

At Typhoon, we care deeply about making Thailand a better place through world-class AI. We believe that for AI to truly serve our community, it must master the unique nuances of our language and culture—from the complexity of Thai script to the regional accents and dialects—all while remaining as efficient as possible.
Our mission goes beyond simply releasing a high-performing model; we believe in the power of open knowledge. As the saying goes, "teaching people how to fish is far more valuable than simply handing them a fish." By sharing our findings, we aim to empower the entire community to grow and innovate together.
Today, we are thrilled to release the technical reports for two of our most impactful models: Typhoon ASR and Typhoon OCR. These reports represent more than just benchmarks; they offer a transparent look into our techniques, our challenges, and the critical insights we gained while building production-grade AI models for Thailand.
TL;DR
We’re releasing the methodologies behind Typhoon ASR Real-time (streaming Thai ASR) and Typhoon OCR v1.5 (structured Thai document extraction). These reports share the data curation, normalization, architecture choices, and training recipes we used to move from research-grade results to production reliability—plus benchmarks and artifacts to help the community evaluate and build. By sharing our knowledge here, we aim to empower the Thai developer community to build even better systems.
Technical Reports, Model Weight & Artifacts
-
Typhoon ASR: Paper | Model and Dataset Artifacts
Typhoon ASR Real-time: FastConformer-Transducer for Thai Automatic Speech Recognition
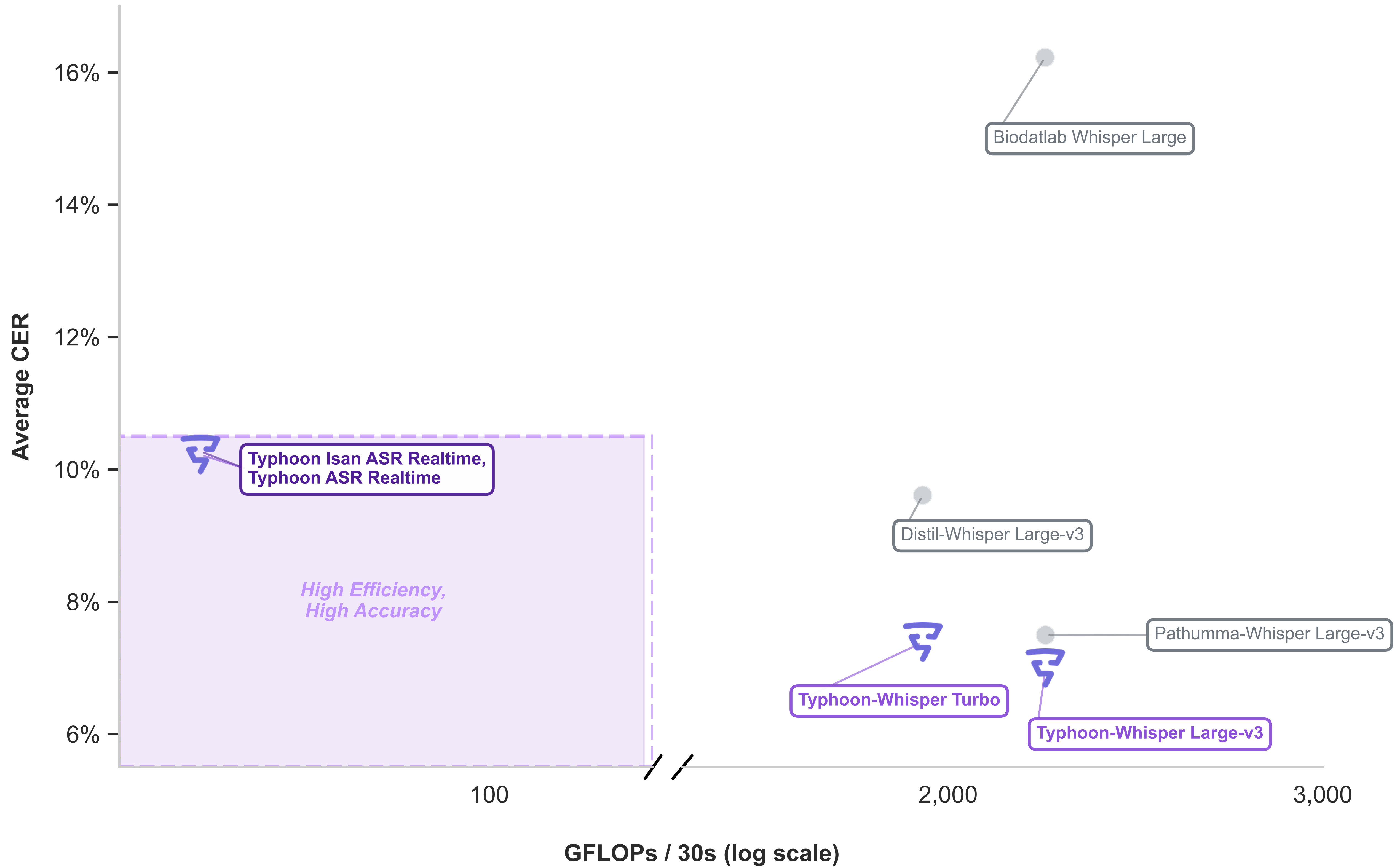
While models like Whisper provide high accuracy, they are often impractical for the real-time, low-latency needs of production environments. Our work on Typhoon ASR Real-time addresses the critical gap in efficient streaming solutions for the Thai language. This enables real-time captioning, call center transcription, and voice agents with predictable latency and lower compute.
Key Insights & Breakthroughs:
- The Power of Normalization: We discovered that rigorous text normalization—standardizing how numbers and repetition markers (ๆ) are transcribed—can rival the gains you’d typically expect from scaling.
- Massive Efficiency Gains: By choosing a FastConformer-Transducer architecture over standard encoder-decoders, we achieved a 45x reduction in computational cost compared to Whisper Large-v3, while maintaining comparable accuracy.
- Solving the Dialect Gap: We introduced a two-stage curriculum learning strategy for Isan dialect adaptation. This allowed the model to specialize in regional linguistic patterns without "catastrophic forgetting" of Central Thai.
- Standardizing Evaluation: To help the community, we are releasing the Typhoon ASR Benchmark and TVSpeech, human-labeled datasets designed to test models in acoustically complex, real-world environments.
Typhoon OCR: Open Vision-Language Model For Thai Document Extraction
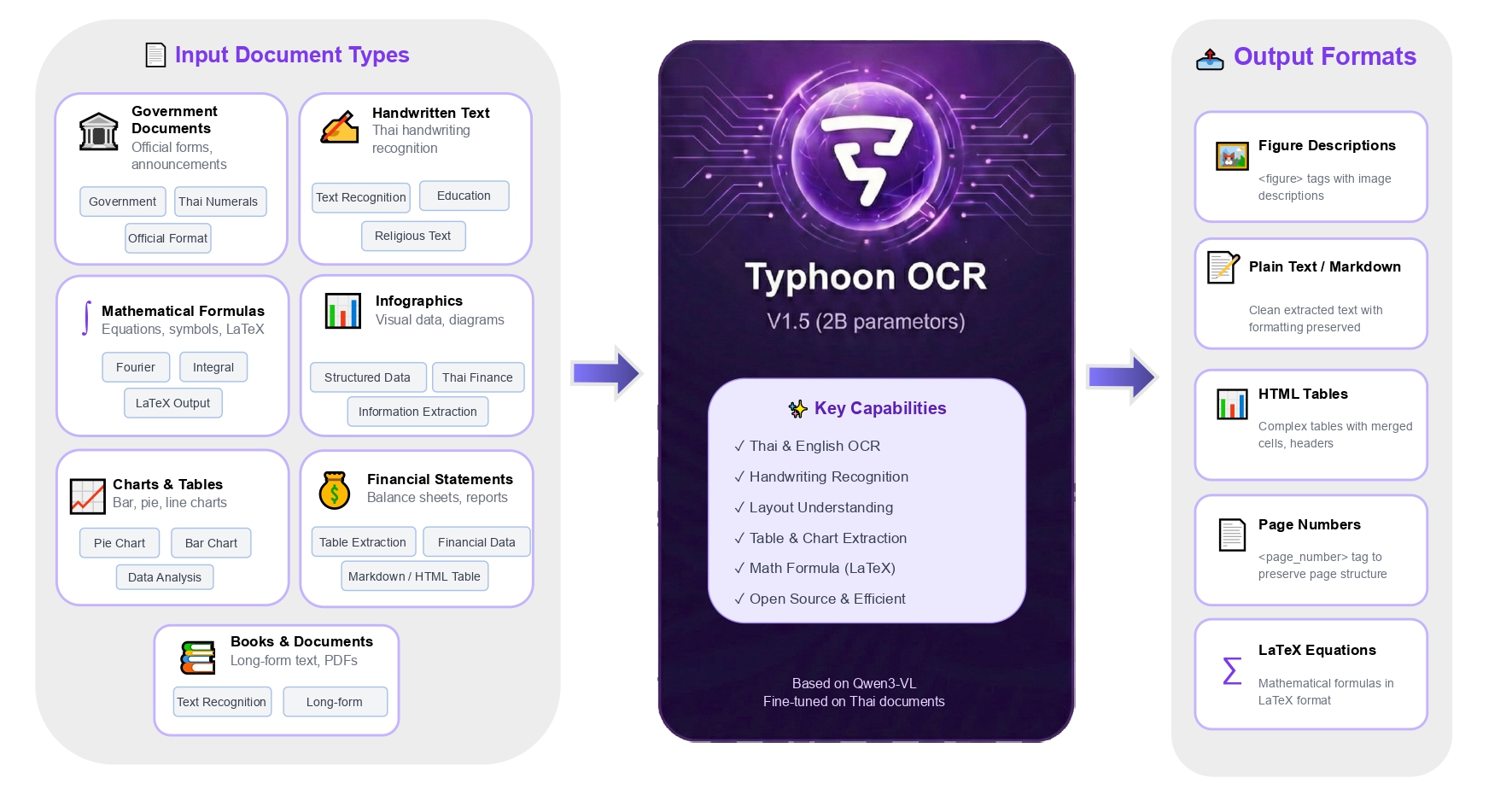
Thai documents present a unique challenge due to their distinct script and layout complexity. With stacked diacritics and a lack of explicit word boundaries, traditional OCR systems often fail on dense forms and financial reports. Typhoon OCR was built to understand the structure of a document, not just the text. This enables use cases such as invoice/statement extraction, form automation, and searchable document repositories where structure matters—not just raw text.
Key Insights & Breakthroughs:
- Agentic Data Pipeline with Human-in-the-Loop: We employ an agentic, multi-step data curation pipeline that combines traditional OCR and vision-language models (VLMs), with human verification at critical stages. This process filters and refines raw outputs to ensure only the highest-quality annotations are used for training.
- V1.5: Smaller, Faster, Smarter: While our V1 (7B) model set the stage, Typhoon OCR V1.5 (2B) proves that data quality beats model size. It is more compact and metadata-independent, meaning it can reconstruct layouts directly from images without requiring the original PDF text layer.
- Scalable Synthetic Data Generation: To address the limited availability of labeled Thai data, we developed a scalable, multi-stage synthetic data generation pipeline. Using Augraphy, we simulate real-world document artifacts—such as motion blur and poor lighting—to expand coverage and improve robustness on noisy, real-world captures.
Advancing Together
We believe that when the community advances, everyone benefits. By sharing these reports and models, we aim to build a stronger Thai AI ecosystem through collective feedback and innovation.
Start building with Typhoon today. We invite you to explore our models, push their boundaries, and share your work with the community. Your insights help us all move forward.
-
Typhoon ASR Real-time: ArXiv | Hugging Face
-
Typhoon OCR V1.5: ArXiv | Hugging Face

