

At Typhoon, our mission is to accelerate the adoption of large language models (LLMs) and support the growth of the Thai NLP community. That means making LLMs not only powerful—but also practical and accessible for real-world Thai use cases. While models like Typhoon2 70B have been loved by the community, they often require expensive hardware (e.g., 2×H100 GPUs), which can limit their usability.
Today, we’re excited to introduce Typhoon 2.1 “Gemma”, a major leap forward in making LLMs more lightweight and deployable—without sacrificing performance. Typhoon 2.1 is available in two sizes: 4B and 12B. The 12B model can run on mid-tier GPUs (like L4 or even gaming GPUs with quantization) or Apple’s M-series Macs. The 4B version can run efficiently on CPUs, making it suitable for personal laptops or mobile deployment.
Highlights
-
Two Sizes to Access: Choose 4B for edge devices or 12B for heavier lifting—run it on anything from a CPU to a MacBook or gamer GPU.
-
Big Performance, Small Footprint: The 4B model brings fast, efficient AI to everyday devices, while the 12B version delivers cutting-edge results on M-series MacBooks and gaming-class GPUs.
-
Beats the Giants: Outperforms the Typhoon2 70B Instruct model on general benchmarks—with a fraction of the size.
-
Better Controllability: Improved instruction handling and code-switching performance make interactions more useful than ever.
-
Stronger Base Model: Built based on the Gemma 3 series of models, one of the most powerful open-source LLMs by Google.
-
Speed or Performance? You Decide: You can toggle thinking mode on for deeper, high-quality outputs—or off for faster, more cost-efficient results.
-
Free to Use: Available now on Hugging Face and Ollama.
Prelude: Our Evolution
Over time, base models have become stronger and cheaper, enabling us to build more accessible Thai-centric LLMs. We first released Typhoon 1, built on Mistral, and evaluated its Thai language knowledge using ThaiExam. With Typhoon 2, we shifted focus toward instruction-following, enabling the model to respond more usefully to prompts and handle reasoning tasks.
Now, with Gemma 3 as the foundation, we see strong performance across many aspects of Thai. However, the challenges have evolved—from language knowledge to alignment and user preference. Despite its strength (Gemma 3 rivals models like DeepSeek v3 at 685B parameters while using only 27B), the smaller variants still have limitations:
-
When prompts mix Thai and English, the model often defaults to English—even when instructed otherwise.
-
It lacks the ability to dynamically allocate more compute or perform extended reasoning on complex questions.
This led to the development of Typhoon 2.1 12B—a model that rivals Typhoon 2 70B in Thai performance, yet is lightweight enough to run on a gamer GPU, L4 instance, or even a CPU when quantized. It also introduces a "thinking mode" toggle, allowing users to choose between faster responses or deeper, more accurate reasoning for complex tasks.
Methodology
To build Typhoon 2.1 (Gemma3-based), we introduced a new approach that combines fine-tuning, model merging techniques from Typhoon 2 R1, and reinforcement learning (RL) fine-tuning—details to be shared in an upcoming paper.
We began by using supervised fine-tuning (SFT) and merging to align the model with Thai-specific preferences, applying a curated subset of post-training recipes from Typhoon 2. This made the model more controllable and better suited to Thai use cases. Once we achieved strong instruction-following in Thai, we applied RL fine-tuning to correct merging artifacts and train the model to perform controllable long-thought processes.
Performance Evaluation
We evaluated Typhoon 2.1 using the same benchmark suite as Typhoon 2
General Instruction-Following Performance
-
MT-Bench: A LLM-as-judge framework that evaluates correctness, fluency, and instruction adherence on open-end instruction. We used both the Thai MT-Bench and the English MT-Bench from LMSYS.
-
IFEval: Evaluates instruction-following accuracy based on verifiable test cases. We used both the English IFEval and the Thai version.
-
Language Accuracy & Code-Switching: Measures whether the model responds in the correct language while maintaining linguistic consistency. We sampled 500 Thai instructions from the WangchanThaiInstruct dataset as used in Typhoon 2
Math & Code Performance
-
MATH500: A subset of the MATH Benchmark containing 500 advanced mathematical problems to test step-by-step reasoning. We also included a Thai-translated version, resulting in 1,000 problems total.
-
LiveCodeBench: A competitive programming benchmark featuring problems from LeetCode, AtCoder, and CodeForces. It contains a total of 511 problems. When combined with the translated Thai versions, there are 1,022 problems in total, we evaluate on sampling subset of 200 problems..
Benchmark Results
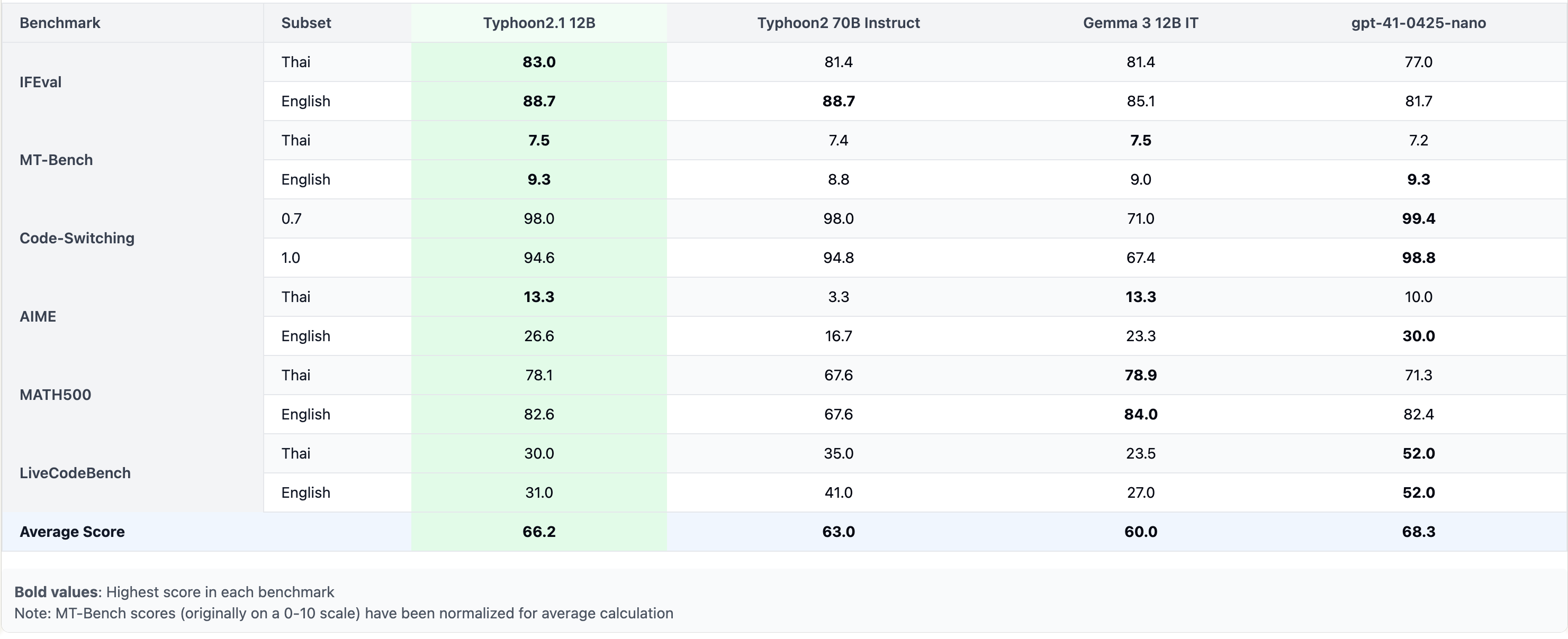
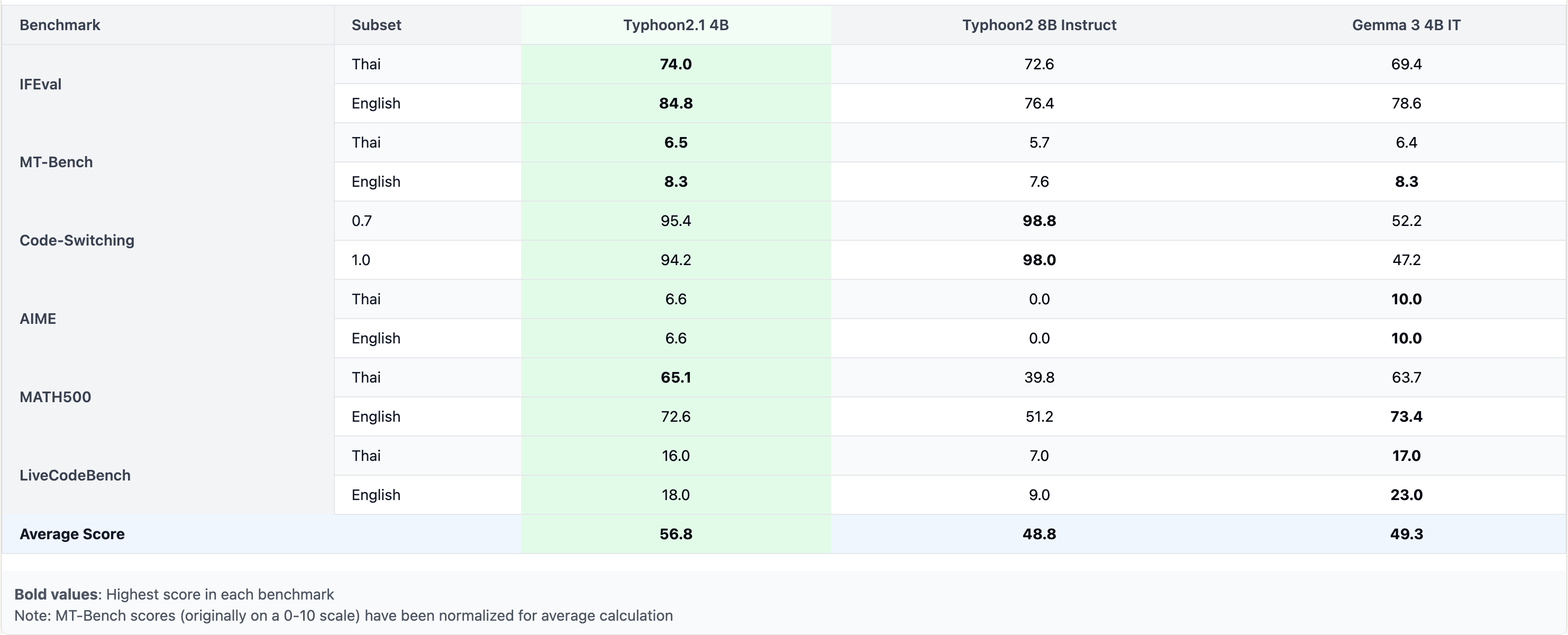
Benchmark Discussion
As shown in the result, we can see that Typhoon 2.1 12B has similar performance with Typhoon 2 70B with much smaller size, while improve upon Gemma 3 in language accuracy and code-switching approach for more than 20%. While 4B variant is better than Typhoon 2 8B Instruct.
Test-Time Scaling
To showcase the power of test-time scaling, we train Typhoon 2.1 with adaptive long-thought ability in mind, to show the capability of controllable thinking model, we adapt the forcing strategy from s1, which spends more tokens on long-thought reasoning tokens on the MATH500 dataset, demonstrating that Typhoon 2.1 12B yields progressively stronger performance as more tokens are allocated.
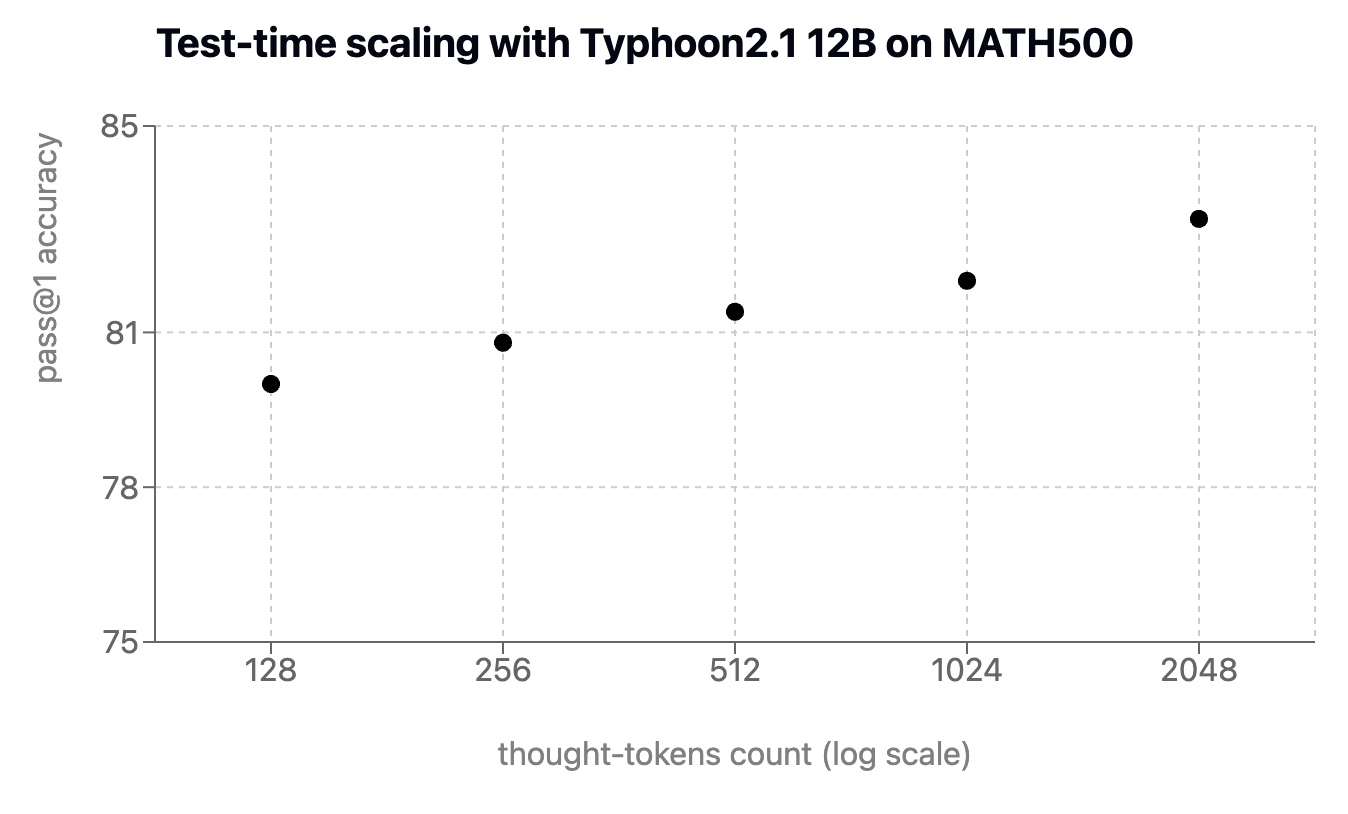
Conclusion
With Typhoon 2.1, we take a step toward the practicality of using the Typhoon model, with smaller resources needed to host and the capability to understand and build applications on top of it.
Start building today:
👉 Try it via our API at opentyphoon.ai
👉 Read the self-hosting guide using Ollama and more coming soon!
Remark: This blog post is partially written by Typhoon 2.1 & Typhoon 2 R1

