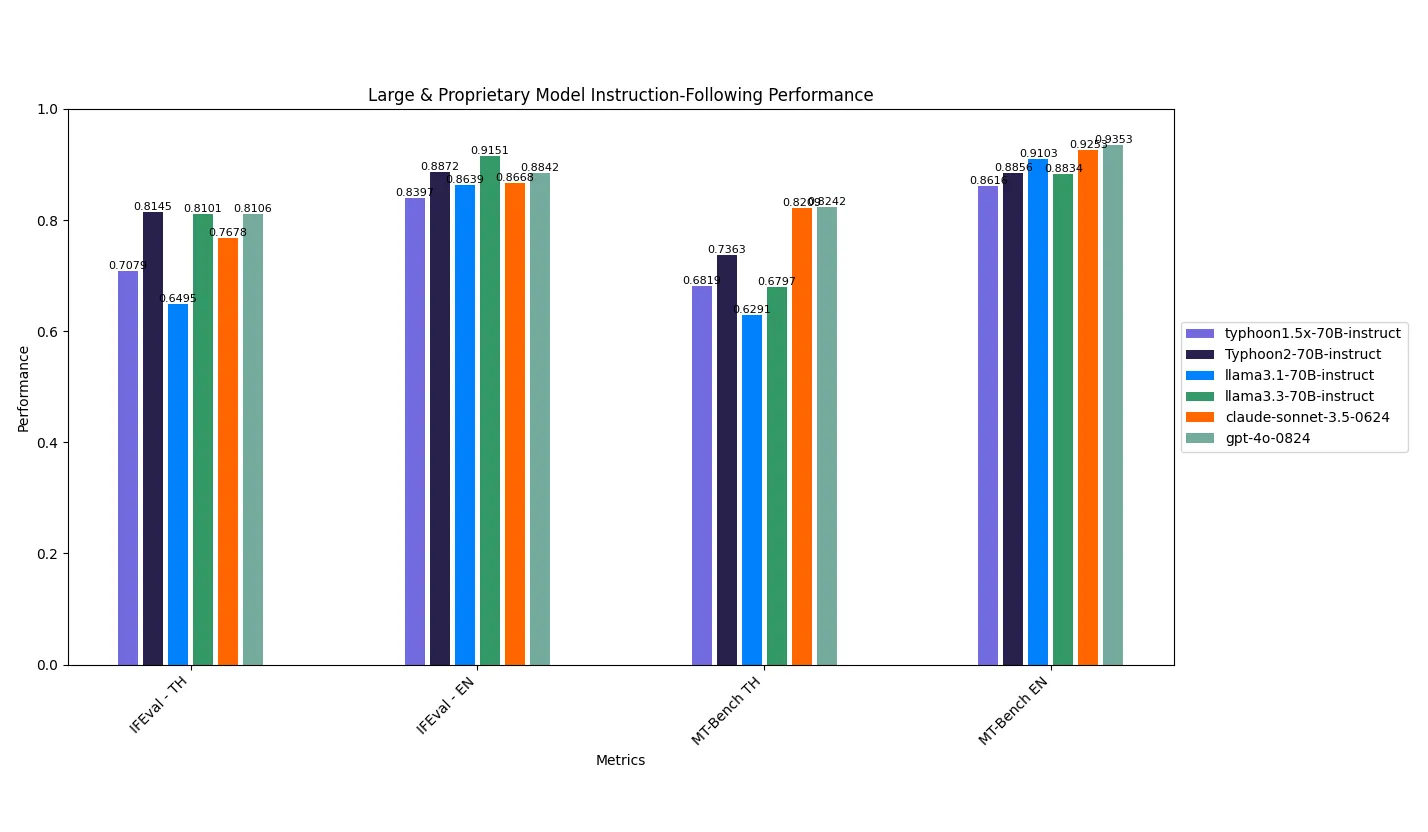
70B Instruction Following Performance | MT-Bench is divided by 10 for better visualization
| Model | IFEval - TH | IFEval - EN | MT-Bench-TH | MT-Bench-EN | Thai-code switching @ temp 0.7 | Thai-code switching @ temp 1.0 |
|---|---|---|---|---|---|---|
| typhoon1.5x-70B-instruct | 70.79% | 83.97% | 68.186% | 86.156% | 98.6% | 88.6% |
| Typhoon2-70B-instruct | 81.45% | 88.72% | 73.626% | 88.562% | 98.8% | 94.8% |
| llama3.1-70B-instruct | 64.95% | 86.39% | 62.912% | 91.031% | 90.2% | 53.0% |
| llama3.3-70B-instruct | 81.01% | 91.51% | 67.967% | 88.343% | 72.6% | 39.2% |
| claude-sonnet-3.5-0624 | 76.78% | 86.68% | 82.087% | 92.531% | 96.4% | 96.6% |
| gpt-4o-0824 | 81.06% | 88.42% | 82.417% | 93.531% | 99.6% | 98.8% |
Large & Proprietary Model Instruction-Following Performance
The Typhoon2–70B model delivers superior results on IFEval-TH, MT-Bench-TH, and Code Switching Accuracy benchmarks, showcasing its strength in Thai instruction-following tasks. It also demonstrates competitive performance on English benchmarks, rivaling Qwen2.5–72B and proprietary systems like GPT-4o. This makes Typhoon2–70B a solid option for complex, multilingual instruction-following use cases.
Specialized Task Performance
- GSM8K (Grade School Math 8K): A benchmark designed to assess models’ mathematical reasoning skills on grade-school-level problems. Results are evaluated for both English (GSM8K-EN) and Thai (GSM8K-TH) problem sets.
- MATH (Mathematical Reasoning): Focuses on higher-level mathematical problem-solving tasks that include algebra, calculus, and geometry. Performance is assessed in both English (MATH-EN) and Thai (MATH-TH).
- HumanEval (Code Generation Benchmark): Evaluates a model’s ability to generate functional code based on natural language prompts. Results are provided for both English (HumanEval-EN) and Thai (HumanEval-TH).
- MBPP (Multiple Programming Problems Benchmark): Tests the model’s performance on programming tasks, such as writing and fixing code snippets, with evaluations in both English (MBPP-EN) and Thai (MBPP-TH).
Small Models
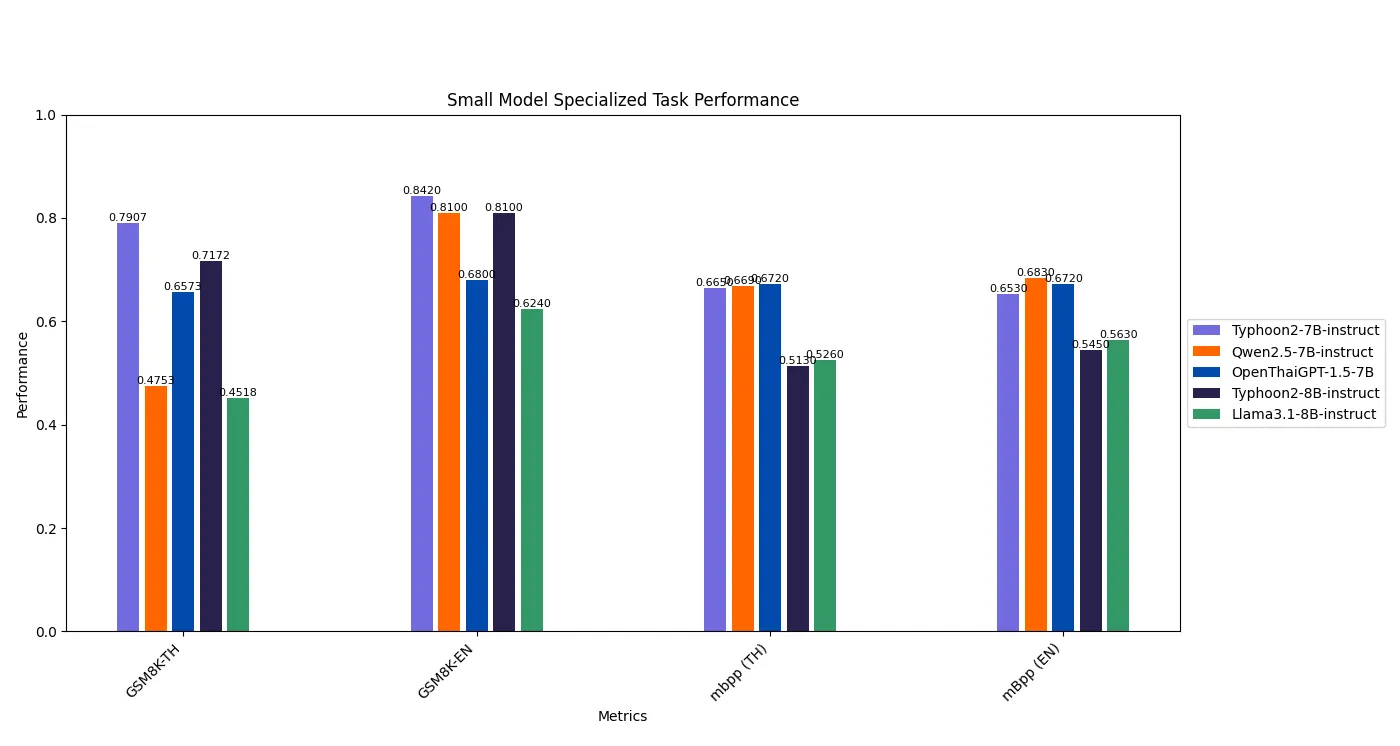
Small Model Specialized Task Performance
| Model | GSM8K-TH | GSM8K-EN | MATH-TH | MATH-EN | HumanEval (TH) | HumanEval (EN) | mbpp (TH) | mBpp (EN) |
|---|---|---|---|---|---|---|---|---|
| Typhoon2-7B-instruct | 79.07% | 84.2% | 55.42% | 66.42% | 68.3% | 72.6% | 66.5% | 65.3% |
| Qwen2.5-7B-instruct | 47.53% | 81% | 17.41% | 73.4% | 72.6% | 75% | 66.9% | 68.3% |
| OpenThaiGPT-1.5-7B | 65.73% | 68% | 24.44% | 69.68% | 64.6% | 75.6% | 67.2% | 67.2% |
| Typhoon2-8B-instruct | 71.72% | 81% | 38.48% | 49.04% | 55.5% | 65.2% | 51.3% | 54.5% |
| Llama3.1-8B-instruct | 45.18% | 62.4% | 24.42% | 48% | 48.2% | 61% | 52.6% | 56.3% |
Typhoon2–7B-instruct delivers a solid performance, particularly excelling in Thai-language benchmarks with the highest scores in GSM8K-TH and MATH-TH. It also performs competitively on English tasks, achieving 84.2% on GSM8K-EN. While Qwen2.5–7B-instruct and OpenThaiGPT-1.5–7B lead in specific metrics like **HumanEval (TH/EN) **and mbpp (TH),Typhoon2–7B-instruct demonstrates a well-rounded balance, highlighting its robust multilingual capabilities and strength in Thai-centric applications.
Large & Proprietary Models
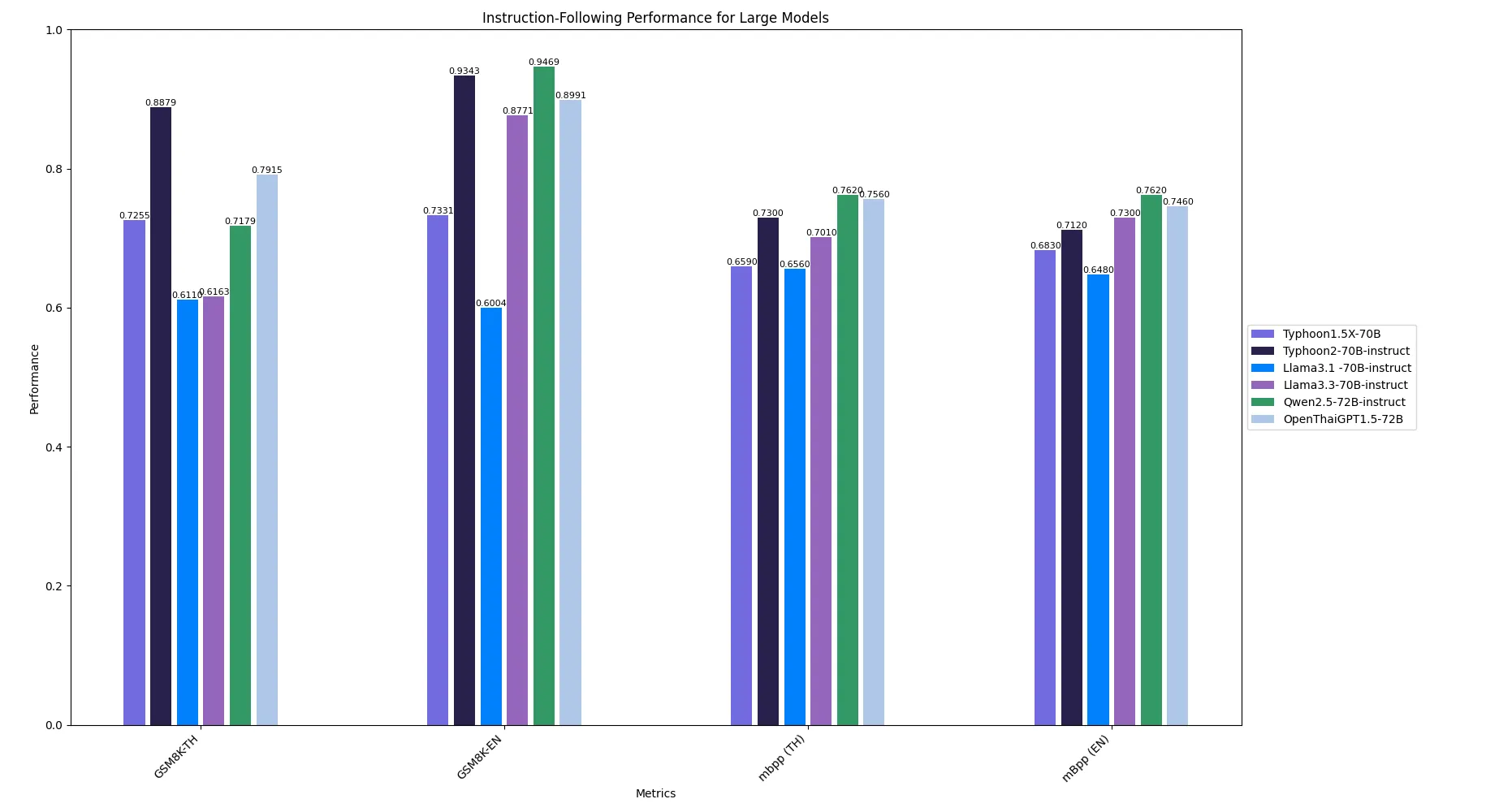
Large & Proprietary Model Specialized Task Performance
| Model | GSM8K-TH | GSM8K-EN | MATH-TH | MATH-EN | HumanEval (TH) | HumanEval (EN) | mbpp (TH) | mbpp (EN) |
|---|---|---|---|---|---|---|---|---|
| Typhoon1.5X-70B | 72.55% | 73.31% | 25.93% | 44.06% | 88.98% | 94.90% | 85.58% | 85.16% |
| Typhoon2-70B-instruct | 88.79% | 93.43% | 59.60% | 64.96% | 90.86% | 94.25% | 84.88% | 83.86% |
| Llama3.1-70B-instruct | 61.10% | 60.04% | 40.67% | 63.66% | 93.36% | 91.61% | 78.47% | 78.26% |
| Llama3.3-70B-instruct | 61.63% | 87.71% | 44.37% | 73.58% | 91.80% | 95.72% | 82.57% | 83.62% |
| Qwen2.5-72B-instruct | 71.79% | 94.69% | 47.91% | 83.10% | 93.58% | 94.38% | 86.00% | 84.20% |
| OpenThaiGPT1.5-72B | 79.15% | 89.91% | 43.65% | 81.80% | 92.53% | 91.98% | 85.04% | 83.17% |
Typhoon2 70B model demonstrates state-of-the-art performance in Thai-specific tasks like MATH-TH and HumanEval-TH, where it outperforms both Llama3.1–70B and rivals Qwen2.5–72B. Its scores on Math AVG and Code AVG confirm its exceptional ability to handle complex problem-solving and programming challenges in both Thai and English. These results position Typhoon2–70B as a leading open-source model for advanced educational and technical applications.
Long Context Performance
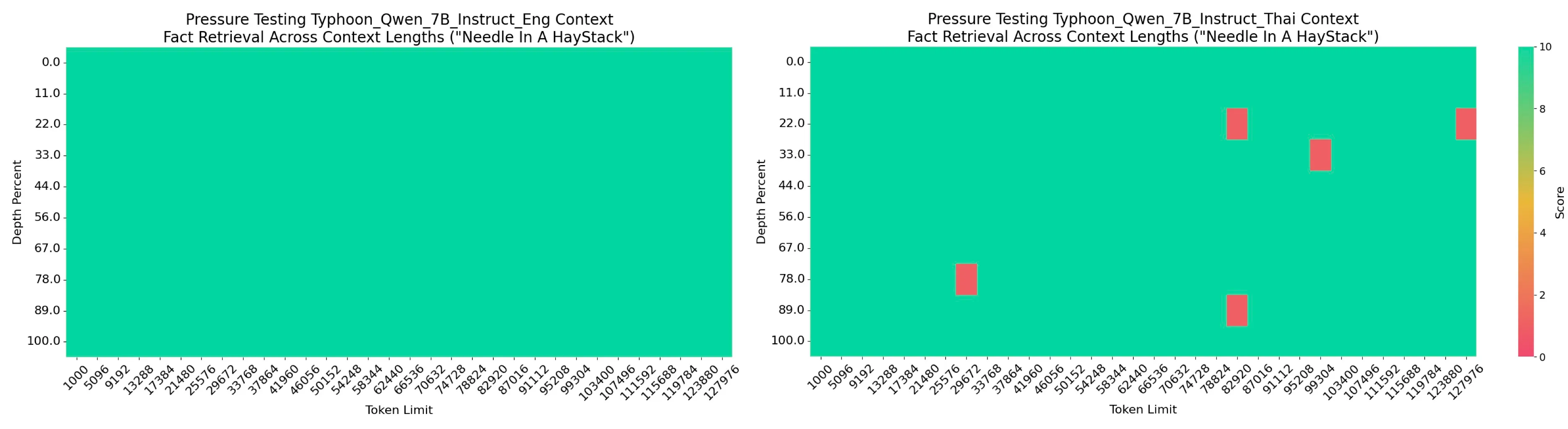
Typhoon2–7B Long Context Performance — English (Left) & Thai (Right)
Typhoon2–7B demonstrates exceptional long-context performance, as highlighted in its evaluation on the Needle-in-a-Haystack task for both English and Thai contexts. Supporting a maximum text length of 128,000 tokens, the model matches the original performance of Qwen2.5, despite being trained on shorter context lengths. This achievement underscores the model’s ability to effectively extrapolate to significantly longer contexts, surpassing the 32,768-token range and showcasing its robustness in handling extensive input sequences.
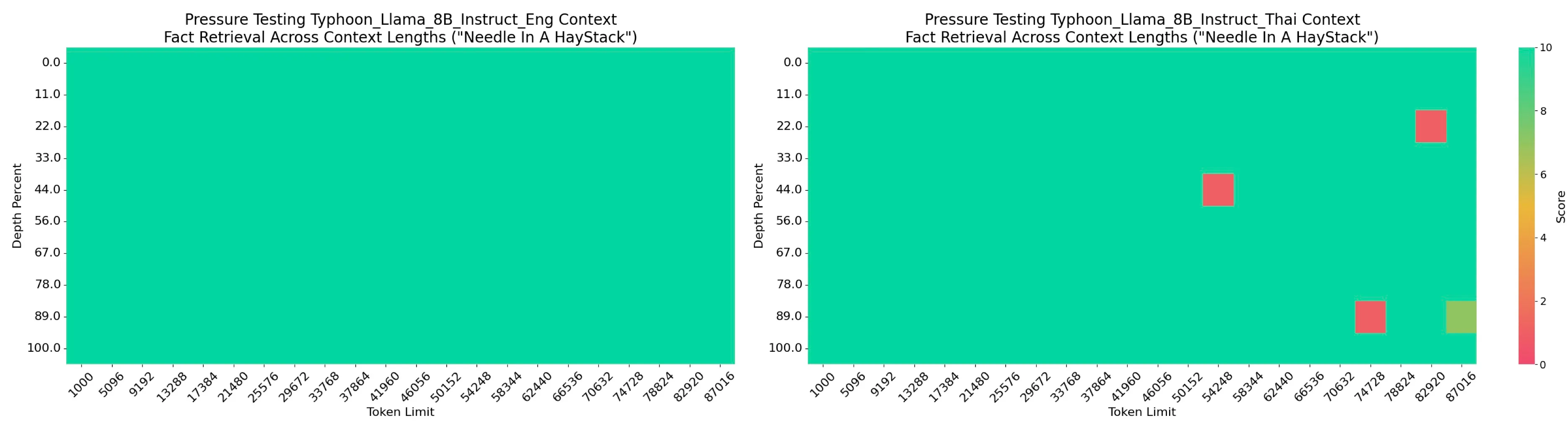
Typhoon2–8B Long Context Performance — English (Left) & Thai (Right)
The Typhoon2-Llama3.1–8B-Instruct model supports a maximum context length of approximately 90,000 tokens, a reduction compared to the original Llama 3.1 model’s support of 128,000 tokens. We hypothesize that this limitation is attributed to two key factors: (1) the incremental training approach of the original Llama 3.1 model, which progressively extended its context length to 128,000 tokens, and (2) the CPT approach’s restriction to a context length of 8,192 tokens, which limits the model’s ability to generalize to longer contexts despite adjustments to RoPE scaling.
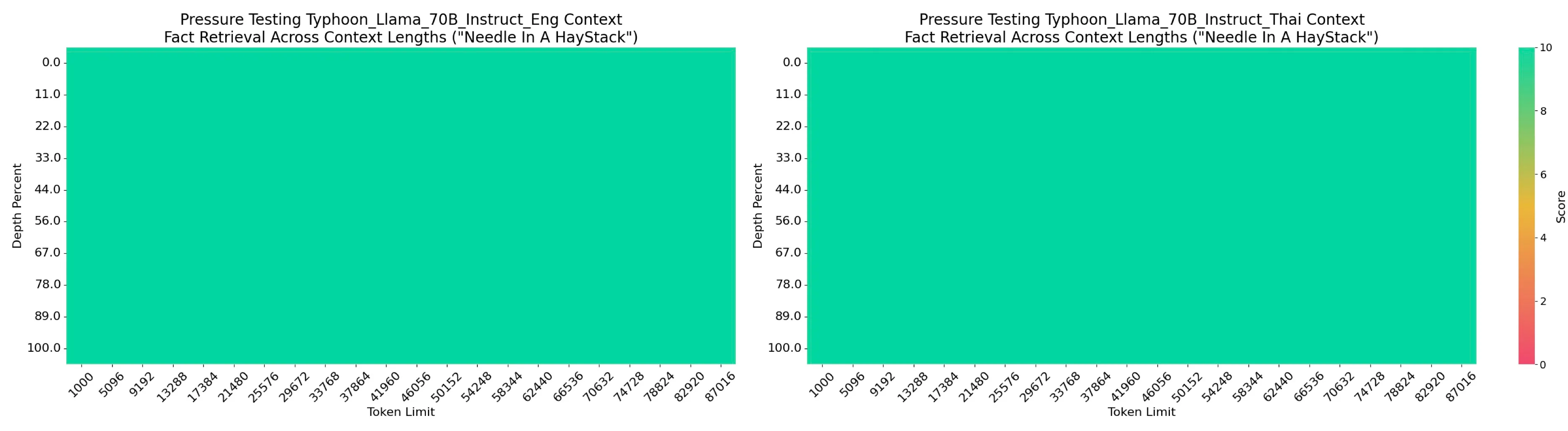
Typhoon2–70B Long Context Performance — English (Left) & Thai (Right)
Similarly, the Typhoon2-Llama3.1–70B-Instruct model also supports a maximum context length of approximately 90,000 tokens. Despite this reduction, it retains strong factual retrieval capabilities. Addressing these constraints in future iterations could unlock further improvements for the Llama-based Typhoon2 models, enhancing their adaptability to extended input sequences.
Continuing with Our Open Releases
With the goal of advancing Thai language technologies, this release includes model weights for 5 model sizes: 1B, 3B, 7B, 8B, and 70B, covering pre-trained and instruct versions.
All text model weights are released under open, commercially-permissive licenses. The 8B and 70B instruct models are also available through the Typhoon API at https://www.opentyphoon.ai. Our safety classifier will also be released under a commercially-permissive license.
We will also be releasing the weights for our audio and vision models under a research license.
Learn more about our methodology and insights by reading the Typhoon2 Technical Report, available at https://arxiv.org/abs/2412.13702
Future Work
We are exploring a range of potential directions to build on Typhoon 2’s current capabilities. These include enhancing support for diverse Thai language use cases (including dialects), improving multimodal functionalities, and exploring ways to make the models more adaptable across different domains and tasks.
As we look ahead, our focus remains on identifying opportunities to refine and expand Typhoon 2’s performance, ensuring it can better serve evolving needs in language understanding, speech, and real-world applications.
SCB 10X R&D Team
Kunat Pipatanakul, Potsawee Manakul, Natapong Nitarach, Warit Sirichotedumrong, Surapon Nonesung, Teetouch Jaknamon, Parinthapat Pengpun, Pittawat Taveekitworachai, Adisai Na-Thalang, Sittipong Sripaisarnmongkol, Krisanapong Jirayoot, Kasima Tharnpipitchai
Contact Us
- General & Collaborations: krisanapong@scb10x.com, kasima@scb10x.com
- Technical: kunat@scb10x.com
