

As DeepSeek R1 takes the world by storm, our focus on improving reasoning capabilities continues, starting with Typhoon T1. We’re excited to introduce another experiment aimed at advancing reasoning — Typhoon2-R1–70B.
This new model builds upon Typhoon 2’s strong Thai language understanding and generation while significantly improving its reasoning capabilities. By leveraging DeepSeek R1, we have developed Typhoon2-DeepSeek-R1–70B — we like to refer to as Typhoon2-R1–70B.
- 💻 Demo: https://playground.opentyphoon.ai/
- 🤗 Model weights (Typhoon2-R1-70B): llama3.1-typhoon2-deepseek-r1–70b-preview
- 📝 Paper: https://arxiv.org/abs/2502.09056
Key Highlights
- Advanced Reasoning: Comparable to DeepSeek R1 70B Distill’s reasoning capabilities.
- Enhanced Math & Coding Performance: Up to 6 times more accurate than Typhoon2 70B Instruct.
- Strong Thai Language Proficiency: Performs similarly to Typhoon2 70B Instruct.
- Cross-Domain Reasoning:: Adapts to various domains, going beyond math and coding.
- Availability: The 70B model is now available on HF, with smaller variants on the way!
Introduction
Here’s the story behind how this project started. When DeepSeek R1 was released, we — like everyone else — were thrilled and eager to explore its capabilities. We used it extensively, but one key weakness quickly became apparent: code-switching.
DeepSeek R1 primarily responds in English, even when given Thai instructions. Additionally, when it generates Thai, it often code-switches, inserting non-Thai characters — like Chinese and Russian — into its output. To investigate further, we evaluated it using our general benchmark, the same one we used to develop Typhoon 2.
Our findings revealed that on Thai-specific tasks, DeepSeek R1 70B Distill performed even worse than Typhoon 1.5 8B model. In our code-switching evaluation, it produced fully corrected Thai tokens only **19% **of the time.
However, DeepSeek R1 is great in reasoning-intensive tasks like math, coding, and complex problem-solving, outperforming Typhoon 2 by up to 6x.
Methodology
To develop Typhoon2-R1, we built upon the approach established in Typhoon 1.5X. For this release, we specifically selected Typhoon2 70B Instruct and DeepSeek R1 70B Distill as the base models for enhancement.
Our goal was to combine DeepSeek R1’s reasoning ability with Typhoon 2’s Thai language proficiency, while also addressing the code-switching issue and balance the trade-off between both. To accomplish this, we employed a multi-step optimization process:
Supervised Fine-Tuning (SFT):
- We aligned Typhoon 2 and DeepSeek R1 70B Distill using an open-source dataset focused on multilingual tasks and advanced reasoning challenges.
- The primary goal was to harmonize the representations of both models, ensuring the merging process did not compromise performance.
- Additionally, we refined the recipe to produce fluent, contextually accurate Thai outputs while preserving DeepSeek R1’s reasoning capabilities.
Model Merging:
- We experimented with different merging hyperparameters to achieve an optimal balance between the models.
- This step involved extensive evaluation across multiple dimensions, ensuring that neither reasoning strength nor linguistic accuracy was sacrificed.
By combining fine-tuning with model merging, Typhoon2-R1 enhances reasoning performance while maintaining strong Thai-language generation.
Performance Evaluation
To assess Typhoon2-R1, we evaluated reasoning using standard benchmarks, particularly those used in Sky-T1. Specifically, we selected MATH500, AIME, and LiveCodeBench, which focus on mathematical and coding reasoning. We also created ** by translating the original datasets, allowing us to measure reasoning in both languages.
In addition to reasoning performance, we used the same evaluation datasets previously applied to measure Typhoon 2 instruction-following capabilities in Thai and English.
Evaluation Benchmarks
We conducted evaluations across two major categories:
1. Reasoning Performance
- AIME 2024: A dataset from the **USA Math Olympiad (AIME), **consisting of 30 complex mathematical problems. We translated them into Thai, creating a 60-problem bilingual dataset.
- MATH500: A subset of the MATH benchmark, containing 500 advanced mathematical problems to test step-by-step reasoning. We also included a Thai-translated version, resulting in 1,000 problems total.
- LiveCodeBench: A competitive programming benchmark featuring problems from LeetCode, AtCoder, and CodeForces. It contains a total of 511 problems. When combined with the translated Thai versions, there are 1,022 problems in total.
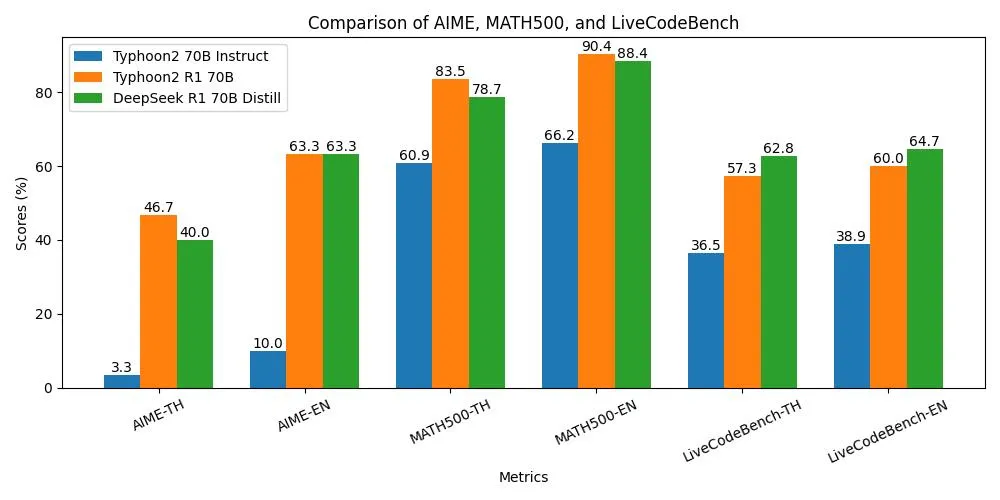
Reasoning task performance in Thai and English
2. General Instruction-Following Performance
- MT-Bench: A LLM-as-judge framework that evaluates correctness, fluency, and instruction adherence on open-end instruction. We used both the Thai MT-Bench and the English MT-Bench from LMSYS.
- IFEval: Evaluates instruction-following accuracy based on verifiable test cases. We used both the English IFEval and the Thai version.
- Code-Switching: Measures whether the model responds in the correct language while maintaining linguistic consistency. We sampled 500 Thai instructions from the WangchanThaiInstruct dataset as used in Typhoon 2.
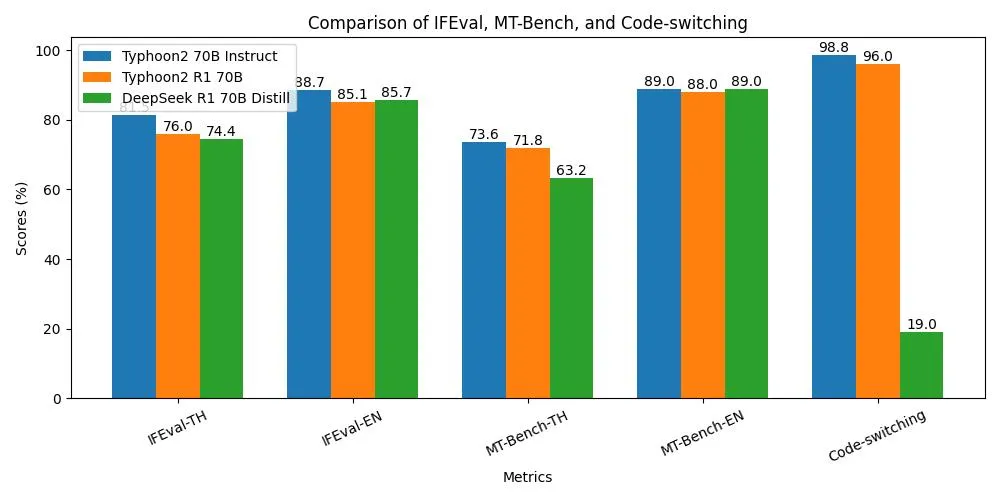
Benchmark Discussion
As shown in the results chart, reasoning performance improves significantly from the base Typhoon2 70B Instruct to a level similar to DeepSeek R1 70B. It even outperforms DeepSeek R1 70B in math tasks, while in coding tasks, it is only ~4% worse. In general task performance, it is comparable with slightly worse than Typhoon2 due to some loss in Thai knowledge capability. However, it shows significant improvement over DeepSeek R1 70B in terms of usability, code-switching (corrected language generation) performance and knowledge (MT-Bench-TH score).
Conclusion
With Typhoon2-R1, we take a step toward building a highly capable reasoning model for Thai, bridging the gap between advanced AI reasoning and Thai language understanding. This release enhances LLM performance in Thai and paves the way for AI adoption in reasoning-critical applications.
Limitations & Future Work
While Typhoon2-R1 advances reasoning for Thai, several challenges remain:
- Cultural Awareness in Reasoning: The model still lacks context-aware reasoning tailored to Thai cultural nuances.
- English Reasoning Trace: Currently, the model’s reasoning trace is still in English. We are working on localizing it for better alignment with Thai.
- Low-Resource vs. High-Resource Performance Gap: Thai-language performance still lags behind high-resource languages like English.
- Smaller Model Variants: We aim to develop smaller, efficient models while maintaining strong reasoning capabilities.

