

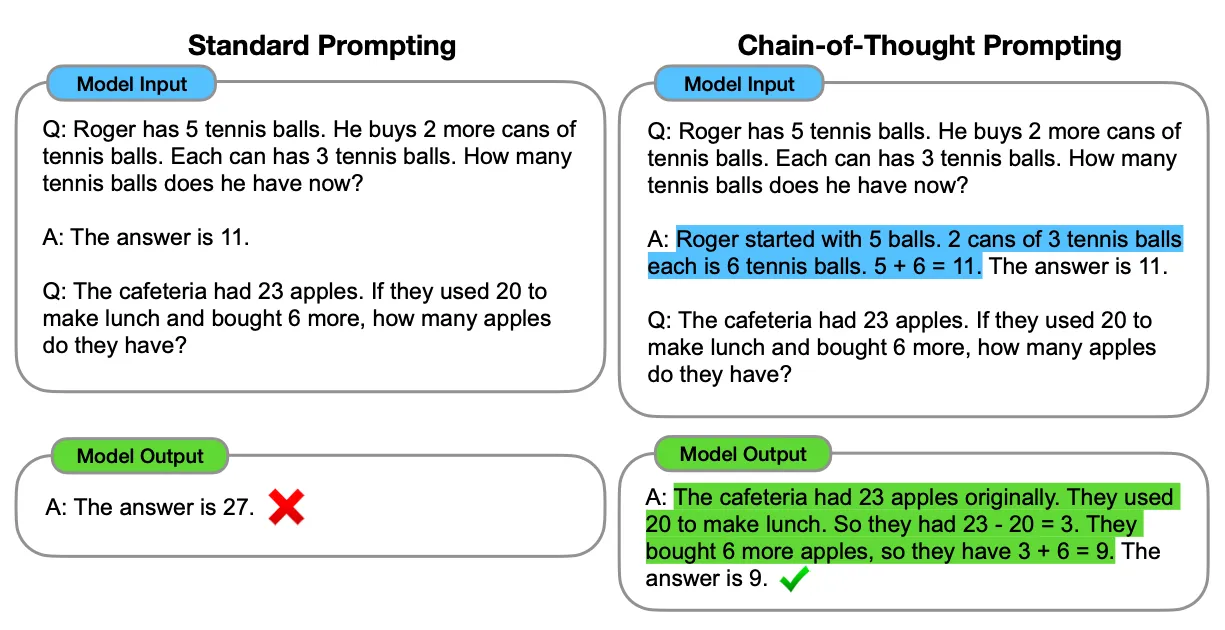
As humans, we don't always respond to situations instantly. Sometimes, we take a moment to process information, considering the full context before giving a well-thought-out answer.
In contrast, most large language models (LLMs) operate in a rapid-response manner, often prioritizing speed over depth.
While techniques like chain-of-thought prompting [1] encourage LLMs to think step by step, they still fall short of providing sufficient reasoning time to generate truly high-quality responses.
Reasoning models have taken the world by storm, marking a significant leap forward in the advancements of LLMs. A reasoning model is a specialized LLM
designed to spend more time thinking during inference by generating thinking tokens before providing a final answer. Notable models in this category include OpenAI's o-series, DeepSeek R1, Claude 3.7 Sonnet with Extended Thinking,
Typhoon T1, and Typhoon R1.
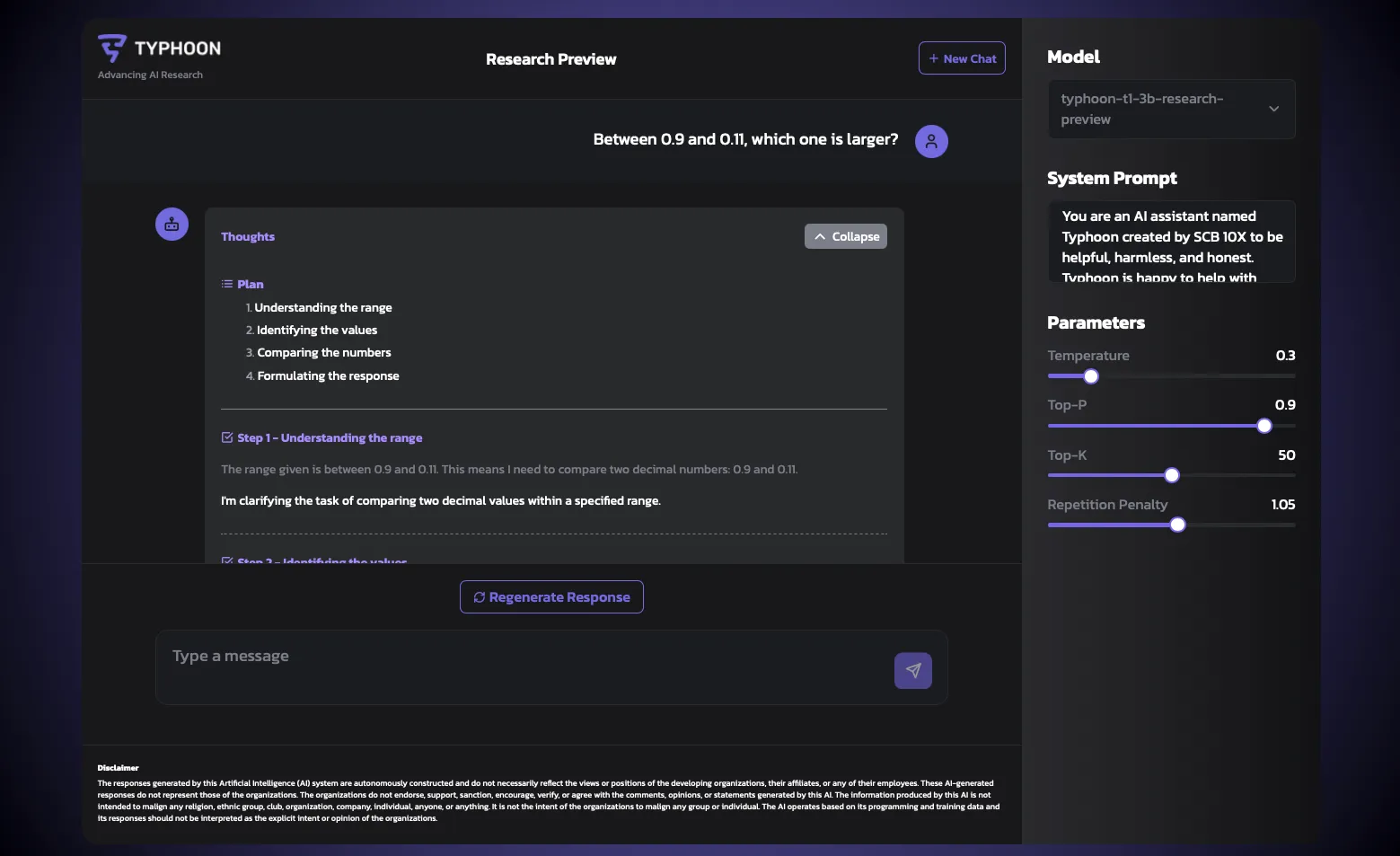
Typhoon T1
However, details on how to train such models remain obscure. OpenAI, for instance, has not released specific details
regarding the development process of its o-series models, except for mentioning the use of large-scale reinforcement learning (RL).
DeepSeek R1 provides more details on its RL pipeline, but not at a level that makes reproduction feasible due to missing many pieces of information. Various open-source and research communities are attempting to replicate these results, shedding light on different aspects of reasoning model development. However, the available details are scattered and incomplete.
In this article, we will explore the latest developments in reasoning model development. We will examine different approaches from various perspectives in developing reasoning models and discuss the latest insights. Finally, we will summarize future trends and what we can expect moving forward.
How to Develop Reasoning Model?
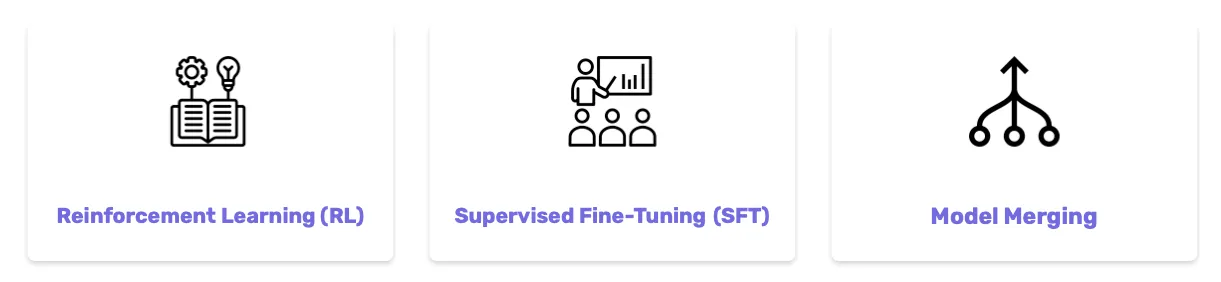
While RL dominates as the primary method for achieving a reasoning model, various alternative approaches have emerged. In summary, the three main paradigms for developing a reasoning model are:
Three Main Approaches to Develop Reasoning Models:
-
Reinforcement Learning (RL): This approach starts without a pre-existing reasoning model, allowing the model to explore and develop useful thinking patterns autonomously through the RL process.
-
Supervised Fine-Tuning (SFT): This method treats reasoning as a skill or pattern that can be explicitly taught to a model. It can be divided into two main approaches:
2.1 Knowledge Distillation: Leveraging existing reasoning models as teacher models, a smaller student model is trained on the teacher's generated predictions. This enables efficiency but is limited to existing reasoning patterns.
2.2 Data Augmentation: Creating structured long-form reasoning data from scratch, independent of existing reasoning models, and training a model on these synthetic datasets.
-
Model Merging: This approach combines multiple models to achieve enhanced performance. The core idea is that different models possess distinct sets of skills and knowledge, and merging them enables access to a broader range of capabilities.
Typhoon has released Typhoon T1, utilizing the data augmentation approach, and Typhoon R1, employing model merging. We are actively exploring RL-based methods, as well as improvements to existing models.
| Approach | Details | Pros | Cons |
|---|---|---|---|
| Reinforcement Learning (RL) | Model learns autonomously through reinforcement learning processes. | Can uncover unconventional reasoning methods. | Uncontrollable reasoning patterns, resource-intensive, potential inefficiencies. |
| Supervised Fine-Tuning (SFT) | Training a model on structured reasoning data. | Lower resource consumption, strong starting point for RL. | Limited to existing reasoning patterns, requires structured training data. |
| Knowledge Distillation | Student model learns from an existing reasoning model. | Fast way to achieve high performance. | Limited by the reasoning patterns of the teacher model, requires a pre-existing reasoning model. |
| Data Augmentation | Creating synthetic structured reasoning data for training. | Enables controlled thought processes. | The field is underexplored and requires further research. |
| Model Merging | Combining multiple models to enhance reasoning performance. | Efficient and quick performance enhancement. | Requires further research and optimization. |
Let's deep dive into each approach!
Approach 1: Reinforcement Learning

Reinforcement learning (RL) is a well-established field that has existed for a long time.
Traditional RL focuses on building an agent that can optimally act autonomously within an environment to achieve a goal by maximizing a reward.
Applying RL to LLM training is not foreign. Reinforcement learning with human feedback (RLHF) [2] is a training paradigm proposed by OpenAI to align LLM behavior with human preference through the use of an outcome reward model.
1.1 RLHF
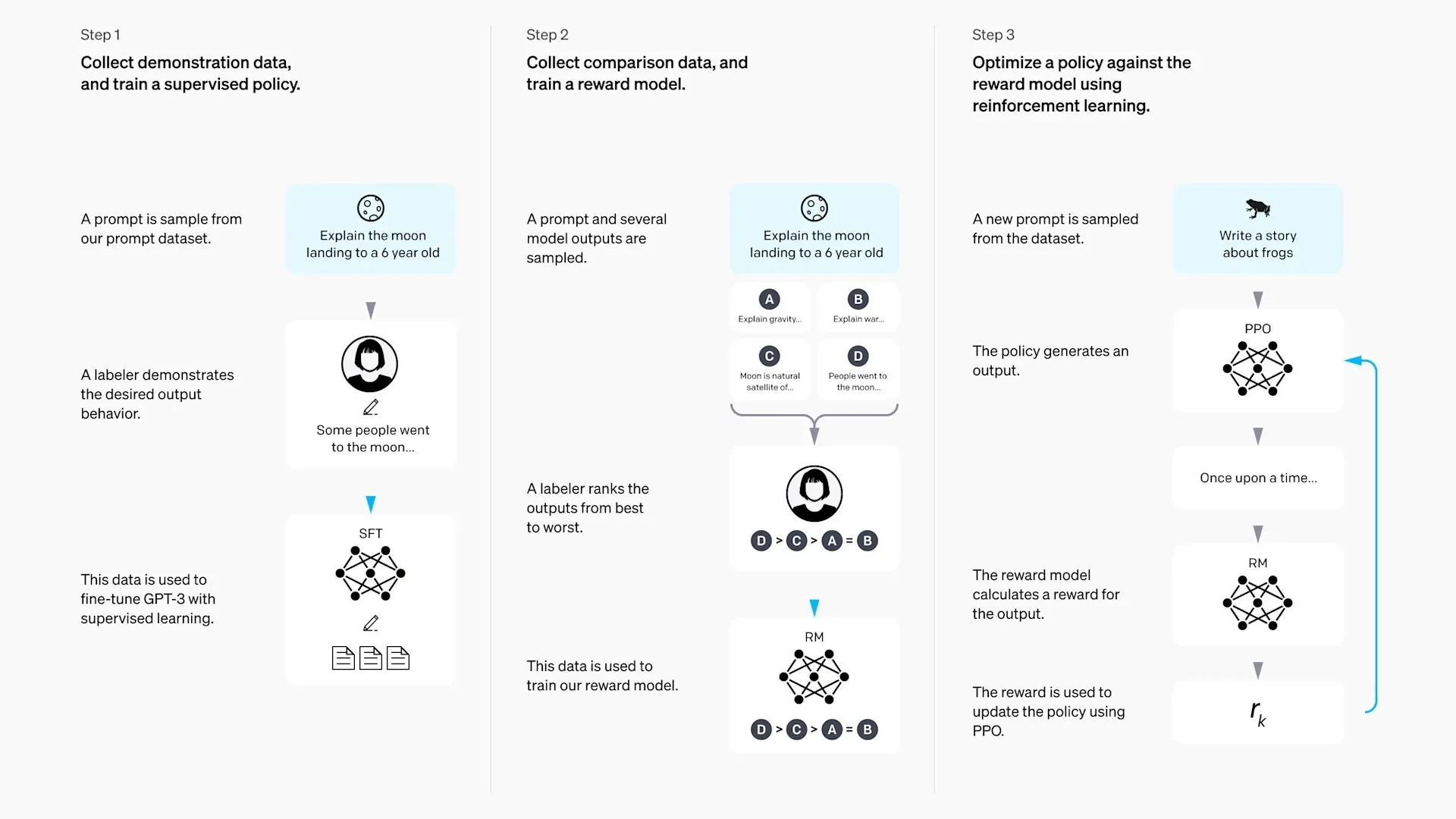
RLHF demonstrates the feasibility of training large language models using RL. It guides models to generate more aligned responses by assigning higher preference scores to preferred responses while penalizing those that are disfavored.
In this approach, the entire generated text is considered an action, and the reward is sparse, given only after the complete response is generated. However, this method has two significant drawbacks.
Drawbacks of RLHF:
First, it requires the existence of an outcome reward model, and collecting human preference data is expensive and resource-intensive. Additionally, the reward model must be available during the training process, increasing computational demands.
Second, RLHF focuses primarily on aligning the model's responses with human preference, thereby enhancing user experience, but it does not necessarily improve the model's performance or reasoning capabilities.
1.2 RLVR
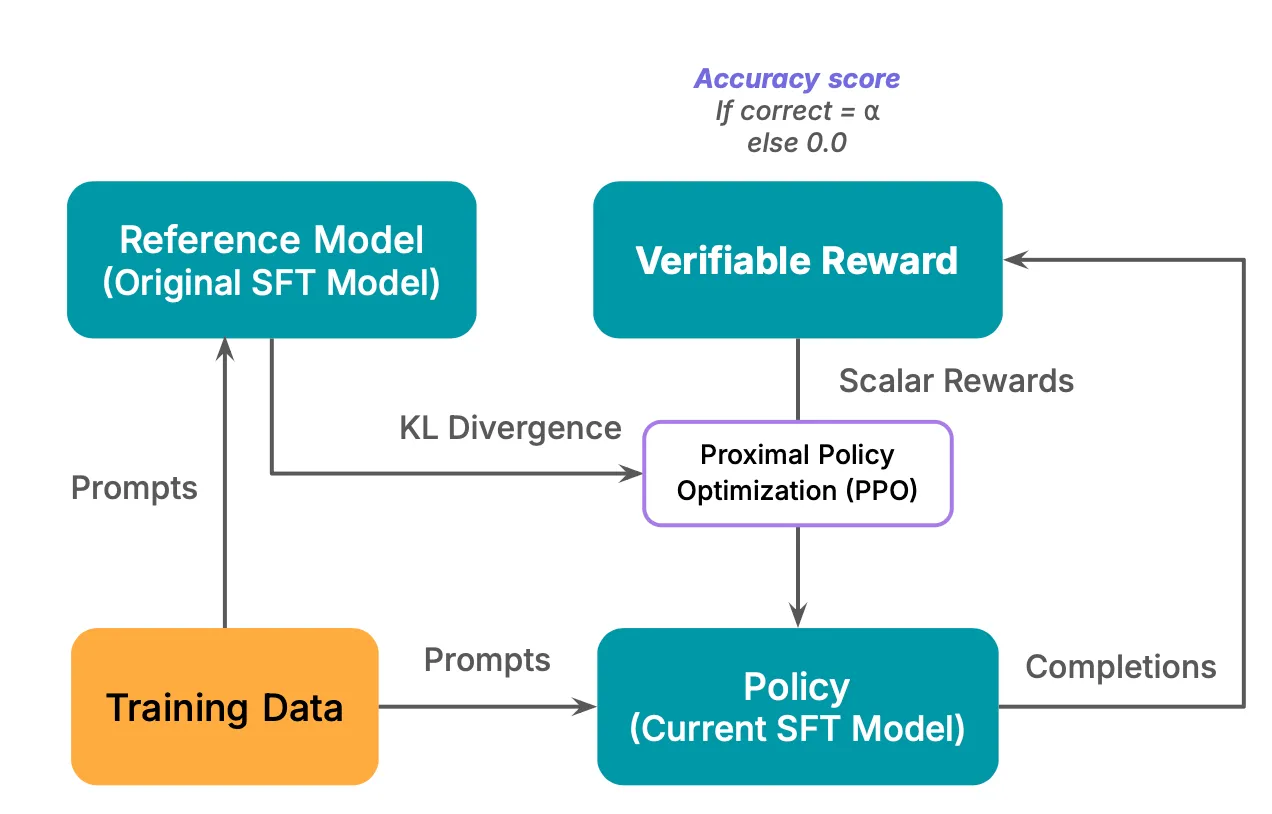
Reinforcement learning with verifiable rewards (RLVR), introduced by Lambert et al. [3],
addresses these limitations. Instead of relying on a learned reward model, RLVR replaces it with a verifiable reward mechanism.
The main objective of RLVR is to enhance model performance rather than merely aligning responses with human preferences. Importantly, RLVR does not replace RLHF but complements it by serving a different purpose, and the two approaches can be used together to achieve distinct goals.
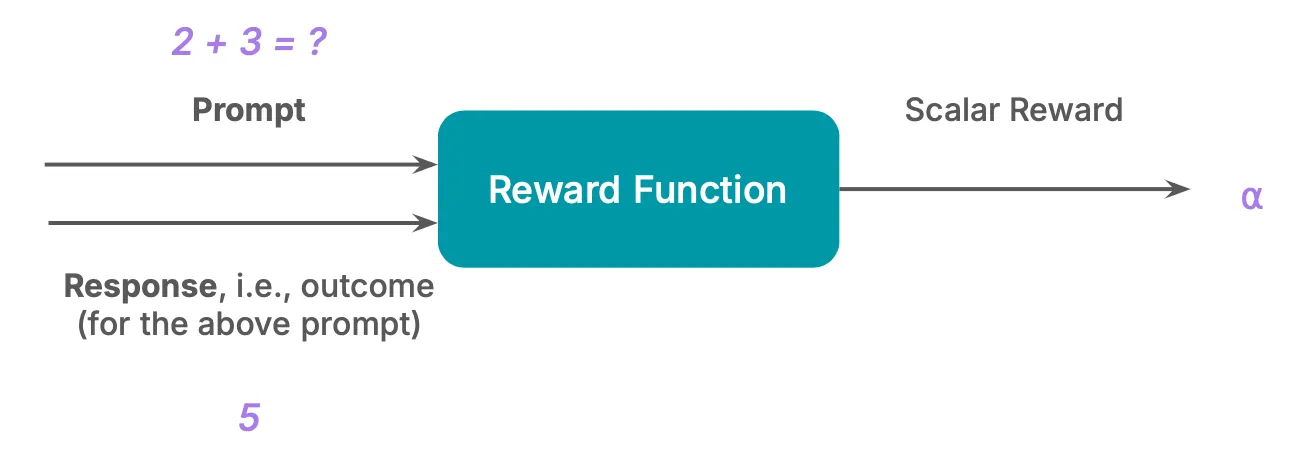
A verifiable reward is one that has a ground truth and can be objectively measured. For instance, mathematical questions often have definitive answers, making them verifiable. Similarly, in logic puzzles, the final correct outcome is known.
By assigning a reward of 1.0 for correct answers and 0 otherwise, RLVR simplifies RL training by eliminating the need for a reward model. Instead, it employs rule-based ground truth verification to streamline the reward process.
However, despite these improvements, RLVR does not yet produce the same observed behaviors as OpenAI's o-series models. This raises the question: what are the missing pieces?
RLVR at Scale
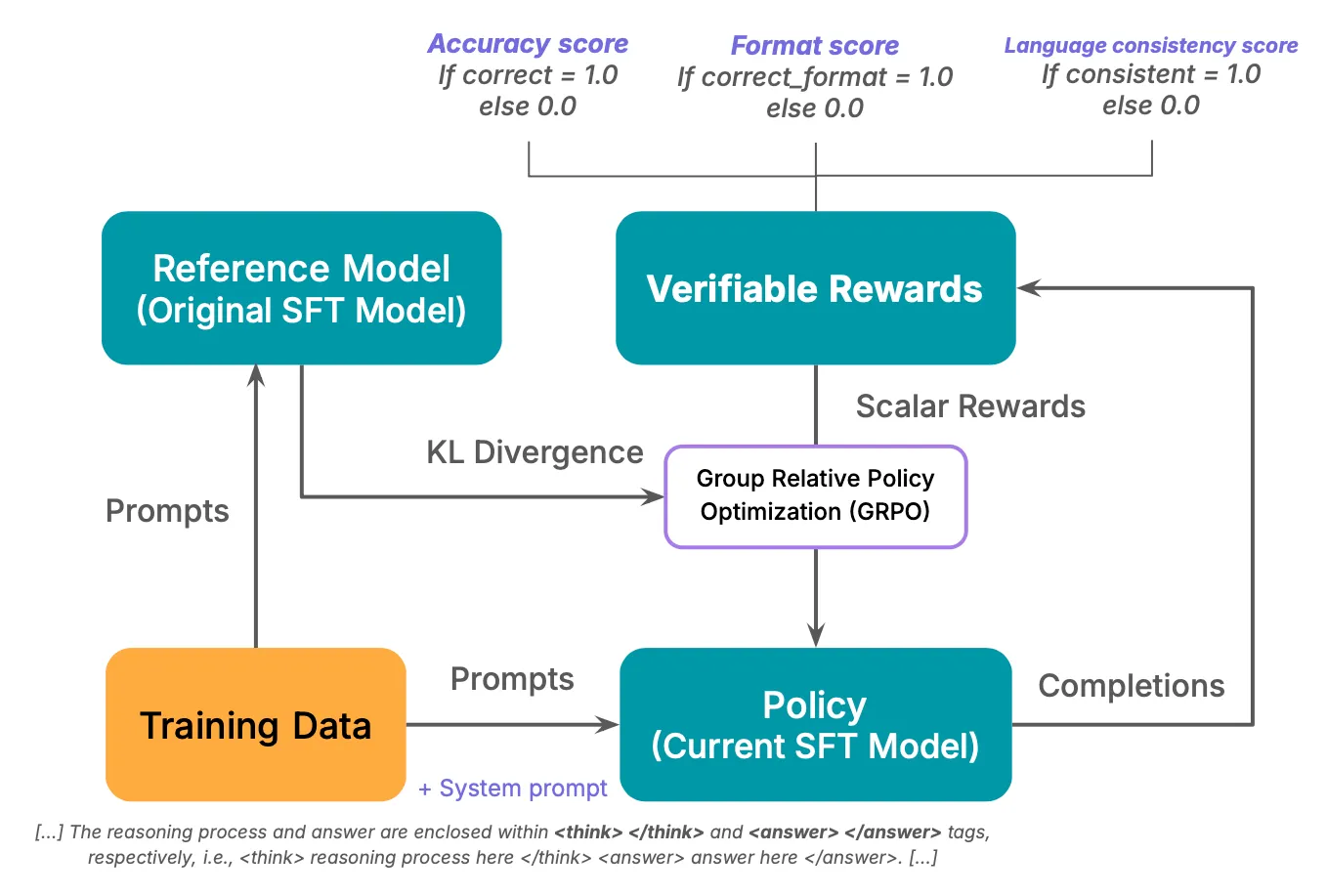
DeepSeek-R1-Zero training loop
DeepSeek R1 [4] is the first model to implement RLVR at scale and achieve results comparable to the o1 model. This report highlights three key elements crucial to this success:
-
Scaling in terms of model size, dataset size, and training steps,
-
An improved reward function, and
-
An optimized system prompt.
Unlike the original RLVR implementation, which utilized models up to 70B parameters, DeepSeek R1 leveraged a significantly larger 671B-parameter model and extended its dataset during RL training. Additionally, the reward function was refined to account for format and language consistency, ensuring responses were both structured and contextually coherent.
These improvements, combined with a specialized system prompt instructing the model to think within <think> tags before finalizing responses within <answer> tags, enabled DeepSeek R1 to replicate “emergent” behaviors similar to the o1 model.
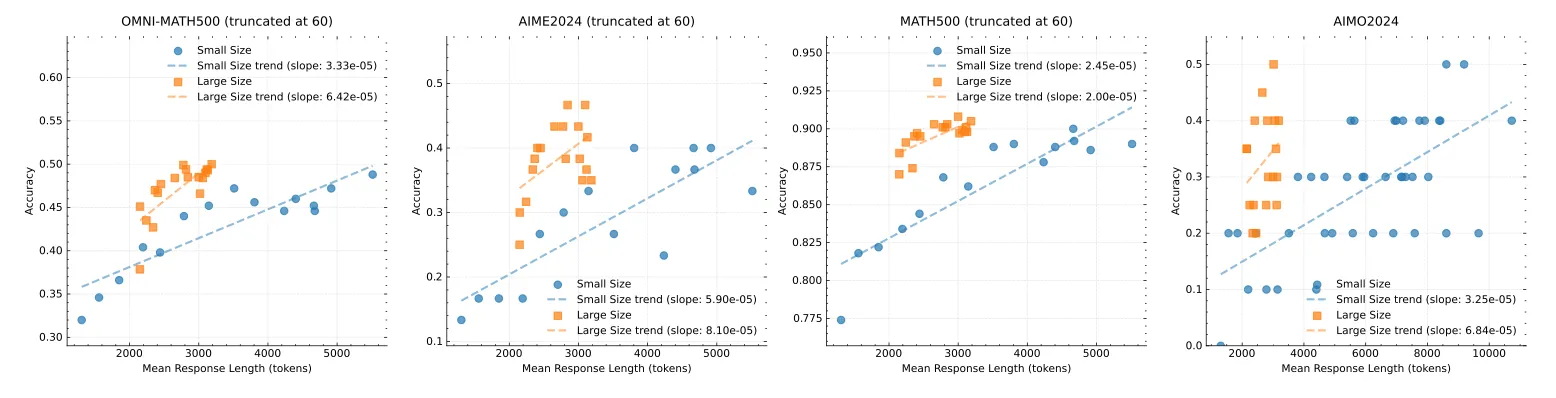
Furthermore, recent reports [5] suggest that model size plays a crucial role in unlocking improved performance, with many observed advancements directly tied to scaling. Kimi k1.5 [6], released concurrently with DeepSeek R1, adopted a similar approach and reported related findings.
Specifically, they observed that larger models tend to demonstrate better token efficiency, requiring fewer reasoning tokens to achieve comparable performance. This aligns with the broader trend that increasing model scale enhances reasoning capability while optimizing computational efficiency.
Recent Research
DeepSeek R1's arrival has sparked interest in the engineering and research communities, leading to deeper investigations into RL-based reasoning models. Recent research aims to explore how and why RL-based reasoning works.
A key question that researchers seek to answer is: Do the "emergent" behaviors of reasoning models, such as self-reflection, backtracking, and problem decomposition, truly emerge during RL training?

Liu et al. [7] suggest that patterns like self-reflection already exist within pre-training data. However, LLMs often struggle to effectively leverage these patterns to enhance performance, leading to superficial self-reflection — instances where reflections do not contribute to improved accuracy. RL facilitates an exploration process that enables LLMs to identify what reasoning patterns to use and when to apply them. In this way, RL serves as a mechanism to discover and utilize latent reasoning capabilities embedded in pre-training data.
Yeo et al. [8] support this hypothesis, noting that phrases indicative of reflection or thought branching are present in pre-training datasets but require proper guidance to be effectively utilized.
Another area of research focuses on identifying the essential components of RLVR in reasoning model development. Key insights from recent studies include:
-
Model size is crucial [4, 5, 6]. Larger models tend to be better suited for constructing effective reasoning models.
-
Instruction-tuned models provide a better starting point (initial policy) than base models [5, 7, 8], leading to improved training efficiency.
-
Response length fluctuations are expected during training [10]. Initial drops in response length are common but stabilize as training progresses.
-
Context length presents a trade-off [11]. While a larger context window may improve performance, it also increases the risk of models generating content until the context limit is reached without meaningful reasoning. Conversely, a smaller context window forces models to be more efficient in reasoning.
-
Reward design is critical, and reward shaping plays a significant role in stabilizing training. [8, 12]
-
SFT on long thought data mitigates cold start issues [7, 8, 9, 11], providing a better initialization point and potentially narrowing the RLVR search space.
-
Generalization is observed beyond training domains [8]. Even with limited domain training, models often exhibit transferability to other domains.
-
Different RL algorithms impact training stability and final performance [8, 12], but the magnitude of these effects varies.
One of the main limitations of current research is its predominant focus on mathematical reasoning, where verifiable rewards are abundant and easy to implement. While some studies have extended RLVR into domains such as logic puzzles [12] and software engineering [13], broader applications remain an open research question.
Expanding RLVR to diverse domains presents challenges related to reward function design and evaluation metrics. Additionally, a deeper understanding of RLVR's intricacies is necessary to further elucidate the knowledge mechanisms within LLMs.

In summary, RLVR offers significant potential for advancing reasoning models by optimizing their ability to leverage reasoning behaviors. While it enables models to uncover unconventional reasoning methods, challenges such as uncontrollable reasoning patterns, inefficiencies (e.g., redundant thinking loops), and computational costs remain. Potential future studies include the broader applicability of RLVR across diverse domains, better reward mechanisms, and enhance generalization capabilities.
Approach 2: Supervised Fine-Tuning

As mentioned in the previous section, SFTprovides a strong initial policy model for RL. However, beyond its role as an RL precursor, SFT alone has demonstrated benefits in extending an existing LLM ability to engage in prolonged reasoning by reinforcing established thinking patterns. Compared to RL, SFT has notable advantages, including lower computational requirements, simpler implementation, and greater generalization potential. The two primary approaches to SFT are knowledge distillation and data augmentation, each contributing uniquely to enhancing a model's reasoning capabilities.
2.1 Knowledge distillation

Recent research has demonstrated that knowledge distillation can effectively enhance reasoning behaviors in small models, though not without challenges. A study by Li et al. [14] indicates that small models benefit most from a mixture of long and short chain-of-thought (CoT) distillation datasets, rather than relying solely on long CoT sequences.
However, a key challenge remains: small models often learn only the syntactic style of reasoning rather than deeply internalizing the actual thinking patterns necessary for robust problem-solving.
Moreover, distillation from large teacher models to smaller students is most effective when the teacher model is not excessively large. Smaller student models tend to generalize better when learning from medium-sized teacher models, as knowledge transfer from extremely large models can overwhelm their capacity to develop meaningful reasoning skills [14].
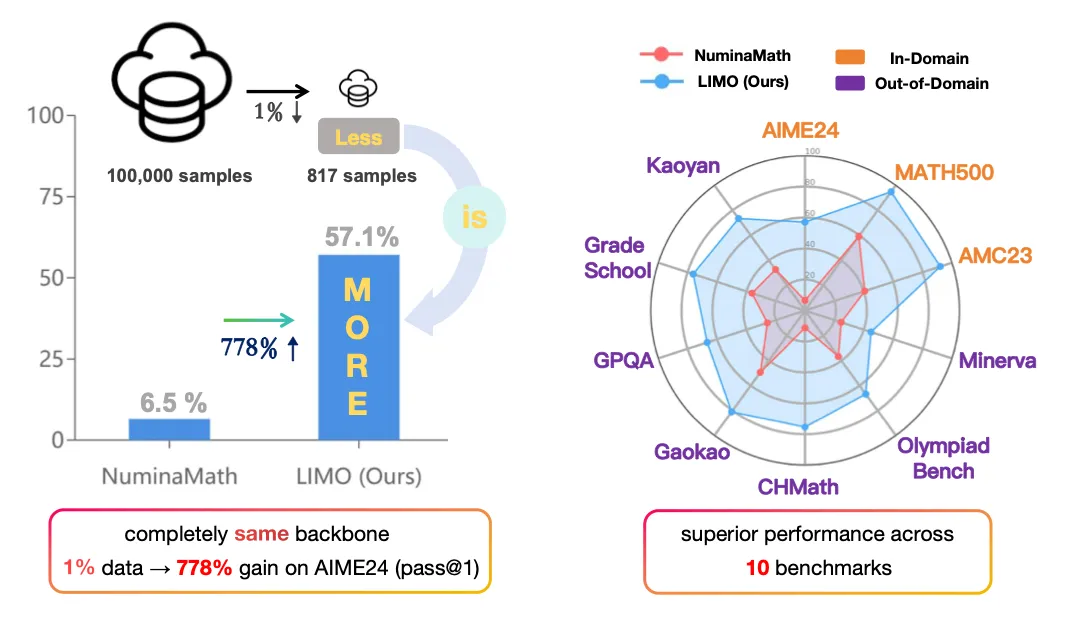
Multiple studies [15, 16, 17] emphasize that quality matters more than sheer dataset size, as even a small number of well-curated training samples can effectively elicit useful long-form thinking patterns in student models. This underscores the importance of data filtration pipelines in optimizing distillation performance.
Effective filtering techniques have been shown to significantly reduce dataset sizes while maintaining comparable performance. For example, a study found that reducing a dataset from 59,000 to 1,000 carefully selected samples yielded nearly identical results [15], demonstrating that high-quality curation is often more impactful than sheer volume.
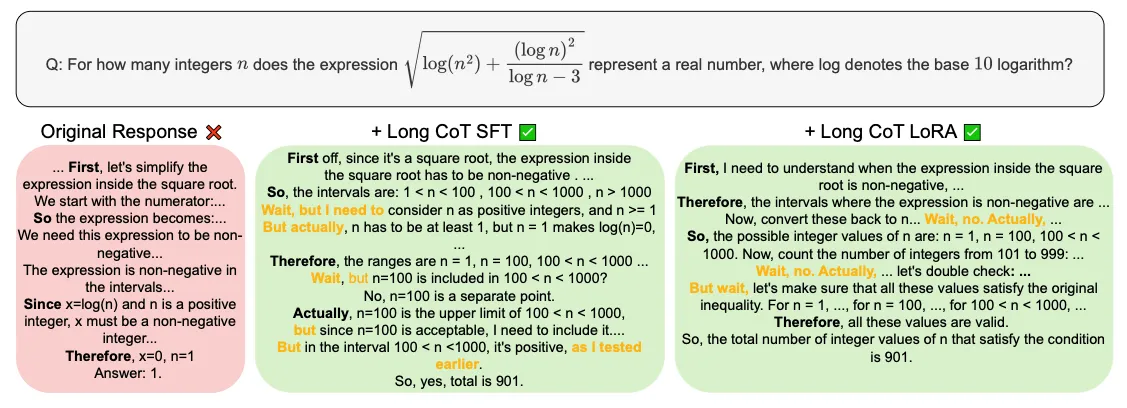
Additionally, a study by Li et al. [18] suggests that the structure of thought processes is more critical than the content itself. The study introduced various perturbations to content while preserving the logical sequence of reasoning and observed minimal performance degradation.
In contrast, disrupting the logical structure — such as shuffling reasoning steps — significantly impaired model performance. This finding reinforces the notion that reasoning structure, rather than specific content details, is the key driver of effective knowledge transfer.
Despite these advancements, limitations persist. Distilled models remain constrained by the reasoning patterns of their teacher models, limiting their ability to develop novel reasoning strategies. While some evidence suggests that student models can occasionally surpass their teachers in specific tasks [17], these cases remain relatively rare.
Overall, while knowledge distillation remains a fast and resource-efficient way to improve model performance, further refinements in data filtration, dataset composition, and teacher model selection are essential to maximize its effectiveness.
2.2 Data augmentation

If a teacher reasoning model is unavailable, how else can we elicit long reasoning behaviors? Research suggests that reasoning is a transferable skill that can be taught to other models. This implies that if we can construct a well-structured long-thought dataset, it is possible to train an LLM to develop these behaviors.
Typhoon T1 [19] leveraged a few-shot [20] generation pipeline to achieve this, demonstrating that even with a limited domain incorporated in the training set, the model was able to generalize across different domains and improve performance.
This finding suggests that identifying and structuring the key properties of long-thought processes could enable the synthetic construction of long-thought datasets, eliminating the need for an expensive RL-based training process.
However, despite these promising results, SFT with long-thought data remains limited by our incomplete understanding of the fundamental properties that define long-form reasoning. While short-term performance gains can be achieved through knowledge distillation, a deeper comprehension of long-thought mechanisms is crucial for unlocking greater advancements in reasoning model development.
Approach 3: Model Merging

One effective approach to leveraging existing reasoning models is through model merging. This technique involves integrating multiple models to capitalize on their unique strengths, leading to improved reasoning capabilities, generalization, and adaptability.
FuseO1 [21] is an example of this approach, combining multiple reasoning models into a single entity. By merging models trained on distinct domains, FuseO1 enhances overall reasoning diversity, allowing the resulting model to generalize across a broader range of tasks and problem types.
This fusion enables the model to inherit and synthesize specialized knowledge from different reasoning models, improving robustness in various problem-solving scenarios.
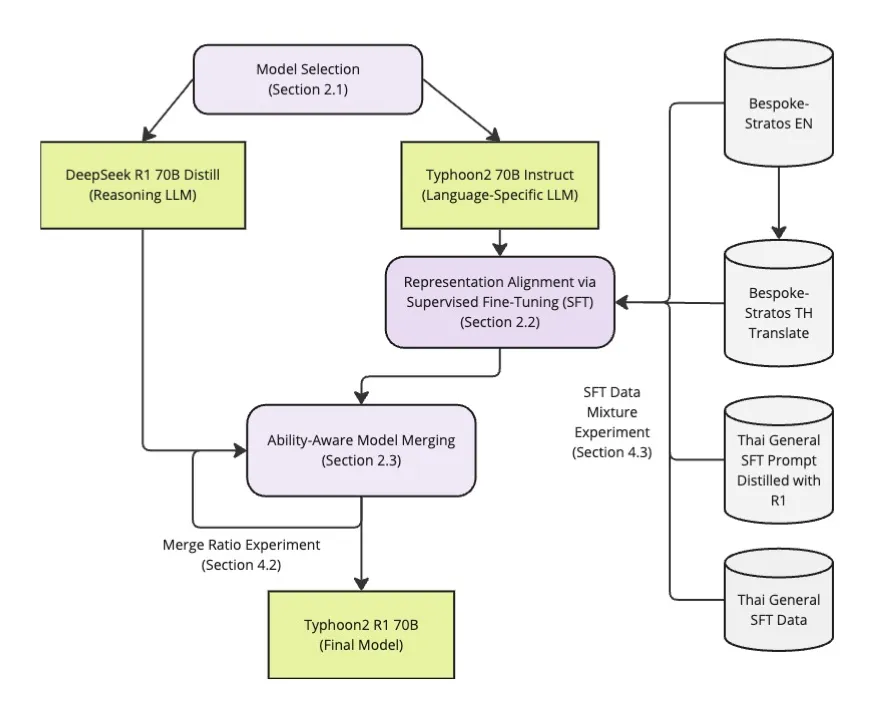
Another notable merged model is Typhoon R1 [22], which focuses on aligning language-specific models with reasoning models. This process begins by adapting language-specific models to long reasoning behaviors, ensuring that their distribution aligns more closely with the target reasoning model. Once the language model is sufficiently adjusted, it is merged with a reasoning model to enhance both language comprehension and logical reasoning capabilities.
This approach ensures that linguistic knowledge is effectively integrated with advanced reasoning patterns, improving both precision and adaptability in multilingual applications.
Despite the advantages of model merging, challenges remain, including compatibility issues between different model architectures, potential training inconsistencies, and the risk of losing specialized knowledge during integration. Ensuring that merged models retain the best aspects of each component while maintaining stability is an active area of research.
Nonetheless, model merging remains a promising and efficient approach to enhancing the capabilities of reasoning models, paving the way for more sophisticated and specialized AI systems.
What's Next?

As reasoning models continue to evolve, several key research directions emerge, shaping the future of their development and application. While existing methods such as RL, SFT, and model merging have proven effective, there remain significant open challenges that require further investigation. Addressing these challenges will be critical for advancing the reasoning capabilities of LLMs and ensuring their adaptability across diverse problem domains.
One important area of research is the improved understanding of long reasoning. Better policy initialization techniques for RL, combined with enhanced data augmentation and filtration pipelines, could provide deeper insights into the mechanisms that govern knowledge retention and application in LLMs. Additionally, exploring why RLVR works effectively and how it can be optimized for cross-domain or multilingual adaptation remains a crucial question, especially as models are deployed in increasingly diverse linguistic and cultural contexts.
Another major challenge lies in the development of heuristic-independent data filtration pipelines and improved data generation strategies for augmentation. Current approaches rely heavily on predefined heuristics, which may introduce biases or limitations in reasoning generalization. Advancing heuristic-free techniques could lead to more robust and flexible reasoning models that can generalize effectively across unseen tasks.
Further advancements in model merging techniques also present exciting possibilities. Merging methodologies, such as those demonstrated in FuseO1, which integrates multiple reasoning models, and Typhoon R1, which aligns language-specific models with reasoning capabilities, offer promising avenues for extending model performance. However, refining these techniques to ensure smooth integration without loss of domain-specific knowledge remains an ongoing challenge.
Beyond these engineering aspects, fundamental theoretical questions persist. Why does long reasoning work? What are the key properties required to make long reasoning effective? Understanding these principles could unlock new training paradigms that further enhance model cognition and decision-making capabilities.
Additionally, efficient thinking [8, 23, 24] without overthinking [25] or underthinking [26] is another critical consideration. Excessive reasoning steps may introduce inefficiencies, while insufficient steps may compromise solution accuracy. Developing frameworks that regulate reasoning complexity dynamically could significantly improve both performance and efficiency in LLMs.
In summary, the future of reasoning models will be shaped by advancements in training methodologies, theoretical insights, and optimization strategies. Addressing these open questions will be essential for driving progress in AI reasoning and ensuring that LLMs continue to evolve toward more intelligent, adaptive, and reliable problem solvers.
Citation
References
[1] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, Denny Zhou. “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models.” (2023). https://arxiv.org/abs/2201.11903
[2] Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, Ryan Lowe. “Training language models to follow instructions with human feedback.” (2022). https://arxiv.org/abs/2203.02155
[3] Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James V. Miranda, Alisa Liu, Nouha Dziri, Shane Lyu, Yuling Gu, Saumya Malik, Victoria Graf, Jena D. Hwang, Jiangjiang Yang, Ronan Le Bras, Oyvind Tafjord, Chris Wilhelm, Luca Soldaini, Noah A. Smith, Yizhong Wang, Pradeep Dasigi, Hannaneh Hajishirzi. “Tulu 3: Pushing Frontiers in Open Language Model Post-Training.” (2025). https://arxiv.org/abs/2411.15124
[4] DeepSeek-AI, et al. “DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.” (2025). https://arxiv.org/abs/2501.12948
[5] https://x.com/jiayi_pirate/status/1882839370505621655
[6] Kimi Team et al., “Kimi k1.5: Scaling Reinforcement Learning with LLMs.” (2025). https://arxiv.org/abs/2501.12599
[7] Zichen Liu, Changyu Chen, Wenjun Li, Tianyu Pang, Chao Du, Min Lin. “There May Not be Aha Moment in R1-Zero-like Training — A Pilot Study.” . (2025). https://oatllm.notion.site/oat-zero
[8] Edward Yeo, Yuxuan Tong, Morry Niu, Graham Neubig, Xiang Yue. “Demystifying Long Chain-of-Thought Reasoning in LLMs.” (2025). https://arxiv.org/abs/2502.03373
[9] Tianzhe Chu, Yuexiang Zhai, Jihan Yang, Shengbang Tong, Saining Xie, Dale Schuurmans, Quoc V. Le, Sergey Levine, Yi Ma. “SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training.” (2025). https://arxiv.org/abs/2501.17161
[10] Weihao Zeng, Yuzhen Huang, Wei Liu, Keqing He, Qian Liu, Zejun Ma, Junxian He. “7B Model and 8K Examples: Emerging Reasoning with Reinforcement Learning is Both Effective and Efficient.”(2025). https://hkust-nlp.notion.site/simplerl-reason
[11] Michael Luo, Sijun Tan, Justin Wong, Xiaoxiang Shi, William Y. Tang, Manan Roongta, Colin Cai, Jeffrey Luo, Tianjun Zhang, Li Erran Li, Raluca Ada Popa, Ion Stoica. “DeepScaleR: Surpassing O1-Preview with a 1.5B Model by Scaling RL.” (2025). https://pretty-radio-b75.notion.site/DeepScaleR-Surpassing-O1-Preview-with-a-1-5B-Model-by-Scaling-RL-19681902c1468005bed8ca303013a4e2
[12] Tian Xie, Zitian Gao, Qingnan Ren, Haoming Luo, Yuqian Hong, Bryan Dai, Joey Zhou, Kai Qiu, Zhirong Wu, Chong Luo. “Logic-RL: Unleashing LLM Reasoning with Rule-Based Reinforcement Learning.” (2025). https://arxiv.org/abs/2502.14768
[13] Yuxiang Wei, Olivier Duchenne, Jade Copet, Quentin Carbonneaux, Lingming Zhang, Daniel Fried, Gabriel Synnaeve, Rishabh Singh, Sida I. Wang. “SWE-RL: Advancing LLM Reasoning via Reinforcement Learning on Open Software Evolution.” (2025). https://arxiv.org/abs/2502.18449
[14] Yuetai Li, Xiang Yue, Zhangchen Xu, Fengqing Jiang, Luyao Niu, Bill Yuchen Lin, Bhaskar Ramasubramanian, Radha Poovendran. “Small Models Struggle to Learn from Strong Reasoners.” (2025). https://arxiv.org/abs/2502.12143
[15] Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, Tatsunori Hashimoto. “s1: Simple test-time scaling.” (2025). https://arxiv.org/abs/2501.19393
[16] Yixin Ye, Zhen Huang, Yang Xiao, Ethan Chern, Shijie Xia, Pengfei Liu. “LIMO: Less is More for Reasoning.” (2025). https://arxiv.org/abs/2502.03387
[17] Zhen Huang, Haoyang Zou, Xuefeng Li, Yixiu Liu, Yuxiang Zheng, Ethan Chern, Shijie Xia, Yiwei Qin, Weizhe Yuan, Pengfei Liu. “O1 Replication Journey — Part 2: Surpassing O1-preview through Simple Distillation, Big Progress or Bitter Lesson?.” (2024). https://arxiv.org/abs/2411.16489
[18] Dacheng Li, Shiyi Cao, Tyler Griggs, Shu Liu, Xiangxi Mo, Eric Tang, Sumanth Hegde, Kourosh Hakhamaneshi, Shishir G. Patil, Matei Zaharia, Joseph E. Gonzalez, Ion Stoica. “LLMs Can Easily Learn to Reason from Demonstrations Structure, not content, is what matters!.” (2025). https://arxiv.org/abs/2502.07374
[19] Pittawat Taveekitworachai, Potsawee Manakul, Kasima Tharnpipitchai, Kunat Pipatanakul. “Typhoon T1: An Open Thai Reasoning Model.” (2025). https://arxiv.org/abs/2502.09042
[20] Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, Dario Amodei. “Language Models are Few-Shot Learners.” (2020). https://arxiv.org/abs/2005.14165
[21] https://github.com/fanqiwan/FuseAI/tree/main/FuseO1-Preview
[22] Kunat Pipatanakul, Pittawat Taveekitworachai, Potsawee Manakul, Kasima Tharnpipitchai. “Adapting Language-Specific LLMs to a Reasoning Model in One Day via Model Merging — An Open Recipe.” (2025). https://arxiv.org/abs/2502.09056
[23] Haotian Luo, Li Shen, Haiying He, Yibo Wang, Shiwei Liu, Wei Li, Naiqiang Tan, Xiaochun Cao, Dacheng Tao. “O1-Pruner: Length-Harmonizing Fine-Tuning for O1-Like Reasoning Pruning.” (2025). https://arxiv.org/abs/2501.12570
[24] NovaSky Team, “Think Less, Achieve More: Cut Reasoning Costs by 50% Without Sacrificing Accuracy.” (2025). https://novasky-ai.github.io/posts/reduce-overthinking/
[25] Xingyu Chen, Jiahao Xu, Tian Liang, Zhiwei He, Jianhui Pang, Dian Yu, Linfeng Song, Qiuzhi Liu, Mengfei Zhou, Zhuosheng Zhang, Rui Wang, Zhaopeng Tu, Haitao Mi, Dong Yu. “Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs.” (2025). https://arxiv.org/abs/2412.21187
[26] Yue Wang, Qiuzhi Liu, Jiahao Xu, Tian Liang, Xingyu Chen, Zhiwei He, Linfeng Song, Dian Yu, Juntao Li, Zhuosheng Zhang, Rui Wang, Zhaopeng Tu, Haitao Mi, Dong Yu. “Thoughts Are All Over the Place: On the Underthinking of o1-Like LLMs.” (2025). https://arxiv.org/abs/2501.18585

