

Release Note: Typhoon-Audio (v1.5 Preview)
🤗 Model weights: https://huggingface.co/scb10x/llama-3-typhoon-v1.5-8b-audio-preview
📝 Technical report (paper) and evaluation data to be released later
We present Typhoon-Audio, a new development in Thai NLP and speech processing as the first Thai audio-language model. This release is a “research preview” which showcases our latest development as an integral component of the broader Typhoon multimodal model. Built upon the Typhoon 1.5 8B Instruct language model and integrating advanced audio processing capabilities, Typhoon-Audio is designed to handle a diverse range of tasks including transcription, speech translation, speech instruction following, spoken-document question answering, and audio captioning as illustrated in Figure 1.
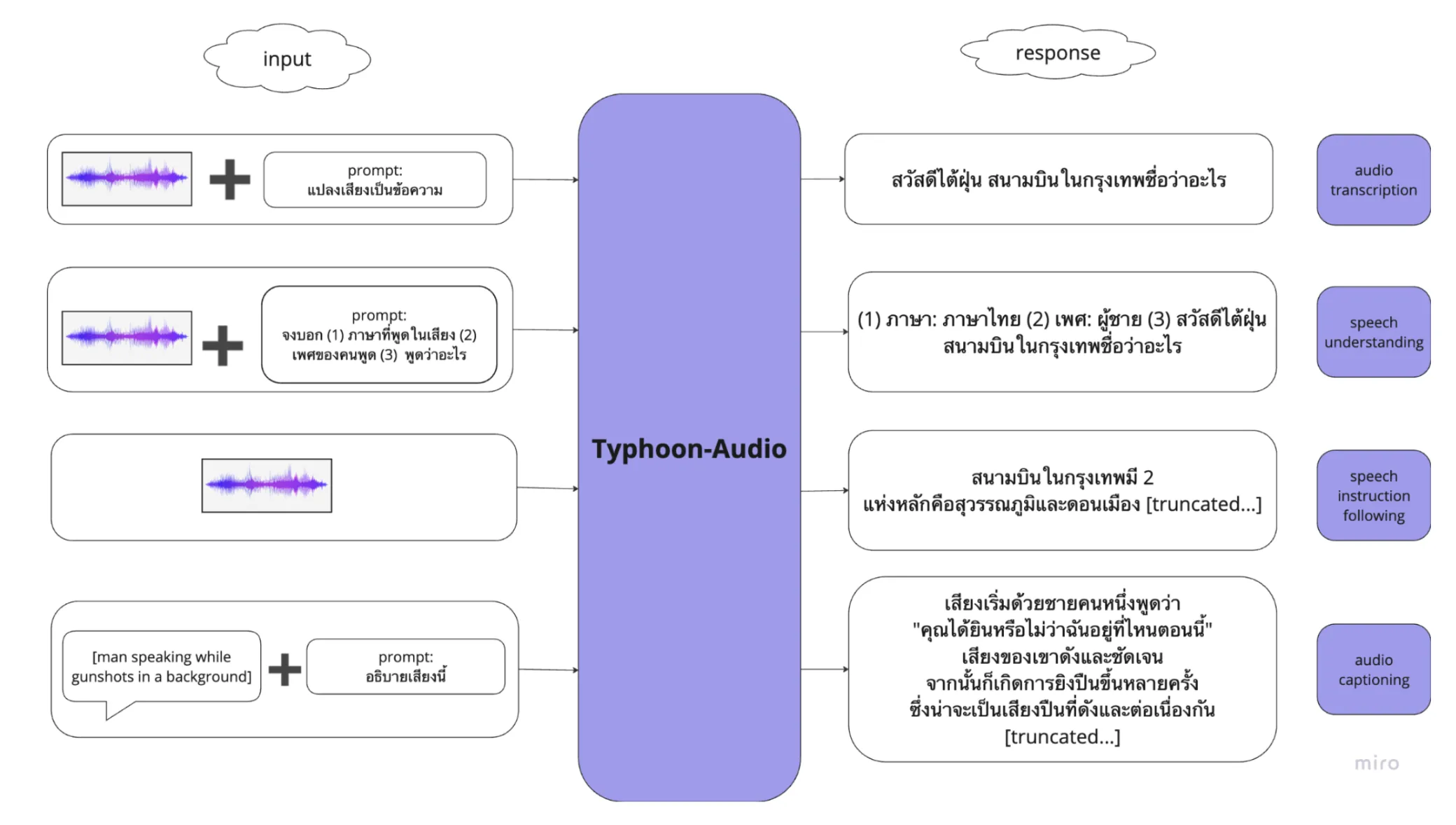
Figure 1: Examples of tasks that Typhoon-Audio can perform
Crucially, it accomplishes the aforementioned tasks in an end-to-end manner, circumventing the need for intermediate transcribed texts. This approach also enables Typhoon-Audio to perform tasks that traditional pipeline systems — such as Automatic Speech Recognition (ASR) combined with a Large Language Model (LLM) — are unable to handle. These tasks include the understanding of voice characteristics (e.g., speaker gender or emotion) or the interpretation of audio events (e.g., background sounds or audio events), highlighting the model’s capability to engage with both linguistic and paralinguistic elements in audio.
Model Architecture and Training
We integrate the Typhoon-1.5–8B model (the LLM) with an audio encoder through an adapter as shown in Figure 2. Specifically, following the SALMONN recipe [1], we employ Whisper’s encoder [2] and BEATs [3] for the audio encoder and utilize Q-Former as the adapter.
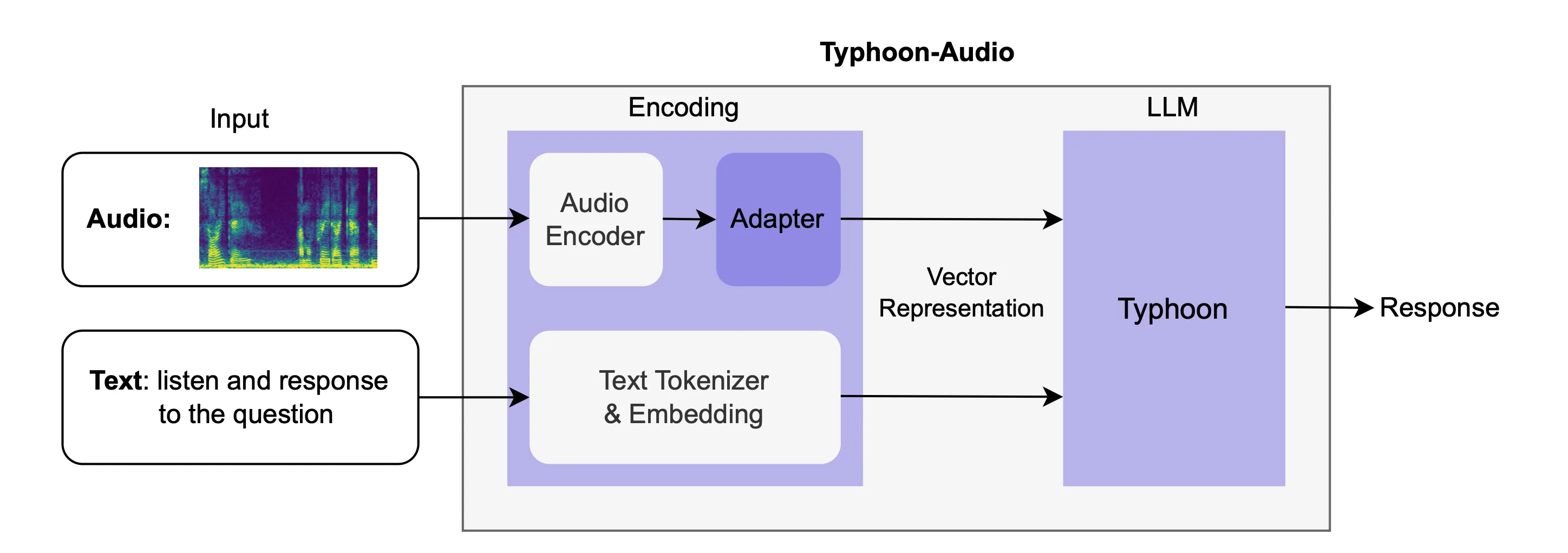
Figure 2: The architecture of Typhoon-Audio
Our training process is divided into two stages: pre-training and supervised fine-tuning (SFT).
In the pre-training stage, we use English ASR, Thai ASR, audio captioning, and Thai-translated audio caption datasets, and we train only the adapter while keeping all other components fixed.
In the SFT stage, we employ a diverse set of instruction prompts paired with audio data, including audio document QA (as in SALMONN [1] and LTU [4]) and speech instruction following data.
Given the absence of existing Thai speech instruction following datasets, we generated text outputs (using Typhoon) from existing Thai speech data and synthesized speech inputs (using TTS systems) from existing text instruction-output pairs. During this stage, we also train the LoRA weights of Typhoon alongside the adapter, while maintaining the speech encoder in a frozen state.
Benchmarking and Evaluation Results
We compare Typhoon-Audio against strong baselines, including open-source English-centric audio language models such as SALMONN-13B [1], DiVA-8B [5], and the state-of-the-art Gemini-1.5-Pro [6]. The evaluation tasks and corresponding metrics include ASR (in Thai and English using WER), speech translation (En2Th, X2Th, Th2En using BLEU), gender identification (using Accuracy), Thai spoken document question answering (using EM and F1), and novel Thai speech instruction following (using GPT-4o-mini to evaluate text outputs).
Firstly, ASR-en is evaluated on the LibriSpeech dataset (clean and other subsets). ASR-th is evaluated using the Thai test set from Common Voice 17, with WER measured using the newmm tokenizer. Speech translation (English-to-Thai and X-to-Thai) is evaluated on 4,000 samples drawn from CoVoST2, while Thai-to-English speech translation is evaluated using 2,000 samples from the translated Thai Common Voice 17 dataset.
| Model | ASR-en (WER↓) | ASR-th (WER↓) | En2Th (BLEU↑) | X2Th (BLEU↑) | Th2En (BLEU↑) |
|---|---|---|---|---|---|
| SALMONN-13B | 2.74, 5.79 | 98.07 | 0.07 | 0.10 | 14.97 |
| DiVA-8B | 31.30, 30.28 | 65.21 | 9.82 | 5.31 | 7.97 |
| Gemini-1.5-pro-001 | 3.36, 5.98 | 13.56 | 20.69 | 13.52 | 22.54 |
| Typhoon-Audio-Preview | 3.96, 8.72 | 14.17 | 17.52 | 10.67 | 24.14 |
Table 1: Experimental results on ASR and speech translation
Secondly, we evaluate performance in gender identification using Thai speech emotion recognition data, which includes gender labels. Additionally, we evaluate spoken document question answering using questions derived from Thai Common Voice 17, and speech-based instruction-following with synthesized prompts that direct task execution where GPT-4o-mini serves as a judge in a manner similar to MT-Bench.
| Model | Gender-th (Acc) | SpokenQA-th (EM, F1) | SpeechInstruct-th |
|---|---|---|---|
| SALMONN-13B | 93.26 | 0.00, 2.95 | 1.18 |
| DiVA-8B | 50.12 | 1.95, 15.13 | 2.68 |
| Gemini-1.5-pro-001 | 81.32 | 35.79, 62.10 | 3.93 |
| Typhoon-Audio-Preview | 93.74 | 38.05, 64.60 | 6.11 |
Table 2: Experimental results on gender identification, spoken Q&A, and speech instruction following
The results indicate that while SALMONN-13B performs well on tasks requiring English outputs, such as English ASR and Thai-to-English speech translation, its performance degrades significantly on Thai-specific tasks. DiVA-8B demonstrates greater robustness compared to SALMONN-13B; however, it still falls short in Thai tasks and has a high insertion rate due to its inability to follow instructions that explicitly ask for only transcriptions. In contrast, Gemini-1.5-Pro shows better performance in Thai tasks.
Typhoon-Audio surpasses existing open-source audio language models by a significant margin in tasks involving Thai speech understanding and Thai text generation. Not only does Typhoon-Audio represent the state-of-the-art among open-source audio language models for Thai tasks, but it also outperforms Gemini-1.5-Pro in certain tasks, particularly Thai speech instruction-following.
Examples from Typhoon-Audio
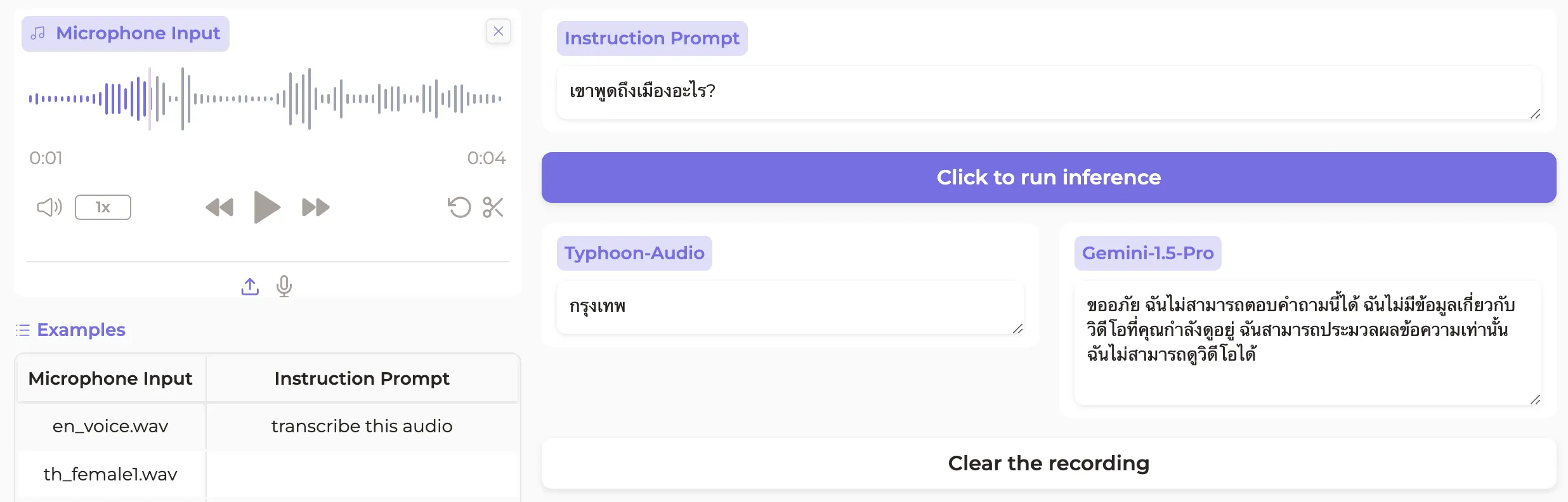

What’s next for Audio?
- Context length: The current model does not support long audio inputs (below 30 seconds), so we are working on extending its input context.
- Scaling training data: Currently, the audio-language model does not exhibit emergent capabilities to the same extent as text models, which we attribute in part to the scale of data. Towards solving this problem, large-scale Thai ASR data, such as Gigaspeech2 with over 10,000 hours of Thai data, provides a promising way. We initially focus on leveraging this massive dataset to develop advanced ASR models, with the ultimate goal of applying these advancements to multimodal Typhoon.
Bonus Release
Introducing monsoon-whisper-medium-gigaspeech2, our experimental ASR model developed using 10,000 hours of Gigaspeech2 data [7]. This model demonstrates robust performance on realistic data, such as audio sourced from YouTube. While its accuracy on read speech data, like that from Common Voice, may not surpass the current best open Thai ASR model, its strong results on YouTube audio suggest that this release could be valuable to the community. Evaluation results on the test sets of GigaSpeech2 and Common Voice 17 are provided in Table 3 below.
🤗 Model weights: https://huggingface.co/scb10x/monsoon-whisper-medium-gigaspeech2
| Model | WER (GS2) | WER (CV) | CER (GS2) | CER (CV) |
|---|---|---|---|---|
| whisper-large-v3 | 37.02 | 22.63 | 24.03 | 8.49 |
| whisper-medium | 55.64 | 43.01 | 37.55 | 16.41 |
| biodatlab-whisper-th-medium-combined | 31.00 | 14.25 | 21.20 | 5.69 |
| biodatlab-whisper-th-large-v3-combined | 29.02 | 15.72 | 19.96 | 6.32 |
| monsoon-whisper-medium-gigaspeech2 | 22.74 | 20.79 | 14.15 | 6.92 |
Table 3: Evaluation results of monsoon-whisper-medium-gigaspeech2
Acknowledgements
We would like to thank the SALMONN team for open-sourcing their code and data, and thanks to the Biomedical and Data Lab at Mahidol University for releasing the fine-tuned Whisper that allowed us to adopt its encoder. Thanks to many other open-source projects for their useful knowledge sharing, data, code, and model weights.
References
[1] SALMONN: Towards Generic Hearing Abilities for Large Language Models, Tang et al., 2024.
[2] Robust Speech Recognition via Large-Scale Weak Supervision, Radford et al., 2022.
[3] BEATs: Audio Pre-Training with Acoustic Tokenizers, Chen et al., 2022.
[4] Listen, Think, and Understand, Gong et al., 2023.
[5] DiVA: Distilled Voice Assistant, Held et al., 2024.
[6] Gemini-1.5-Pro (Audio) https://ai.google.dev/gemini-api/docs/audio
[7] GigaSpeech 2: An Evolving, Large-Scale and Multi-domain ASR Corpus for Low-Resource Languages with Automated Crawling, Transcription and Refinement, Yang et al., 2024.

