

Today, we are pleased to introduce our collaborative research artifact, Typhoon-Si-Med-Thinking-4B. Although the model is only 4B parameters, it delivers state-of-the-art results across several English medical QA benchmarks (MedQA, MedMCQA, MedXpertQA, MMLU-Pro Health) and surpasses larger models like Gemini 2.5 Pro when evaluated on ranked-list medical reasoning.
Beyond its performance, Typhoon-Si-Med-Thinking-4B is a first-of-its-kind medical-reasoning model optimized for generating ranked lists—an important step toward exploring AI systems that mirror how clinicians consider multiple possibilities in real practice.
Rethinking What Medical Reasoning Models Should Do
Most open-source medical reasoning models today are built and evaluated around a single dominant benchmark style: multiple-choice medical exams. But excelling at MCQs (multiple-choice questions) doesn’t necessarily translate into strong performance when the answer format becomes more open-ended or when clinicians need “ranked differential diagnoses” rather than a single “best” answer.
In real clinical practice, medical reasoning rarely ends with one definitive answer. Clinicians consider several differential diagnoses, weigh alternative treatments, and continually revise their thinking. They want systems that can show possibilities, not commit prematurely to a single prediction.
This collaboration between Typhoon (SCB 10X) and SiData+ (Siriraj Hospital, Mahidol University) explores a different direction: Can a small model be taught to produce ranked lists of plausible medical answers—reflecting real clinical reasoning—and can such a model outperform larger models designed for single-answer tasks?
The result is Typhoon-Si-Med-Thinking-4B (Research Preview), a 4B-parameter model designed to answer in list form jointly developed by Typhoon and SiData+.
Why Ranked-List Reasoning Matters
Clinical reasoning rarely ends with a single “correct” answer. In practice, clinicians weigh multiple possibilities—differential diagnoses, treatment options, and management plans—before deciding how to proceed. Yet most medical reasoning models (MRMs) today are trained and evaluated as if there were only one right answer. This single-answer paradigm simplifies evaluation but risks misrepresenting how medical decisions are actually made.
Our model introduces a new approach: enabling MRMs to generate ranked lists of plausible answers for open-ended clinical questions. Rather than forcing a model to commit to one output, ranked lists better reflect diagnostic uncertainty and can help clinicians reason collaboratively with AI systems. For instance, when a model suggests several possible causes for a symptom, clinicians can more easily compare, cross-check, and challenge its reasoning.

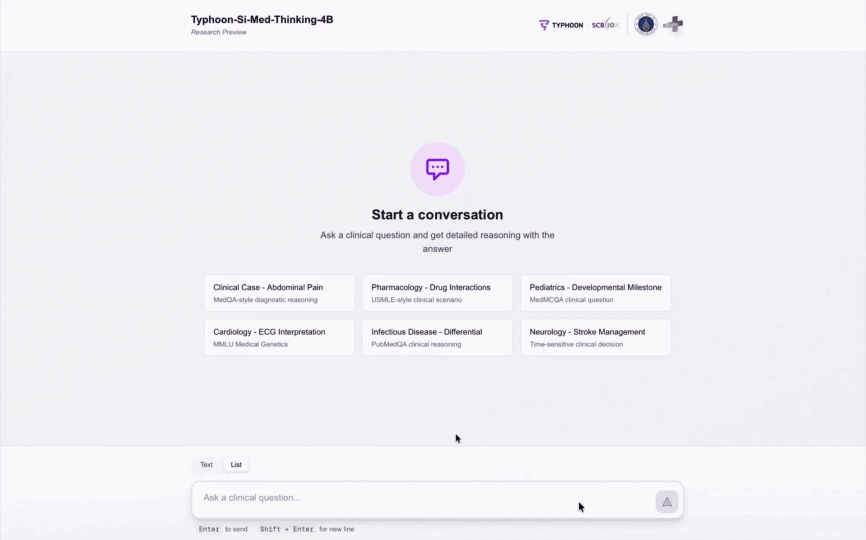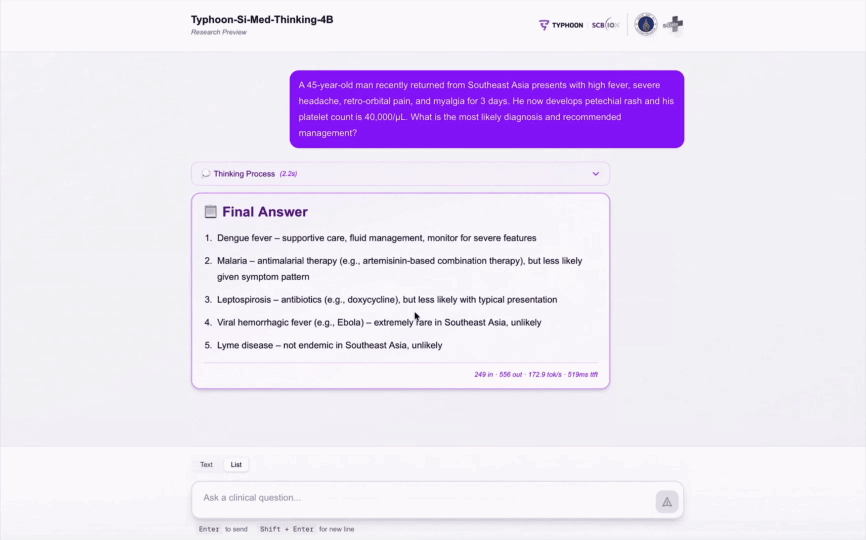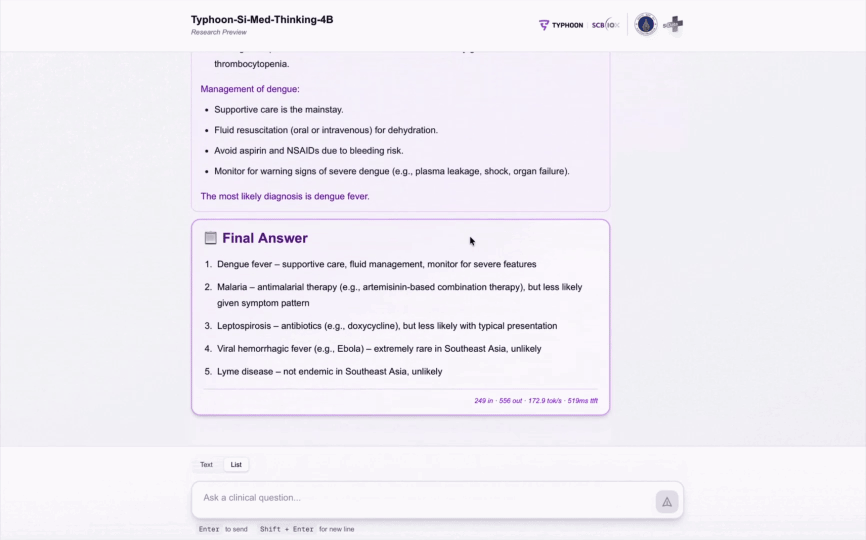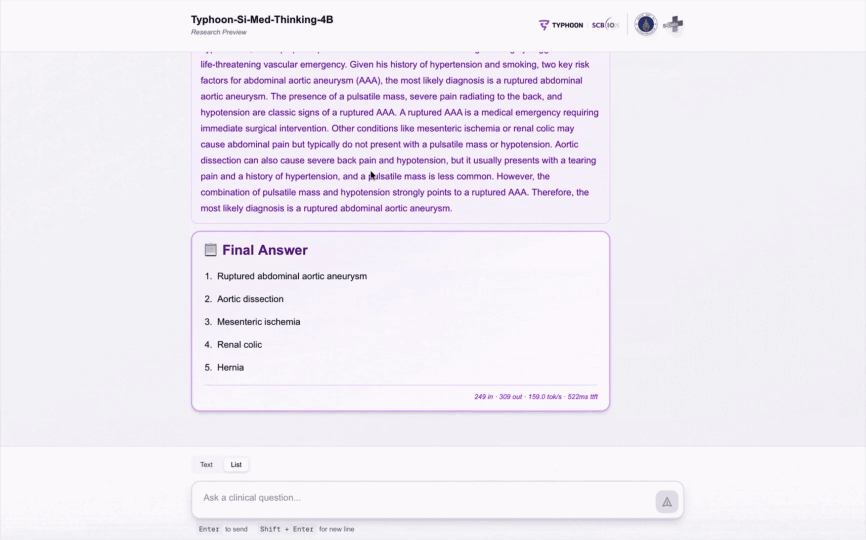
Model Demo
How the Model Learns to Rank: Reinforcement Fine-Tuning (RFT)
Traditional supervised fine-tuning (SFT) teaches models to imitate fixed input–output pairs. In contrast, reinforcement fine-tuning (RFT) trains a model to optimize for behavior—in our case, producing high-quality, well-ranked lists of medical answers. Rather than memorizing examples, the model learns through reward signals that guide it toward preferred responses, balancing correctness, diversity, and clarity. We trained Typhoon-Si-Med-Thinking-4B from the base model Qwen3-4B-Instruct-2507 using:
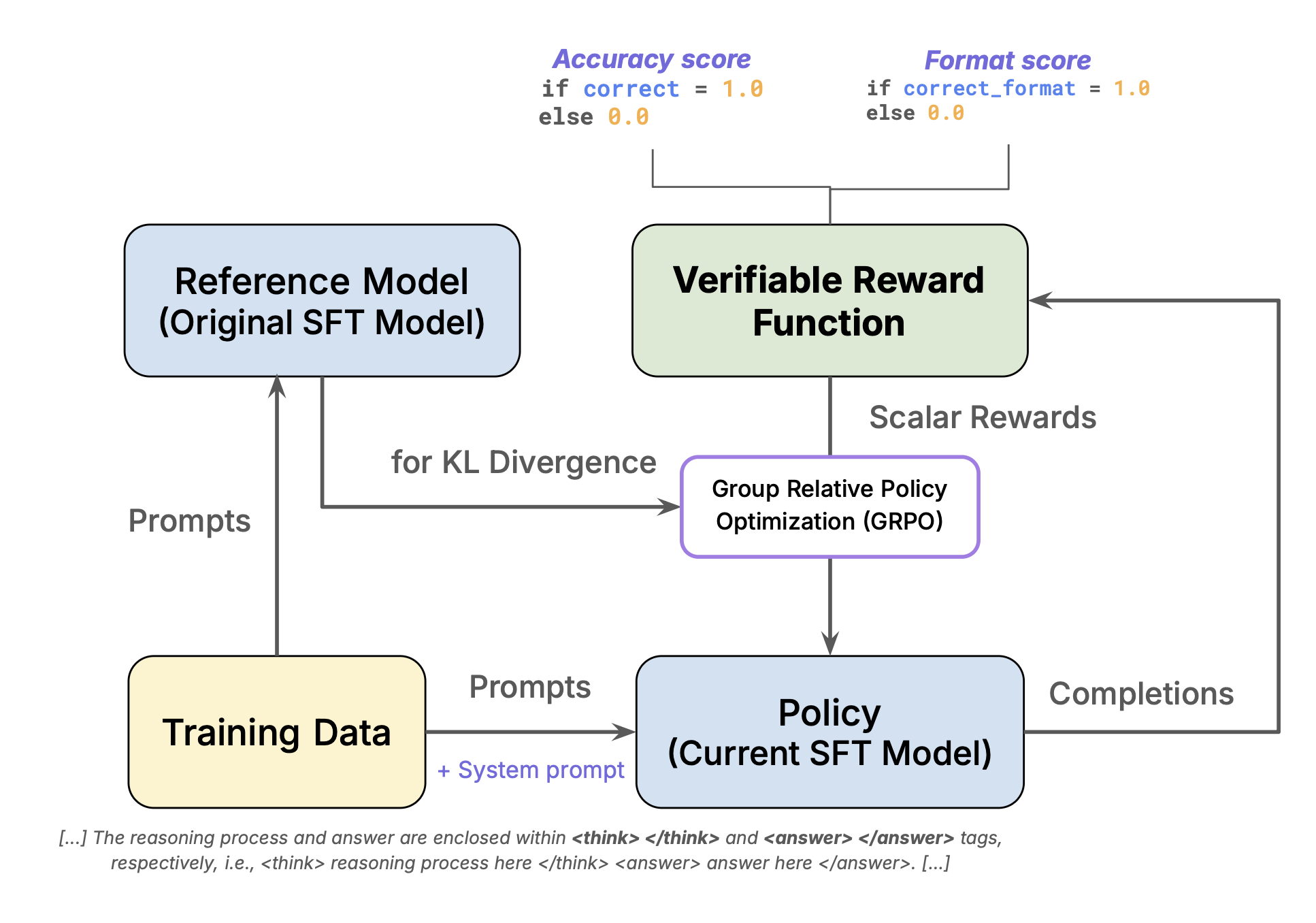
- Correctness rewards (matching ground truth)
- Format rewards (clean reasoning structure within
<think>and<answer>tags) - MRR-style rank rewards (placing correct answers higher)
- Judge-MRR using an external LLM to recognize synonyms and medically equivalent terms
Reward Design: Teaching the Model What “Good” Looks Like

The reward function is the core of the RFT process—it tells the model when it has produced a useful, well-structured answer. We designed a composite reward with two key components:
- Correctness reward – Ensures factual accuracy. For multiple-choice and short-answer questions, the model is rewarded when its prediction matches the ground truth. For ranked lists, the model receives partial credit when the correct answer appears anywhere in the list.
- Format reward – Encourages clean, interpretable outputs. This verifies that the model structures its reasoning within designated tags, maintaining consistent reasoning traces.
To make the model rank-aware, we introduced a Mean Reciprocal Rank (MRR)–inspired reward that encourages correct answers to appear higher in the list—mirroring how clinicians naturally prioritize differential diagnoses. We further implemented this as a Judge-MRR reward, where an LLM (Gemini 2.5 Flash) serves as a semantic evaluator, assessing how closely each generated answer matches the ground truth in meaning. This allows the system to recognize equivalent medical terms (e.g., “heart attack” and “myocardial infarction”) and provide a more reliable signal for both accuracy and ranking quality.
What We Found: A Small Model That Punches Above Its Weight
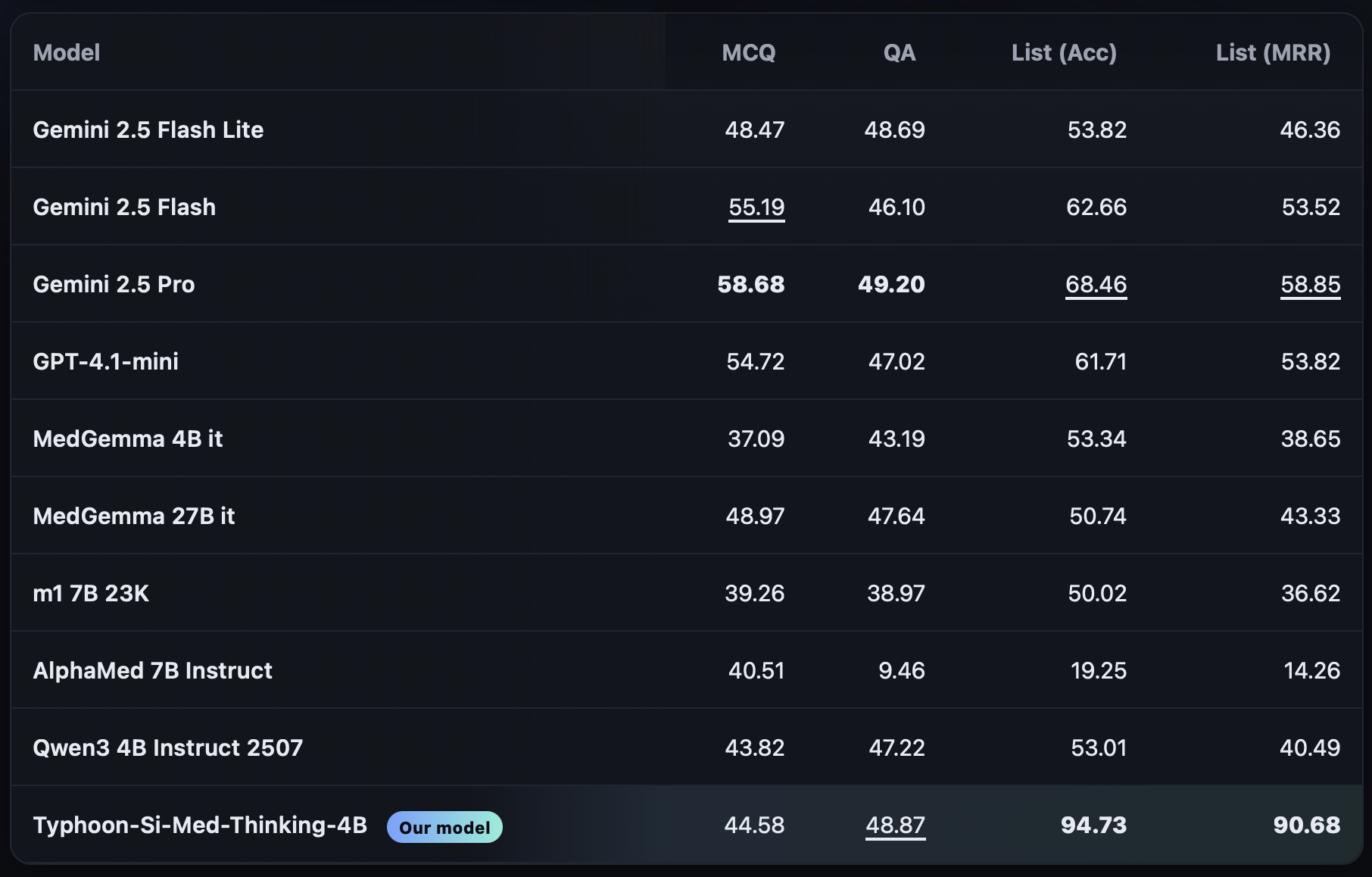
Despite having only 4 billion parameters, Typhoon-Si-Med-Thinking-4B achieves state-of-the-art performance, even outperforming much larger models like Gemini 2.5 Pro on key medical benchmarks. While Gemini 2.5 Pro leads slightly in general QA and multiple-choice tasks, Typhoon-Si-Med-Thinking-4B dominates in structured reasoning metrics, reaching 94.73 accuracy and 90.68 MRR in list evaluation, compared to Gemini’s 68.46 and 58.85, respectively.
This remarkable performance highlights how a smaller, well-optimized model can surpass larger systems when fine-tuned for specialized reasoning tasks. The model’s success stems from frontier insights that enhance its ability to reason and rank.
Building the Future of Medical AI Together

What makes Typhoon-Si-Med-Thinking-4B meaningful is not the model alone, but the collaboration behind it. Typhoon (SCB 10X) brought expertise in model training, reinforcement learning, and research experimentation, while SiData+ contributed deep clinical understanding, grounding every decision in the realities of medical practice.
Together, we explored a new research question—how to train AI systems that can reason in richer, more clinically relevant formats. The result is a research preview that illustrates how technological innovation and medical knowledge can amplify each other. This partnership is helping shape an emerging ecosystem of medical AI that is rigorous, locally meaningful, and centered on human-aligned reasoning.
Where the Research Community Can Take This Next
We hope this project invites further exploration into:
- How different answer formats affect performance of reasoning models
- How reinforcement learning techniques can improve clinical reasoning models
- How small, efficient models can be used for specialized tasks
- How to evaluate ranked-list medical reasoning more rigorously
This is only the beginning. There is immense room for further work and we welcome researchers to build on these ideas.
This Is a Research Preview, Not a Clinical Model
To ensure clarity and responsible communication:
- We’d like to emphasize that Typhoon-Si-Med-Thinking-4B is a research artifact.
- It has not been evaluated for safety, guardrails, hallucination risks, or deployment reliability.
- It must not be used for diagnosis, patient interaction, or medical decision-making.
- The model was never trained on Thai medical data and is not yet intended for Thai-language use.
We explore how performance changes when models must produce ranked lists rather than single answers. Our goal is to share findings and open research questions for future research initiatives.
Explore the Work
We invite researchers, clinicians, and students to read the paper closely and explore the work—responsibly, critically, and with the understanding that this model is strictly for research, not real-world medical use.
- 📄 Paper: arXiv:2509.20866 for full methodology, experiments, and ranking analysis
- 🧠 Model: Typhoon-Si-Med-Thinking-4B (Research Preview) for research and reproducibility
- 📚 Data: Datasets all publicly available English-language sources used in training
- Organizations:
- 🌪️ Typhoon (SCB 10X): opentyphoon.ai
- 🏥 SiData+ / Siriraj Hospital: si.mahidol.ac.th/data

