

We are very excited to introduce our new model series “Typhoon T”, which “T” stands for thinking. Typhoon T is able to think longer before giving a final answer. This approach improves the model’s performance on math, code, and challenging benchmarks.
In this iteration, we release **Typhoon T1 3B (Research Preview), **a small but performant model. Typhoon T1 3B (Research Preview) is built on top of Typhoon 2 3B Instruct, our latest iteration of Typhoon text generation models.
By applying our long thought data and training recipe to Typhoon 2 3B Instruct, we have pushed the model further on challenging benchmarks, including GPQA, MMLU Pro, and the AI Mathematical Olympiad validation set. Unlike many open reasoning models, Typhoon T1 3B (Research Preview) is able to generate long chains of thought across domains, not only in mathematics and coding.
- 💻 Demo: Online demo
- 🤗 Dataset (Typhoon T1 3B Research Preview Data): typhoon-t1-3b-research-preview-data
- 🤗 Model weights (Typhoon T1 3B Research Preview): llama-3.2-typhoon-t1–3b-research-preview
Key Points
- Typhoon T is a new family of open reasoning models developed by SCB 10X R&D
- **Typhoon T1 3B (Research Preview), **the first in the Typhoon T family, shows improved performance across challenging benchmarks compared to the original Typhoon 2 3B Instruct
- Typhoon T1 3B (Research Preview) offers a fast, low-compute requirements model, yet is capable in a variety of tasks by scaling test-time compute, enabling the model to think longer before giving a final answer. Typhoon T1 3B (Research Preview) is able to reason across domains, unlike many open reasoning models limited to mathematics and coding
- We open our recipe for data pipeline and training this model without distilling from other reasoning models
- We introduce a new thinking paradigm for reasoning models, structured thinking, where we add auxiliary tokens to help structure the thinking process of the model. This approach shows an increase in performance over a common variant of separating only thought and response parts based on our experiments
Reasoning Models
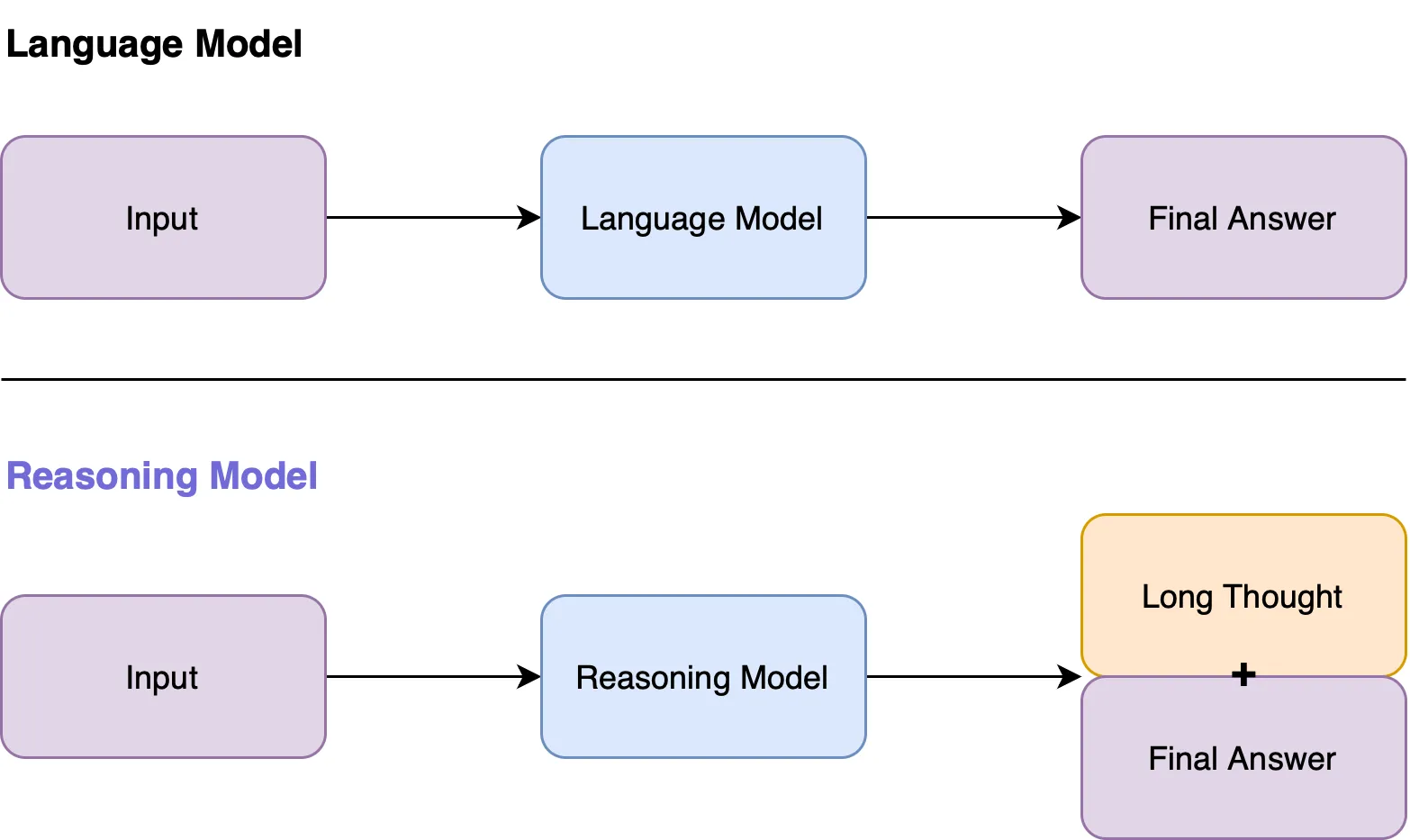
Recently, there have been various introductions of both proprietary and open-weight reasoning models, for example, OpenAI’s o1, Qwen QwQ, and DeepSeek’s r1. A reasoning model is a new advancement in large language models that falls into the category of test-time compute or inference-time scaling, enabling the model to think longer via reasoning steps before giving a final answer. This approach has greatly enhanced models’ performance, especially in challenging tasks. Not only that, but thinking traces also increase transparency by showing the thoughts of the models leading up to the final answer.
Nevertheless, information on the exact recipe for training this paradigm of models is obscure, and only speculations are floating around. In contrast to many existing reasoning models, **Typhoon T1 (Research Preview) **aims to accelerate research in this field. We open the weights of our models along with the recipe for how we developed Typhoon T1 (Research Preview).
Enabling a Small Language Model to Think Longer
We take an alternative approach by starting with smaller sizes of LMs, in contrast to the typical size of open-weight reasoning models like Qwen’s or Sky’s reasoning models at 32B. Small language models are often enablers in cases where computational constraints are crucial, like edge deployment or privacy-preserving on-device inference, where utilizing larger variants of language models is impractical.
Furthermore, our approach does not involve distilling from other reasoning models. While distillation often results in high-performing models in a short period of time, it is also associated with various limitations, including performance being upper-bounded by the performance of the teacher model, and it requires a teacher model to exist before starting the distillation process. By researching our own approach, we can learn various insights to further improve our models without the said limitations.
The overall process of our approach in developing a small thinking model in this iteration is quite simple, yet effective. First, we prepare a long thought dataset using few-shot prompting. After that, we supervised fine-tune the Typhoon 2 3B Instruct on the generated dataset. We dive deeper into the details in the following sections.
Data Preparation
We prepare a dataset for supervised fine-tuning by selecting existing open datasets mainly in instruction following, mathematics, and code domains for augmenting with structured long thought format. We utilize a strong large language model to generate a structured long thought. After that, we instruct Qwen2.5 32B Instruct to refine the generated thought into a better output. We discuss more details in the following subsections.
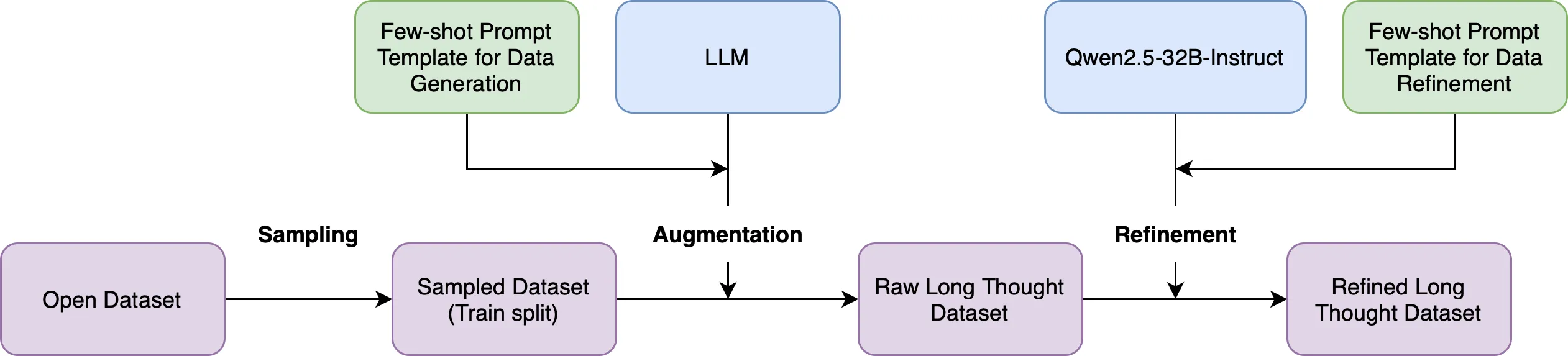
Data preparation flow
Why Structured Long Thought?
Before we go into more details on our data pipeline, we would like to introduce the concept of structured long thought. Structured long thought is a concept where we provide an explicit structure through XML tags for the model to fill in existing information for each thinking structure. Our structured long thought consists of planning and thinking steps, and each thinking step includes a scratchpad as a space for the model to further think or plan.
This approach is different from existing approaches in reasoning models where models either generate long responses without clear separation between thought and final answer, or have less structure where only thought and response are separated without specifying what each step in thinking should be. Through our empirical experiments, it shows that this approach is more effective than separating only thought and response for our scenario (see the table in Performance section).
An example of structured long thought when prompted with “A model of a park was built on a scale of 1.5 centimeters to 50 meters. If the distance between two trees in the park is 150 meters, what is this distance on the model?” (temperature = 0). Indentation is manually added for ease of reading.
Our structured long thought approach is heavily inspired by existing prompt engineering approaches where plan-and-solve prompting showed that asking a model to plan improves their chain-of-thought, in other words, reasoning. In addition, providing a space for models to think, like a scratchpad, showed some promising directions. We also have the model summarize its actions done in each step to confirm what was done at each step before generating the next step, where in some cases it may be necessary to deviate from the pre-generated plan. To provide a clear structure, XML tags were arbitrarily selected to be used for structuring elements.
Data Sourcing
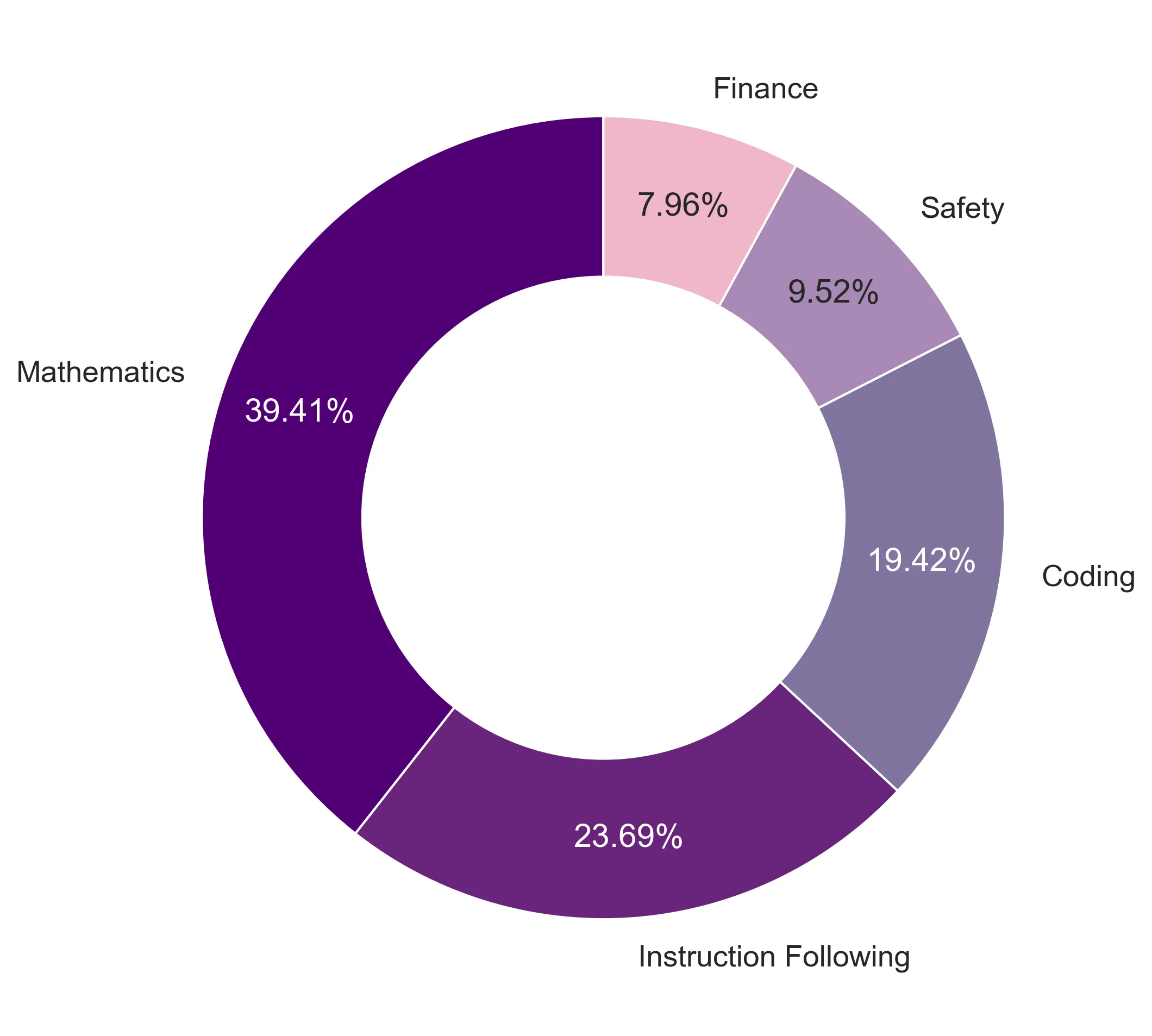
We source data from open datasets in five domains:
- Mathematics: (1) Tulu 3 SFT Math Grade, (2) o1-journey, (3) PRM800K Phase 1 & 2, and more
- Instruction following: (1) ultrafeedback and (2) no_robots
- Coding: (1) evol-codealpaca, (2) Tulu 3 SFT Code
- Safety: (1) HelpSteer
- Finance: (1) wealth
For large datasets, we downsample from the train split to a manageable size suitable for our model size. In addition, we filter only high-quality records from ultrafeedback by removing any records with a rating lower than 4.25 and responses that are too short, and post-process PRM800K to reformat it into an instruction format.
Data Generation
We generate long thoughts for each data record by few-shot prompting a strong large language model (LLM) to generate an English long thought, given that we provide a ground truth or draft. Alternatively, we can view this as asking a model to fill in the middle on how to reach a final answer (thoughts). We found that only three high-quality long-thought exemplars used for few-shot prompting are enough for the LLM to generate long thoughts. We hand-curated all the exemplars with LLM assistance and made them publicly available here: few-shot exemplars.
Data Refinement Using an LLM
Nevertheless, generated data are imperfect; for example, sometimes tags used for structuring may be missing, or some content may be missing. While traditional post-processing pipelines may be able to fix some of the issues, they are not enough and often cumbersome to implement. Therefore, we utilize an LLM, specifically, Qwen2.5–32B-Instruct, and prompt it to be our data refinement expert.
The prompt instructs the model to correct formatting issues, such as missing tags, incorrect tag names, or incorrect order. We also instruct this model to fill in content that may be missing and further improve response quality by taking into account the generated thoughts. In order to help the model, we also provide the same few-shot exemplars in the prompt. After this step, our data is ready to be used for supervised fine-tuning.
We note that all deployment of LLMs used for the data pipeline is done through vLLM for efficient inference. Our final dataset contains 55,677 records. This translates to over 67M tokens with an average of 145 tokens for the instruction and 1,060 tokens for the output. The data mixture shown in the figure below:
On average, the number of reasoning steps in the dataset is approximately 4–5 steps. The maximum number of steps in the datasets is 24. This shows the generalizability of the data generation approach, which dynamically determines the difficulty of the instruction and thinks longer when necessary.
Supervised Fine-Tuning
We apply standard full supervised fine-tuning to fine-tune our model on the long thought datasets. We train for two epochs using a learning rate (LR) of 2e-5 with a Cosine LR scheduler. We also utilize Flash Attention 2 and Liger kernel for efficient training. Training is done using LLaMA-Factory.
Performance
We evaluate Typhoon T1 3B against its base model, Typhoon 2 3B Instruct, and its variant Typhoon T1 3B (semi) trained on a dataset without auxiliary tags in <thought> sections. We evaluated all of the models using the following benchmarks:
- GSM8K: Grade-school math word problem benchmark
- HumanEval+: Robust coding evaluation benchmark
- GPQA: Graduate-level Google-proof QA benchmark
- AIME: Competition-level challenging mathematics benchmark
- MMLU Pro: Robust challenging reasoning-focused multiple-choice QA benchmark
| Model name | GSM8K (↑), 8-shot | HumanEval+ (↑), Pass@10 | GPQA (↑), 0CoT | AIME (↑) |
|---|---|---|---|---|
| Typhoon 2 3B Instruct | 56.63 | 66.00 | 27.01 | 0.00 |
| Typhoon T1 3B (semi) | 59.59 | 68.99 | 25.89 | 0.00 |
| Typhoon T1 3B | 62.40 | 69.87 | 31.70 | 2.22 |
MMLU Pro (↑), 5-shot
| Model name | Average | Math | Health | Physics | Business | Biology | Chemistry | Computer Science | Economics | Engineering | Philosophy | Other | History | Psychology | Law |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Typhoon 2 3B Instruct | 26.70 | 26.80 | 33.62 | 23.40 | 25.35 | 43.38 | 19.88 | 28.29 | 35.43 | 18.37 | 28.06 | 27.92 | 25.72 | 37.84 | 13.17 |
| Typhoon T1 3B | 30.65 | 30.57 | 36.19 | 27.01 | 31.69 | 50.77 | 22.17 | 31.22 | 38.86 | 21.98 | 30.66 | 32.79 | 26.51 | 43.36 | 17.26 |
We observed increases in performance of Typhoon T1 3B across mathematics, coding, graduate-level Google-proof QA, robust language understanding, and very challenging competition-level mathematics. The observed increases in performance also correspond to a higher number of output tokens. For example, Typhoon 2 3B Instruct has an average number of output tokens at 191.95 tokens, while Typhoon T1 3B has an average number of output tokens at 344.80 tokens when tackling MMLU Pro. We evaluate our model using an open-source standard evaluation suite, olmes, except for AIME, for which we use our internal evaluation platform.
As shown in the first table, we also found that stripping all auxiliary tags in the thoughts section decreases performance increment, and even decreases performance from the base model on one benchmark. We also found that although there was no explicit training data on subjects in MMLU Pro, for example, biology, chemistry, and economics, we observed improved performance on all subjects. This likely indicates that improving model’s long thinking capabilities in specific domains like math and code also helps improve the model in other domains.
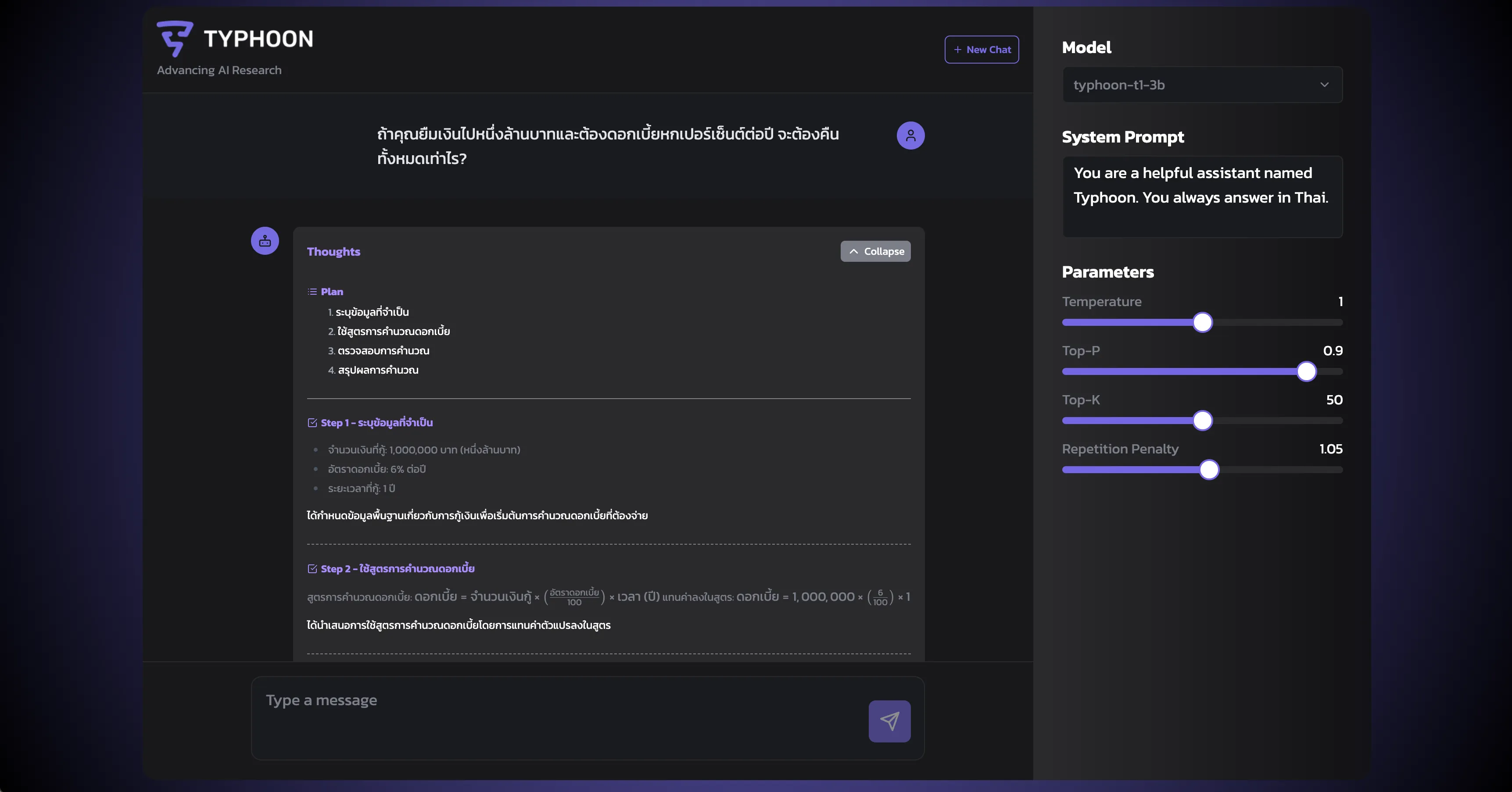
Although this model wasn’t fine-tuned on any Thai long thought data, we observed that in rare cases, our model is able to generate long thoughts in Thai. Using the following prompt: “ถ้าคุณยืมเงินไปหนึ่งล้านบาทและต้องดอกเบี้ยหกเปอร์เซ็นต์ต่อปี จะต้องคืนทั้งหมดเท่าไร?” at temperature = 1.0, top-p = 0.9, we got the following response:
Potential Limitations of Typhoon T1 (Research Preview)
Currently, Typhoon T1 is in the research preview stage, and as a result, it has some limitations. The model may respond to simple requests, such as greetings, with multiple steps of thinking before answering, which may not be ideal. While Typhoon T1 supports multi-turn conversations, we did not explicitly train the model on a multi-turn training set. Therefore, the model may exhibit unexpected behaviors during extended conversations. Additionally, since Typhoon T1 is a relatively small model at 3B parameters, some of its behaviors may be constrained by its inherent capabilities due to its size, such as getting stuck in a reasoning loop.
Future Work
We plan to further scale our approach to larger parameter sizes, which would provide higher capabilities. We also plan to explore how to transfer long thought capabilities from English to Thai. Another obvious direction is extending to additional tasks with improved reasoning. In this iteration, we only explored supervised fine-tuning; however, recent literature and research show the effectiveness of other post-training approaches like RLHF, which we plan to explore further.
Disclaimer
While we made an effort to make our model safe, like all generative models, it may generate unsafe content in rare cases. Introducing a reasoning model paradigm may introduce some unforeseen behaviors, as model safety in the reasoning domain is a relatively new and ongoing area of research.
Connect With Us
- Follow us on X (Twitter)
- Join our Discord Server for support or to showcase your projects!
- Sign up and explore our hosted models at OpenTyphoon Website
Contact Us
- General & Collaborations: krisanapong@scb10x.com, kasima@scb10x.com
- Technical: kunat@scb10x.com

