

ที่ Typhoon เรามุ่งมั่นที่จะช่วยพัฒนาประเทศไทยให้ดีขึ้นด้วย AI คุณภาพระดับสากล เราเชื่อว่า AI จะสร้างคุณค่าให้กับสังคมได้อย่างแท้จริงก็ต่อเมื่อมันเข้าใจความละเอียดอ่อนเฉพาะของภาษาและวัฒนธรรมไทย ตั้งแต่ความซับซ้อนของอักษรไทย ไปจนถึงสำเนียงและภาษาถิ่นในแต่ละภูมิภาค โดยยังคงต้องมีประสิทธิภาพและใช้ทรัพยากรอย่างคุ้มค่า
ภารกิจของเราไม่ได้หยุดอยู่แค่การปล่อยโมเดลที่มีประสิทธิภาพสูงเท่านั้น แต่เรายังเชื่อในพลังของ “ความรู้แบบเปิด” ดังคำกล่าวที่ว่า "การสอนคนจับปลามีค่ามากกว่าการหยิบปลาให้" การแบ่งปันสิ่งที่เราค้นพบนี้ เราหวังว่าจะช่วยเสริมพลังให้ชุมชนทั้งหมดเติบโตและสร้างนวัตกรรมไปด้วยกัน
วันนี้เราภูมิใจที่จะเปิดตัวรายงานเทคนิคของโมเดลสองตัวที่สร้างอิมแพคที่สุดของเรา ได้แก่ Typhoon ASR และ Typhoon OCR รายงานเหล่านี้ไม่ได้เป็นเพียงการโชว์ตัวเลข benchmark แต่เป็นการเปิดเผยกระบวนการ เทคนิค ความท้าทาย และบทเรียนสำคัญจากการสร้าง AI ภาษาไทยที่พร้อมใช้งานจริงในระดับ production
สรุปสาระสำคัญ (TL;DR)
เรากำลังเปิดเผยระเบียบวิธีวิจัยเบื้องหลัง Typhoon ASR Real-time (ระบบรู้จำเสียงภาษาไทยแบบสตรีมมิ่ง) และ Typhoon OCR v1.5 (ระบบสกัดข้อมูลเอกสารไทยที่มีโครงสร้าง) รายงานเหล่านี้แชร์ทั้งเรื่องการคัดกรองข้อมูล (Data Curation), การจัดการข้อมูลให้เป็นมาตรฐาน (Normalization), การเลือกโครงสร้างโมเดล (Architecture) และสูตรการฝึกฝน (Training Recipes) ที่เราใช้เพื่อยกระดับจากผลงานวิจัยไปสู่ความน่าเชื่อถือในระดับใช้งานจริง พร้อมด้วย Benchmark และ Artifact ต่างๆ เพื่อช่วยให้ชุมชนสามารถนำไปประเมินและต่อยอดได้ เรามุ่งหวังที่จะช่วยให้ทีมนักพัฒนาไทยสามารถสร้างระบบที่ดีขึ้นกว่าเดิม
รายงานเทคนิค, Model Weight และ Artifacts
-
Typhoon ASR: Paper | Model and Dataset Artifacts
Typhoon ASR Real-time: FastConformer-Transducer สำหรับการรู้จำเสียงภาษาไทย
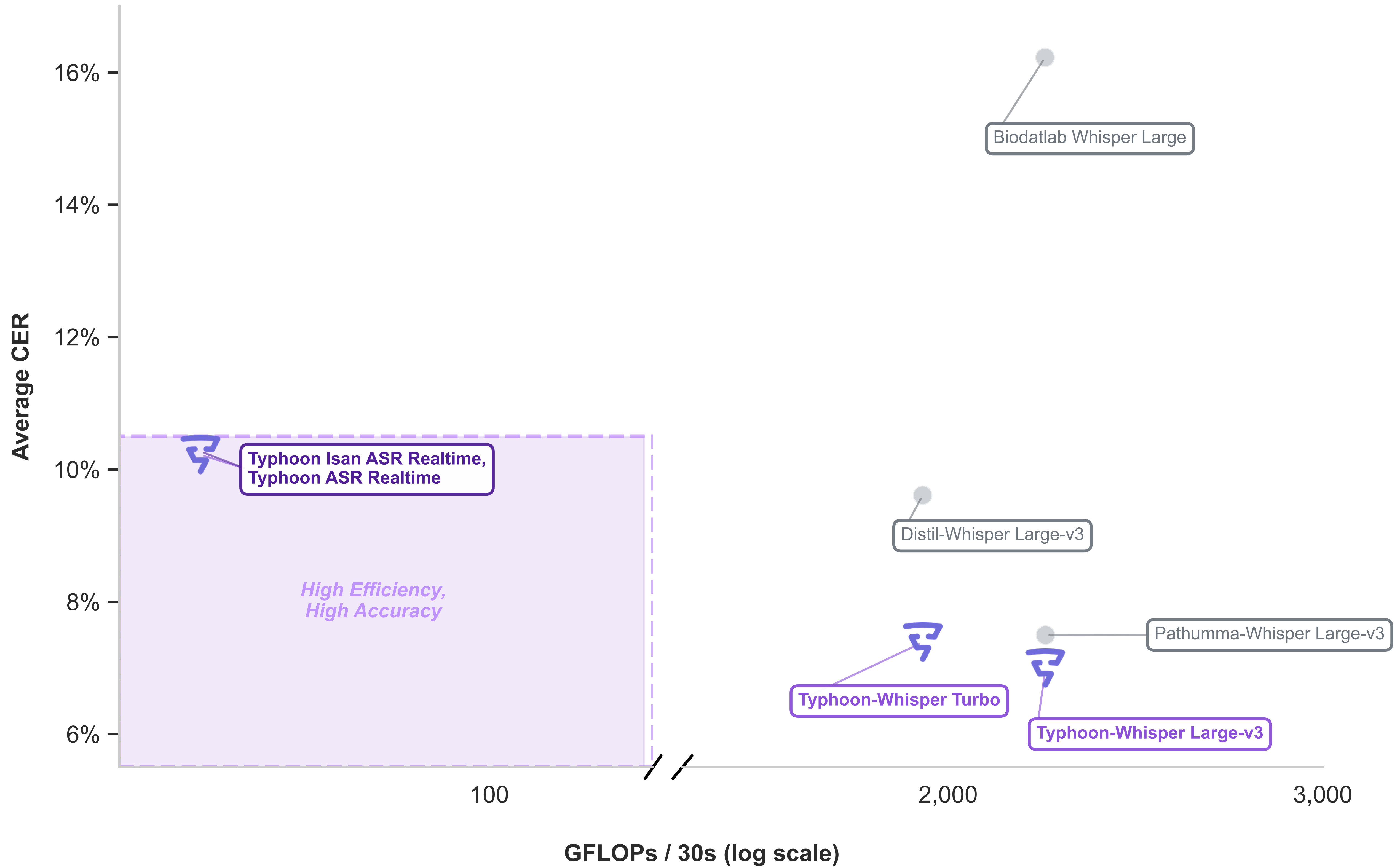
แม้โมเดลอย่าง Whisper จะมีความแม่นยำสูง แต่ในหลายกรณีกลับไม่เหมาะกับสภาพแวดล้อมการใช้งานจริงที่ต้องการ latency ต่ำและการประมวลผลแบบเรียลไทม์ งานของเราใน Typhoon ASR Real-time จึงมุ่งแก้ปัญหาช่องว่างสำคัญนี้ เพื่อให้ได้โซลูชัน streaming สำหรับภาษาไทยที่มีประสิทธิภาพ รองรับการใช้งานอย่างคำบรรยายสด การถอดเสียงคอลเซ็นเตอร์ และ voice agent ที่ต้องการ latency ที่คาดเดาได้และต้นทุนการคำนวณที่ต่ำกว่า
Insight และความก้าวหน้าที่สำคัญ
- พลังของ Normalization
เราพบว่าการทำ text normalization อย่างเข้มข้น เช่น การมาตรฐานการเขียนตัวเลข และมาตรฐานการใช้ไม้ยมก (ๆ) ที่สม่ำเสมอ สามารถให้ผลลัพธ์ใกล้เคียงกับการเพิ่มขนาดโมเดลอย่างมีนัยสำคัญ
- ประสิทธิภาพที่เพิ่มขึ้นอย่างมหาศาล
ด้วยการเลือกสถาปัตยกรรม FastConformer-Transducer แทน encoder-decoder แบบดั้งเดิม เราลดต้นทุนการคำนวณได้ถึง 45 เท่า เมื่อเทียบกับ Whisper Large-v3 โดยยังคงความแม่นยำในระดับใกล้เคียงกัน
- แก้ปัญหาภาษาถิ่นอย่างเป็นระบบ
เราใช้กลยุทธ์ curriculum learning แบบสองขั้นตอนสำหรับการเรียนรู้ภาษาอีสาน ช่วยให้โมเดลปรับตัวและเรียนรู้รูปแบบทางภาษาของภูมิภาคได้โดยไม่เกิดปัญหา catastrophic forgetting กับภาษาไทยกลาง
- มาตรฐานการประเมินที่ชัดเจน
เพื่อประโยชน์ของชุมชน เราเปิดตัว Typhoon ASR Benchmark และ TVSpeech ซึ่งเป็นชุดข้อมูลที่ทีมงานคนไทยของเราทำ annotation เองเพื่อทดสอบโมเดลในสภาพแวดล้อมจริงที่มีความซับซ้อนทางเสียง
Typhoon OCR: Vision-Language Model แบบเปิด สำหรับการดึงข้อมูลจากเอกสารภาษาไทย
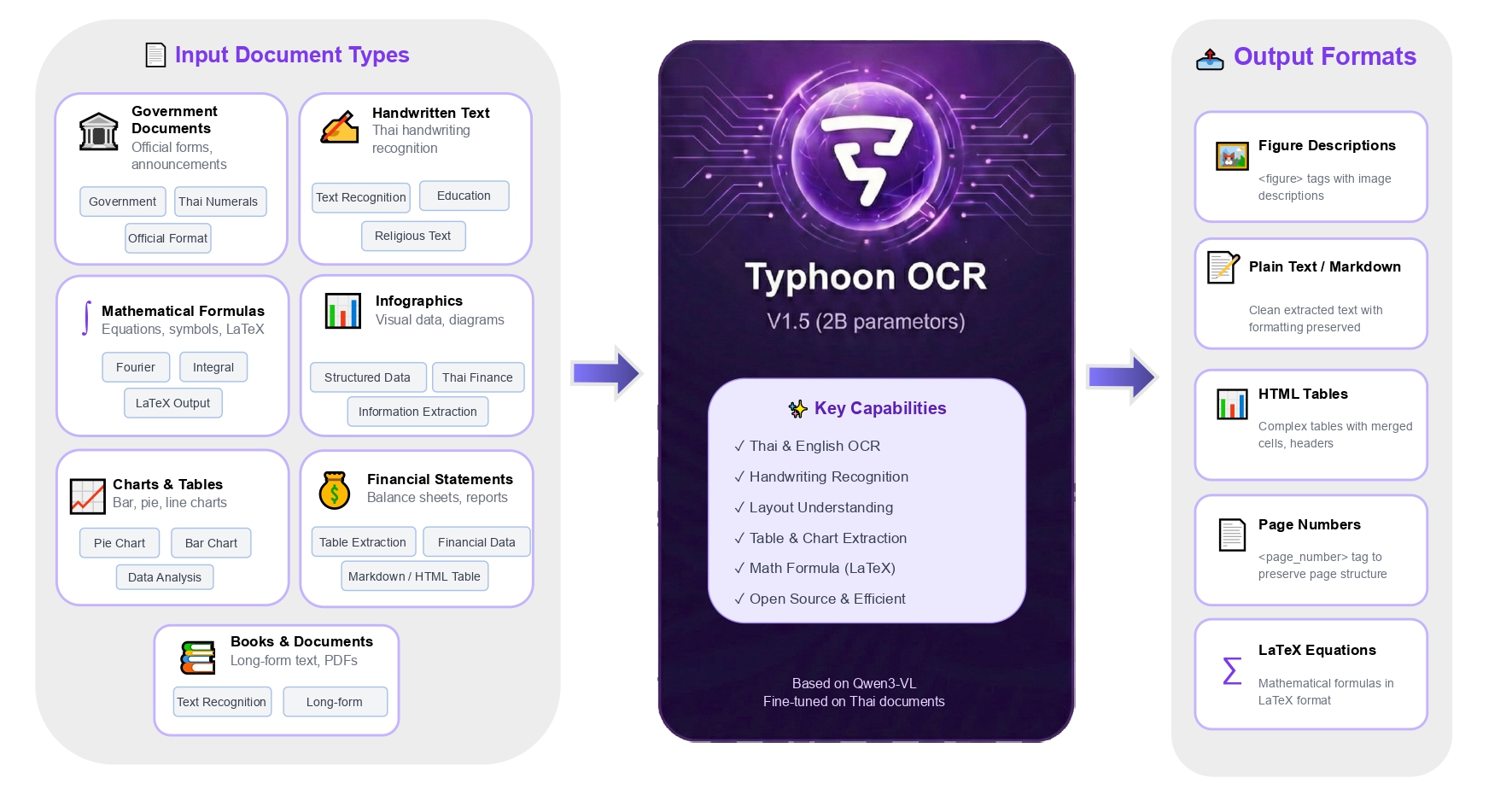
เอกสารภาษาไทยมีความท้าทายเฉพาะตัว ทั้งรูปแบบอักษร การวาง layout ที่ซับซ้อน การซ้อนของวรรณยุกต์ และการไม่มีช่องว่างระหว่างคำหรือประโยคที่ชัดเจน ระบบ OCR แบบดั้งเดิมจึงมักล้มเหลวเมื่อเจอกับฟอร์มแน่นๆ หรือรายงานทางการเงิน Typhoon OCR จึงถูกออกแบบมาเพื่อ “เข้าใจโครงสร้างของเอกสาร” ไม่ใช่แค่อ่านข้อความ ทำให้รองรับ use case อย่างการดึงข้อมูลใบแจ้งหนี้/statement การทำเอกสารอัตโนมัติ และคลังเอกสารที่ค้นหาได้โดยโครงสร้างมีความสำคัญ
Insight และความก้าวหน้าที่สำคัญ
- Agentic Data Pipeline พร้อม Human-in-the-Loop
เราผสานทั้ง OCR แบบดั้งเดิมและ VLM เข้ากับกระบวนการหลายขั้นตอนที่มีมนุษย์ตรวจสอบ เพื่อให้ได้ข้อมูลฝึกที่มีคุณภาพสูงสุดก่อนนำไปเทรนโมเดล
- Typhoon OCR V1.5: เล็กกว่า เร็วกว่า และฉลาดกว่า
จาก V1 ขนาด 7B ที่ปูทางไว้ Typhoon OCR V1.5 ขนาด 2B แสดงให้เห็นว่าคุณภาพข้อมูลสำคัญกว่าขนาดโมเดล โมเดลใหม่นี้มีขนาดเล็กลง และไม่พึ่งพา metadata ทำให้สามารถสร้าง layout ได้โดยตรงจากภาพ โดยไม่ต้องอาศัย text layer ของ PDF ต้นฉบับ
- พลังของข้อมูลสังเคราะห์
เพื่อแก้ปัญหาข้อมูลภาษาไทยที่มีจำกัด เราสร้าง pipeline สำหรับ synthetic data แบบหลายขั้นตอน รวมถึงการใช้ Augraphy เพื่อจำลอง noise ในโลกจริง เช่น ภาพเบลอจากการเคลื่อนไหว หรือแสงไม่ดี ช่วยเพิ่มความทนทานในการใช้งานจริง
เติบโตไปด้วยกัน
เราเชื่อว่าเมื่อชุมชนก้าวหน้า ทุกคนจะได้ประโยชน์ การเปิดเผยรายงานและโมเดลเหล่านี้คือความตั้งใจของเราที่จะสร้าง ecosystem ด้าน AI ภาษาไทยให้แข็งแรงขึ้น
เริ่มต้นสร้างด้วย Typhoon วันนี้ เราขอเชิญชวนให้คุณทดลองใช้งาน ผลักดันขีดจำกัดของโมเดล และแบ่งปันผลงานของคุณกับชุมชน ทุก insight ของคุณคือแรงขับเคลื่อนให้เราก้าวไปข้างหน้าด้วยกัน
สุดท้ายนี้อย่าลืมติดตาม Technical Reports และทรัพยากรที่เราเปิดเผยในการทำ ASR และ OCR ได้ที่นี่
-
Typhoon ASR Real-time: ArXiv | Hugging Face
-
Typhoon OCR 1.5: ArXiv | Hugging Face

