

Language Models are now becoming smaller, more efficient, and easier than ever to run privately on your own computer. LM Studio is a user-friendly tool that lets you load, customize, and chat with models available on Hugging Face entirely on your local machine—no coding, no cloud required.
This blog post aims to be a complete guide to installing LM Studio, choosing the right model format, and getting the most out of local AI with Typhoon models like Typhoon Translate 3B (for text translation), Typhoon OCR 3B (for vision-based text extraction) and Typhoon-2.1-Gemma (for general purpose).
What is LM Studio?
LM Studio is a free, cross-platform desktop app for running open-weight language models locally. It offers:
- 🖥️ A simple ChatGPT-style interface
- 📥 Built-in model discovery and download
- 🔌 An OpenAI-compatible local API server
- ⚙️ Advanced runtime settings (context length, GPU offloading, sampling parameters)
- 🧩 Support for text-only and vision-enabled models (via GGUF)
System Requirements
MacOS
- Chipset: Apple Silicon (M1, M2, M3, M4)
- OS: macOS 13.4 or newer (14+ recommended)
- RAM: 16 GB recommended (8 GB is enough for small models)
⚠️ Intel-based Macs are not supported.
Windows
- CPU: AVX2 instruction set (x64)
- RAM: At least 16 GB recommended
Linux
- OS: Ubuntu 20.04 or newer (minor issues possible on 22+)
- Architecture: x64 only
Getting Started with LM Studio
1️⃣ Download and Install
- Get LM Studio here: https://lmstudio.ai/download
- Follow the installation instructions for your OS
2️⃣ Download an LLM
LM Studio supports multiple file formats and quantized variants. Choose the right one based on your hardware and needs:
Model File Formats
| Format | Best For | Pros | Cons | Platforms |
|---|---|---|---|---|
| GGUF | Universal, most models | Cross-platform, supports vision | Slightly larger on disk | Windows, macOS (Intel & Apple Silicon), Linux |
| MLX | Apple Silicon only | Optimized for M1/M2/M3 GPUs | Apple-only, text-only for now | macOS (M1/M2/M3/M4) |
GGUF is recommended for most users, especially for non-text models like Typhoon OCR 3B.
MLX is best on Apple Silicon for text-only models, with faster performance.
📥 How to Get a Model
-
Use LM Studio's Discover tab to search and download directly

Example: Search for Typhoon Translate in LM Studio's Discover tab -
Or download from external links (like Hugging Face)
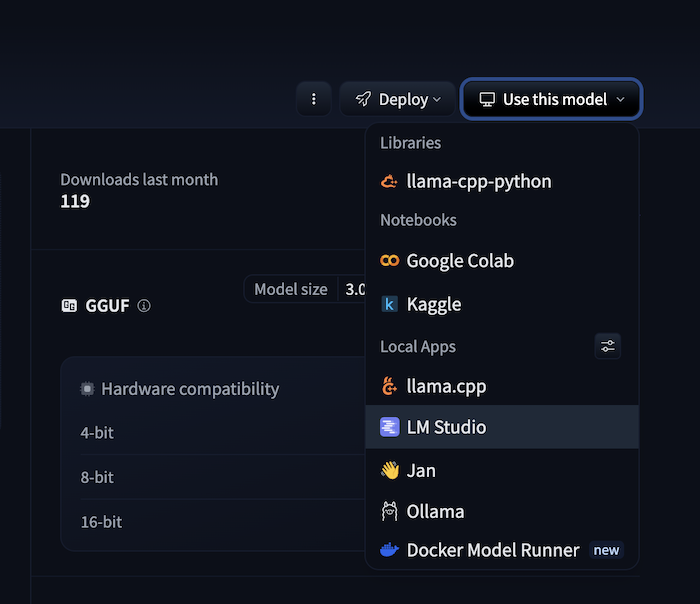
You can browse models on Hugging Face. For example, Typhoon OCR is one of the Hugging Face collections of Typhoon models. You can find typhoon-ocr-7b and typhoon-ocr-3b in a standard format which you can use with Transformer library, Google Collab, or vLLM. You can also find our recent GGUF format for 3b model here: https://huggingface.co/scb10x/typhoon-ocr-3b-gguf this format is recommended when using with LM Studio.
At the model page, select 'Use this model' then select 'LM Studio'. If you don't see the option, make sure to enable it at https://huggingface.co/settings/local-apps#local-apps
- Or you can download as a file and import your '.mdx' or '.gguf' files into LM Studio directly.
4️⃣ Set Your System Prompt
- Go to My Models > click ⚙️ Settings next to your model
- Under Prompt tab, set a custom system prompt
Example: You are a female AI assistant named Typhoon created by SCB 10X to be helpful, harmless, polite, and honest...
5️⃣ [Optional] Tweak Inference Settings
You can adjust parameters such as:
- Context length
- GPU offload
- Batch size, threads
- Sampling temperature/top-p
These settings help balance speed, memory use, and response quality.
Choosing the Right Typhoon Model Size
Typhoon models come in multiple sizes (e.g., 1B, 3B, 4B, 7B, 8B, 12B).
“B” = billions of parameters.
More parameters generally mean better reasoning and context handling—but also higher memory and compute requirements.
Choosing a model size
- 1–3B models: Best for short translations, basic OCR, single-turn Q&A. Runs on 8–16 GB RAM systems.
- 4B–8B models: Balance quality and resource use. Handle richer multilingual text, longer documents. Plan for 16–32 GB RAM and 6–12 GB GPU VRAM.
- 12B models: Best for research-grade summarization, advanced multi-turn chats. Need 32 GB+ RAM or gamer GPU.
Best practice: Choose the smallest size that meets your quality needs.
📌 Available Typhoon Model Variants
- Typhoon 2.1 Gemma: 4B, 12B
- Typhoon 2: 1B, 3B, 8B
- Typhoon OCR: 3B, 7B
- Typhoon Translate: 4B
💬 Chat with Your LLM
For text models like Typhoon 2.1 Gemma or Typhoon Translate, LM Studio's chat interface is very simple:
- Go to the Chat tab
- Create a new chat
- Select the loaded model
- Type your prompt and get a response
Example:
I asked Typhoon Translate to help translate this section into Thai.

🖼️ Using Typhoon OCR 3B (Vision Model) via API
LM Studio's chat UI doesn't support image upload yet, but you can use Typhoon OCR 3B via its local OpenAI-compatible API.
⚠️ Important Update on Using Typhoon OCR 3B (Vision Model) Locally
Update on July 15, 2025
We’ve tested our current quantized (.gguf) version of the Typhoon OCR 3B model in LM Studio and found that accuracy is significantly reduced compared to the original model.
✅ Our recommendation:
-
Avoid using the .gguf quantized model for OCR tasks for now. We’re working on improving the quantization and alignment for better OCR accuracy in future releases.
-
If you need to run Typhoon OCR locally today.
We suggest using Ollama as your backend instead of LM Studio as it does not rely on the .gguf model that we're currently fixing.
In our tests, OCR accuracy was higher using the unquantized or better-optimized variants in Ollama. It also supports easy setup on macOS, Windows, and Linux.
Conclusion
LM Studio makes running advanced AI models locally easy, private, and efficient. Whether you want to translate text with Typhoon Translate, extract text from images with Typhoon OCR, or chat with other Typhoon variants, this guide should help you get up and running.
Appendix
The following instructions remain here for your future reference to use OCR API with LM Studio. Once we release an updated, better-quantized GGUF model with improved OCR accuracy, you can use LM Studio’s local API exactly as described.
For now, though, we do not recommend using this method for production or critical OCR tasks.
How to Use OCR API with LM Studio
-
Load the Typhoon OCR 3B .gguf model in LM Studio
-
LM Studio’s API will automatically be available at:
http://localhost:1234/v1 -
(First-time requirement) Install the OpenAI Python package:
pip install openai -
Write a Python script to work with the API. You can send base64-encoded images as input via the API.
Here’s a minimal working example in Python:
LM Studio will process the image and return extracted text locally.

