

จากการเริ่มต้นในฐานะบริษัทที่ปรึกษาด้าน AI สู่การเป็นผู้พัฒนาเทคโนโลยีเต็มรูปแบบ VISAI กำลังสร้าง AI Projects และ Products หลายโครงการ หนึ่งในนั้นมุ่งเป้าไปที่ภารกิจอย่างการทำให้ความรู้ทางกฎหมายเข้าถึงได้ง่ายขึ้น
คุณภวิศภาคย์ อัครจรัสวงศ์, Senior Data Scientist ของ VISAI ได้มาร่วมแชร์ถึงเบื้องหลังและที่มาที่ไปของการพัฒนาเครื่องมือ AI ทางกฎหมายที่สร้างขึ้นภายในองค์กร ซึ่งไม่เพียงแต่มีประสิทธิภาพสูง แต่ยังถูกออกแบบมาให้เข้าใจภาษาและระบบกฎหมายไทยอย่างลึกซึ้ง พร้อมกันนี้ VISAI ยังลงทุนต่อเนื่องในทีมวิจัย NLP เพื่อเสริมความแข็งแกร่งให้กับวงการ AI ของไทย
รู้จัก Sommai และ Somsi: แชทบอทกฎหมายที่เข้าใจภาษาไทย
เพื่อทำให้วิสัยทัศน์นี้เป็นจริง VISAI ได้พัฒนา AI ผู้ช่วยตอบคำถามด้านกฎหมาย สองตัวคือ Sommai และ Somsi ซึ่งแต่ละตัวถูกออกแบบมาเพื่อแก้ปัญหาเฉพาะในบริบทกฎหมายไทย และทั้งสองก็ขับเคลื่อนด้วย Typhoon โมเดลภาษาไทยขนาดใหญ่ (LLM) ที่พัฒนาโดยคนไทย
Sommai: แชทบอทโอเพนซอร์สด้านกฎหมายการเงิน

Sommai เป็นโปรเจกต์โอเพนซอร์สที่พัฒนาโดย VISAI เพื่อช่วยให้ข้อมูลกฎหมายการเงินไทยที่ซับซ้อน โดยใช้ RAG (Retrieval-Augmented Generation) ซึ่งผสานระบบค้นหาข้อมูลกับโมเดล AI ในการสร้างคำตอบที่แม่นยำและมีบริบทเหมาะสม และมี Typhoon เป็น LLM หลักในการสร้างภาษา
สิ่งที่ทำให้ Sommai พิเศษคือการเปิดทุกส่วนของ Pipeline ให้เข้าถึง ตั้งแต่โค้ด frontend และ backend ไปจนถึงฐานข้อมูลกฎหมาย ทำให้นักพัฒนาและนักวิจัยสามารถนำไปต่อยอดได้อย่างอิสระ
การจัดเตรียมข้อมูล
ฐานความรู้ของ Sommai ประกอบด้วย กฎหมายการเงิน 35 ฉบับ ที่ดึงมาจากสำนักงานคณะกรรมการกฤษฎีกา และจัดเรียงในรูปแบบ JSON พร้อมฟิลด์ต่าง ๆ เช่น law_name, section_num, section_content และ reference
กระบวนการเตรียมข้อมูลอธิบายไว้โดยละเอียดใน บล็อกโพสต์นี้ และสามารถเข้าถึงชุดข้อมูลได้บน Hugging Face
ระบบ Retrieval และสถาปัตยกรรม
Sommai ใช้ระบบค้นหาแบบ 2 ชั้น โดยอิงจาก WangchanX-Legal-ThaiCCL-Retriever:
-
BGE M3-Embedding สำหรับเปรียบเทียบความใกล้เคียงเชิงความหมาย
-
BGE-Reranker-V2-M3 สำหรับจัดอันดับเอกสารตามความเกี่ยวข้องทางกฎหมาย
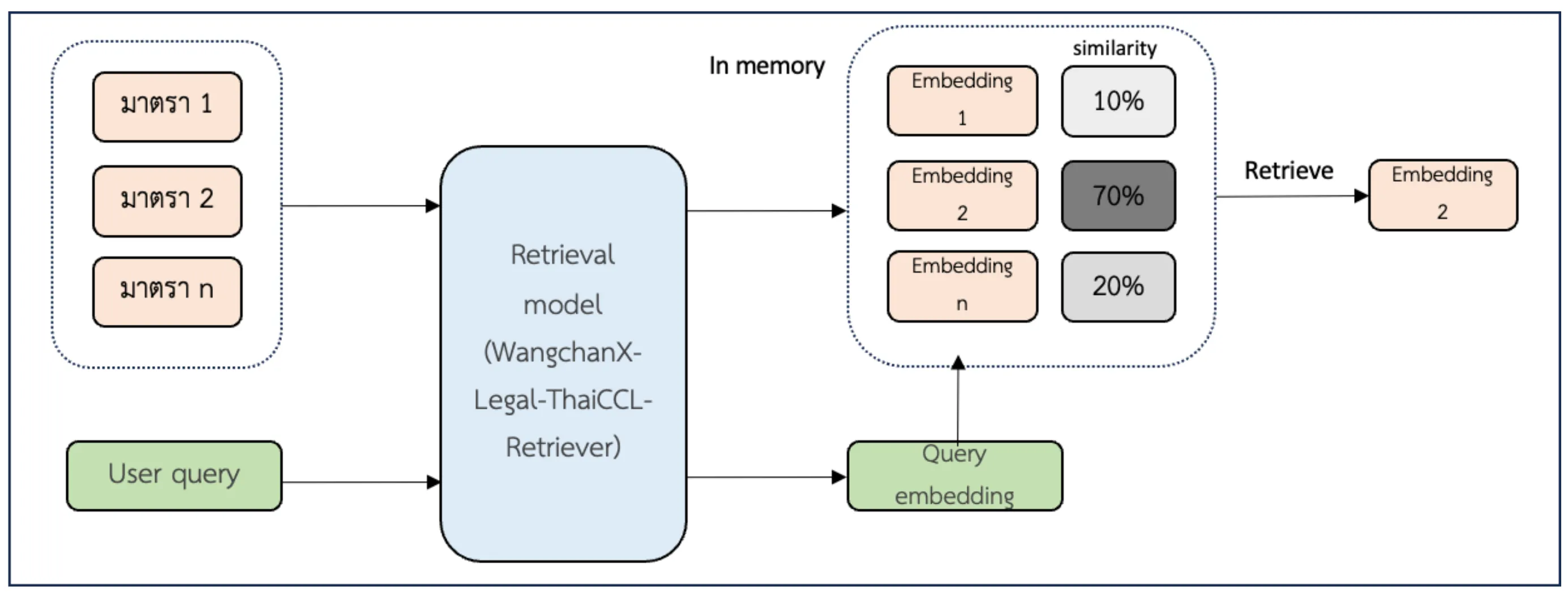
ระบบทั้งหมดทำงานผ่าน Kubernetes-based modular architecture ซึ่งแบ่งเป็นหลายองค์ประกอบ เช่น อินเทอร์เฟซฝั่งผู้ใช้, บริการฝังข้อมูลและดึงเอกสาร, ตัวควบคุม RAG, LLM engine และ Web gateway
การ deploy ใช้ vLLM เพื่อให้ Typhoon ทำงานได้รวดเร็ว และใช้ LlamaIndex สำหรับ ingest เอกสารกฎหมาย โดยใช้ vector database แบบ in-memory เพื่อความเร็วและลดความซับซ้อน อ่านรายละเอียดเพิ่มเติมได้ที่ บทความเชิงเทคนิค และที่ GitHub ของ VISAI
การเอา Typhoon LLM มาใช้
เราลองใช้ LLM หลายตัว รวมถึง LLaMA 3 และ Qwen แต่ Typhoon ให้ผลลัพธ์ที่ดีที่สุด ทั้งในด้านคุณภาพภาษาและความเข้าใจในโครงสร้างภาษากฎหมายไทย
– ภวิศภาคย์ อัครจรัสวงศ์, Senior Data Scientist ของ VISAI
Typhoon ได้รับการ continued pretraining (CPT) ด้วยข้อมูลภาษาไทยคุณภาพสูง ทำให้เข้าใจภาษาทางการและเทคนิคเฉพาะอย่าง “ภาษากฎหมาย” ได้ดีกว่าโมเดลอื่น
ลองใช้งาน Sommai ได้ที่ sommai.wangchan.ai

รูปที่ 2. หน้าจอ Playground โดยมีโมเดลของ Typhoon อย่าง llama3-typhoon-instruct-70b เป็นโมเดลมาตรฐานเริ่มต้น

รูปที่ 3. Sommai ตอบคำถามกฏหมายที่เกี่ยวกับการเงิน เช่น “บริษัทไม่หัก ณ ที่จ่ายได้ไหม”
Somsi: แชทบอทเฉพาะทางสำหรับกฎหมายภาษี
Somsi คืออีกผลงานที่มุ่งตอบคำถามเกี่ยวกับ กฎหมายภาษีของไทย ถูกออกแบบให้ใช้งานได้จริงทั้งในองค์กรและแบบ on-premise โดยคำนึงถึง ความเร็ว ความเสถียร และความปลอดภัยของข้อมูล ความท้าทายคือ ทำอย่างไรให้แชทบอทตอบได้แม่นและเร็ว ในระบบที่มีทรัพยากรจำกัด
ผลลัพธ์คือ Somsi ที่ใช้ Typhoon เช่นกัน และให้ผลตอบรับดีที่สุดในกลุ่มโมเดลภาษาไทยที่ VISAI ทดลอง VISAI ยังวางแผน post-train Typhoon ด้วยข้อมูลกฎหมายภาษีเฉพาะทาง เพื่อยกระดับความแม่นยำในการตอบคำถามภาษีไทยให้สูงยิ่งขึ้น
ลองใช้งาน Somsi ได้ฟรีที่ somsi.visai.ai

รูปที่ 4. Somsi ตอบคำถามเกี่ยวกับอากรแสตมป์

รูปที่ 5. ตัวอย่างคำถามกฏหมายภาษีที่ Somsi สามารถช่วยให้ข้อมูลได้
VISAI กับการส่งเสริมงานวิจัยที่ผลักดัน NLP ภาษาไทย

เบื้องหลังการพัฒนาแชทบอท VISAI ยังทำงานวิจัยเชิงลึกด้าน NLP ภาษาไทย โดยเฉพาะในบริบทกฎหมาย หนึ่งในผลงานสำคัญคือ NitiBench ชุด benchmark ที่ใช้วัดประสิทธิภาพของ LLM บนงานด้านกฎหมายไทย
VISAI ใช้ Typhoon ถึงสองบทบาทหลักของงานวิจัยนี้:
-
เป็น baseline สำหรับเปรียบเทียบกับโมเดลอื่น
-
เป็นแพลตฟอร์มสำหรับการ post-training เพื่อดูว่า LLM ปรับตัวกับข้อมูลกฎหมายเฉพาะทางได้ดีแค่ไหน
VISAI แชร์เหตุผลที่เลือกใช้ Typhoon ว่าเป็นเพราะเวลาในการเทรนที่ไวกว่าโมเดลตัวอื่นๆ รวมถึง performance หลังการเทรนดีขึ้นกว่าตัวอื่น ประกอบกับเป็น LLM ภาษาไทยจึงทำให้มี Performance ที่ดีกว่า LLM ที่เป็น General Purpose อย่างเช่น Qwen2.5, Llama3, 3.1
งานวิจัยนี้ช่วยให้ได้ Insight ที่ดีในการทดลองบน Typhoon ทำให้รู้เกี่ยวกับการทำ Domain Adaptation ได้มากขึ้น และรู้ข้อจำกัดของ LLM ภาษาไทยในปัจจุบัน ทั้งนี้ทาง VISAI มีแผนการต่อยอดทำการทดลองในหัวข้ออื่นๆ โดยยังใช้ Typhoon เป็นหนึ่งในตัวเลือกต่อไป
ดูรายละเอียดงานวิจัยได้ที่ arXiv
ฝากถึงนักพัฒนาและผู้สร้าง AI ในไทย
ในโลกที่โมเดล AI จากต่างประเทศพัฒนาเร็วขึ้นทุกวัน VISAI อยากส่งข้อความหนึ่งไปยังผู้พัฒนาในไทย
ถึงแม้ว่าในปัจจุบันจะมี Proprietary LLM ที่เก่งๆ ออกมาอย่างต่อเนื่อง แต่ในหลาย Use Case เช่นการทำ on-premise หรือโจทย์ที่เป็น Specific Domain เช่นกฎหมายไทย การที่เรามี LLM ที่สร้างโดยคนไทย มีความรู้ความเข้าใจในภาษาไทยเฉพาะกว่าโมเดลเจ้าอื่นๆ และมีขนาดที่ไม่ใหญ่เกินไป และปล่อยเป็น Open Source ให้ใช้ฟรีๆ ก็ทำให้เราในฐานะ Developer สามารถสร้าง Product และ Solution ที่ดีขึ้นได้ครับ

– ภวิศภาคย์ อัครจรัสวงศ์ Senior Data Scientist ของ VISAI
Typhoon ไม่ใช่แค่โมเดลที่ทำงานได้ดี แต่ยัง ถูกออกแบบให้เหมาะกับบริบทไทย ทั้งในแง่ขนาด ประสิทธิภาพ และความเข้าใจในภาษาและวัฒนธรรม สำหรับนักพัฒนา นักวิจัย หรือเจ้าของผลิตภัณฑ์ในประเทศไทย นี่คือโอกาสในการ สร้างสิ่งใหม่โดยไม่ต้องพึ่งพาระบบของคนอื่น
VISAI เชื่อว่าการลงทุนในเทคโนโลยีที่คนไทยสร้างเอง เช่น Typhoon คือการกำหนดอนาคตของวงการ AI ไทย ไม่ใช่แค่ตามทันโลก แต่สร้างแนวทางของเราเอง

