
Release Note: Typhoon-Vision (v1.5 Preview)
💻 Demo: https://vision.opentyphoon.ai/
🤗 Model weights: https://huggingface.co/scb10x/llama-3-typhoon-v1.5-8b-vision-preview
📝 Technical report (paper) and evaluation data to be released later
We present Typhoon-Vision, a multimodal AI model designed specifically for Thai language and visual understanding. Built upon the Typhoon 1.5 8B Instruct language model and integrating advanced visual processing capabilities, Typhoon-Vision represents a significant advancement in Thai-centric AI technology. This report details the model’s architecture, training methodology, performance metrics, and future research directions.
1. Introduction
Multimodal AI models that can process both textual and visual information have seen rapid advancements in recent years. However, most of these models have been primarily developed for English and other high-resource languages. Typhoon-Vision addresses this gap by providing a powerful multimodal model optimized for the Thai language, enabling sophisticated visual-language understanding tasks in Thai contexts.
2. Model Architecture
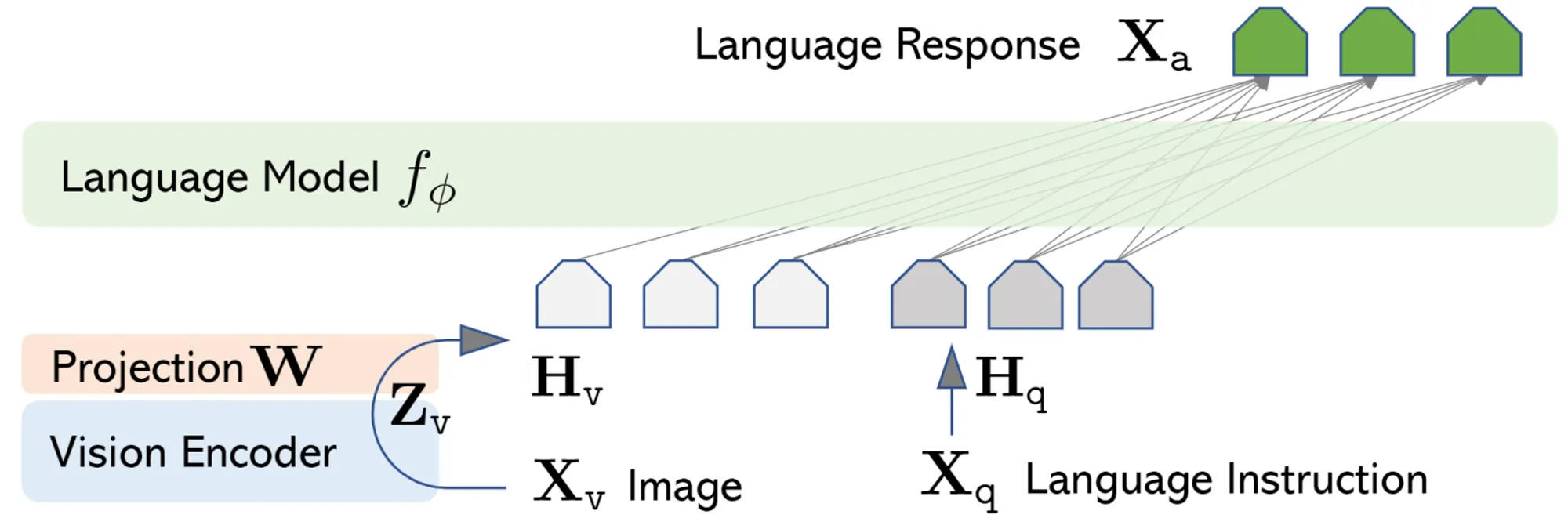
LLaVa Architecture (image courtesy of the LLaVa paper)
Typhoon-Vision builds upon the architecture introduced by the Bunny model from BAAI, which follows the LLaVA (Large Language and Vision Assistant) architecture. The key components of our model are:
- Vision Encoder: SigLIP [1]
- Language Model: Typhoon 1.5 8B Instruct, based on Llama3–8B and pre-trained on Thai language data
- Multimodal Projector: A 2-layer GELU MLP connecting the vision and language components
The total parameter count of Typhoon-Vision is 8.5 billion, with 8 billion parameters in the language model and 0.5 billion in the vision components.
3. Training Methodology
3.1 Datasets
Our training process utilized the Bunny Dataset [2] and a Thai Translated Subset of the Bunny Dataset as well. For some select complex tasks (e.g., image captioning) we choose to distil from GPT-4o [3].
A significant challenge in developing Typhoon-Vision was the scarcity of high-quality Thai multimodal data. To address this, we employed:
-
Translation of existing datasets: We use our in-house model for the translation. We filter out low-quality translations and use only high-quality ones.
-
Translated Data Ratio Ablations: In order to find the best ratio of translated data that does not degrade English performance, we ablate the ratio of Thai translated data we add into the training set. For this preliminary study, we discovered that the best ratio is around 10 to 25%.
3.2 Training Process
Following Bunny, we use the same 2 stage training. In the first stage (pretraining), our goal is to align the embeddings between the vision encoder and the language model. Thus for this stage, we only train the projection layer and freeze everything else. In the second stage (multimodal instruction tuning), we tune the projection layer and LLM (LoRA) while keeping the vision encoder itself frozen.
4. Evaluation and Performance
We evaluated Typhoon-Vision on several benchmarks to assess its performance in various visual-language tasks. The following sections detail our findings.
4.1 Image Captioning Performance
We utilized the IPU-24 dataset [4], a Thai-centric image captioning benchmark developed by NECTEC. This dataset combines images from the COCO2017 validation set with custom images focused on Thai cultural elements. The captions for COCO2017 images were rewritten in Thai to ensure cultural relevance. The validation set of IPU-24 contains around 9000 records. Here is an example:

Gold Standard Captions:
- อุโบสถหลังสีขาว หลังคาสีแดงปิดด้วยสีทอง ตั้งภายในวัด และมีกระถางต้นไม้วางอยู่ข้างหน้า
- โบสถ์สีขาวหลังหนึ่งมีหลังคาสีแดงปนทองและขอบประตูสีทอง
- โบสถ์มีผนังสีขาว มีซุ้มประตูสีทอง รอบ ๆ มีกระถางต้นไม้ มีต้นไม้
We prompt Bunny Llama3 8B, SeaLMMM 7B v0.1 [5], and GPT4o-mini to generate captions for these images by saying “อธิบายเนื้อหาของภาพนี้อย่างละเอียดเป็นภาษาไทย.” We use Llama3.1–70B-Instruct [6] to act as a judge evaluating the performance of all models. Please see the Appendix for the exact prompt used.
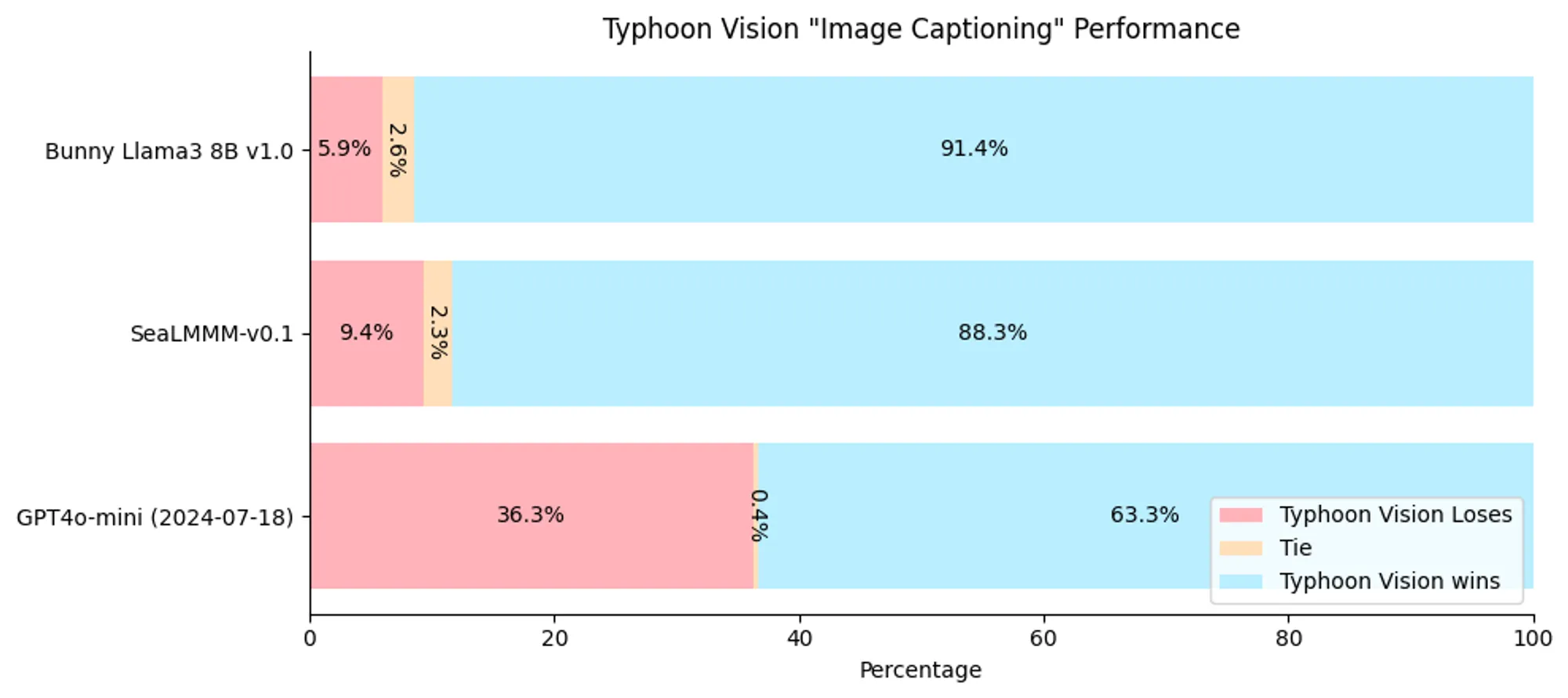
Performance comparison of models on IPU-24.
As shown, Typhoon-Vision significantly outperforms other models, including Bunny Llama3 8B v1.0, SeaLMMM-v0.1, and GPT4o-mini, demonstrating its superior capability in Thai image captioning tasks.
4.2 Multimodal Benchmark Performance
We evaluated Typhoon-Vision on several established multimodal benchmarks to assess its general capabilities:
The benchmarks used include:
- MMBench [7] (Dev Set): MMBench is a visual LLM evaluation dataset measuring multiple skills such as image reasoning, actioning recognition, scene understanding, and more.
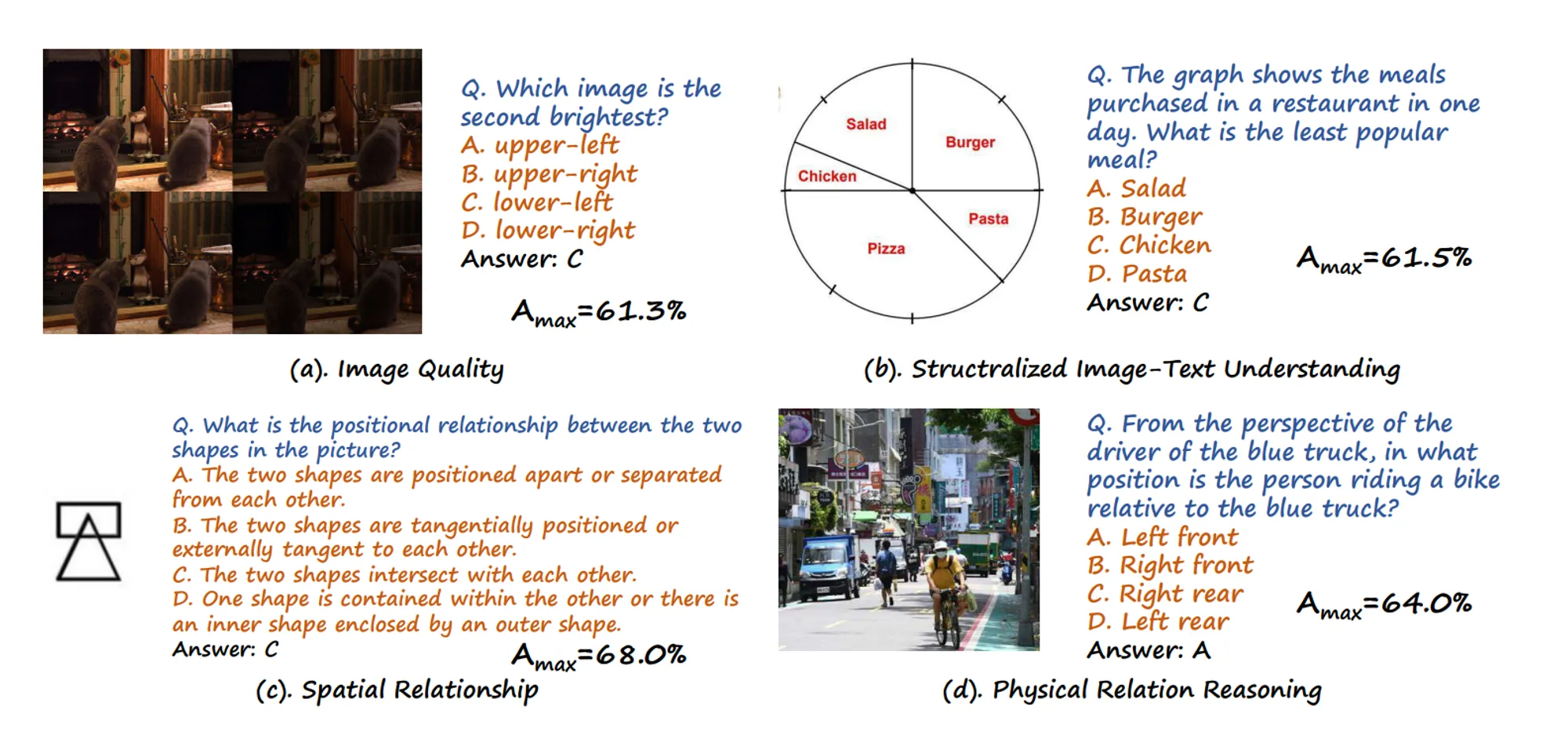
Example questions from the MMBench Benchmark
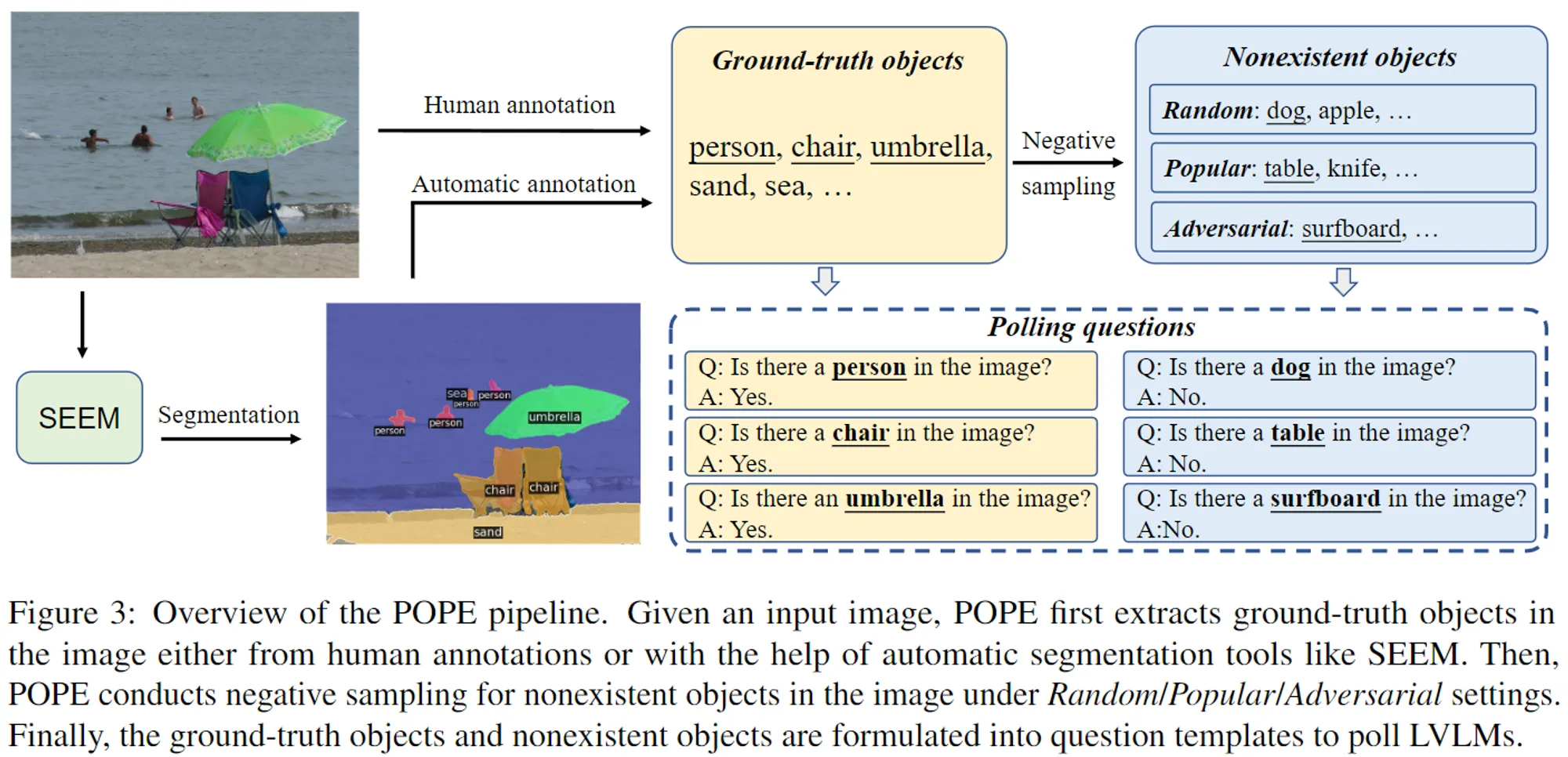
- Pope [8]: Pope is a VQA dataset to probe LLMs for object hallucination in visual LLMs.
- GQA [9]: A large-scale visual question answering dataset with real images from the Visual Genome dataset and balanced question-answer pairs. Each training and validation image is also associated with scene graph annotations describing the classes and attributes of those objects in the scene, and their pairwise relations.
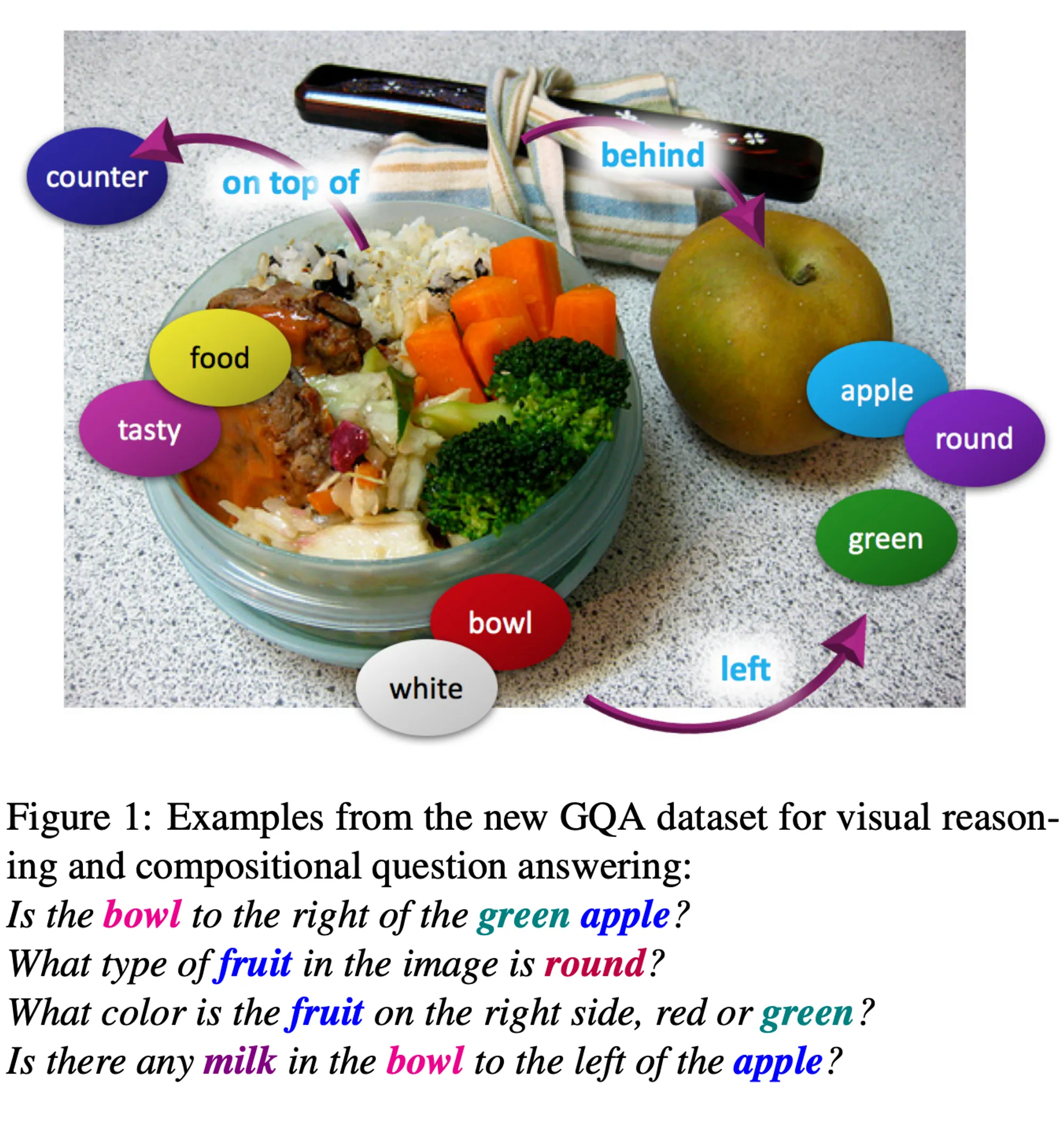
Example of questions from the GQA Benchmark
- GQA (Thai): A Thai-language adaptation (translation) of the GQA benchmark, assessing the model’s performance on visual question answering tasks in Thai.
| Model | MMBench (Dev) | Pope | GQA | GQA (Thai) |
|---|---|---|---|---|
| Typhoon-Vision 8B Preview | 70.9 | 84.8 | 62.0 | 43.6 |
| SeaLMMM 7B v0.1 | 64.8 | 86.3 | 61.4 | 25.3 |
| Bunny Llama3 8B Vision | 76.0 | 86.9 | 64.8 | 24.0 |
| GPT-4o Mini | 69.8 | 45.4 | 42.6 | 18.1 |
Typhoon-Vision demonstrates comparable performance across these benchmarks, particularly excelling in the Thai-specific GQA variant when compared to other available LLMs. It is important to note that Pope and GQA use exact matching for their evaluation while MMBench uses GPT-3.5. This fact may impact the score of GPT-4o Mini on Pope and GQA (as observed in other papers such as Cambrian-1).
4.3 Examples from Typhoon-Vision
Here are a few examples to showcase our model’s performance:
Image Captioning:


Visual Question Answering:




5. Model Specifications and Deployment
Typhoon-Vision can be deployed on hardware with specifications similar to those required for Typhoon 1.5 8B models. The model can run on GPUs with at least 16GB of VRAM. Our model is available on HuggingFace: https://huggingface.co/scb10x/llama-3-typhoon-v1.5-8b-vision-preview.
6. Future Work
Our ongoing research and development efforts for Typhoon-Vision focus on several key areas:
- Vision Encoder Optimization: We plan to fine-tune and potentially replace the current SigLIP encoder to better capture Thai-specific visual elements.
- OCR Enhancement: Improving optical character recognition capabilities for Thai text in images is a priority, with plans to acquire and integrate more Thai OCR data.
- Charts and Infographics Understanding: We aim to enhance Typhoon-Vision’s ability to interpret and answer questions about charts and infographics in Thai. This involves exploring approaches to curate more chart-related data in Thai contexts.
7. Conclusion
Typhoon-Vision represents a significant step forward in multimodal AI for the Thai language. By combining advanced visual processing with a Thai-optimized language model, we have created a powerful tool for Thai-centric visual-language tasks. The model’s strong performance across various benchmarks demonstrates its potential to drive innovation in Thai AI applications.
As we continue to refine and expand Typhoon-Vision’s capabilities, we invite the research community to explore and build upon our work. The model weights are available under the META LLAMA 3 COMMUNITY LICENSE AGREEMENT, fostering open collaboration and further advancements in Thai-centric AI technology.
Appendix
IPU Evaluation: LLM-as-a-Judge Prompt
References
[1] Sigmoid Loss for Language Image Pre-Training, Zhai et al., 2023
[2] Efficient Multimodal Learning from Data-centric Perspective, He et al., 2024
[3] GPT-4o, https://openai.com/index/hello-gpt-4o/, 2024
[4] https://kaggle.com/competitions/ai-cooking-image-captioning, Theerasit et al., 2024
[5] SeaLLMs — Large Language Models for Southeast Asia, Nguyen et al., 2023
[6] The Llama 3 Herd of Models, Dubey et al., 2024
[7] MMBench: Is Your Multi-modal Model an All-around Player?, Liu et al., 2024
[8] Evaluating Object Hallucination in Large Vision-Language Models, Li et al., 2023
[9] GQA: A New Dataset for Real-World Visual Reasoning and Compositional Question Answering, Hudson et al., 2019
