

ในช่วงไม่กี่ปีที่ผ่านมา โมเดลภาษาขนาดใหญ่ (LLM) ได้ขยับจากการเป็นแค่แชทบอทที่ทำให้แค่ตอบโต้กับผู้ใช้ผ่านข้อความเป็น agent ที่สามารถทำงานได้จริง เช่น การเขียนโค้ดแบบ vibe coding เป็นผู้ช่วยเปรียบเทียบราคาและสั่งซื้อสินค้า และเป็นไกด์ส่วนตัวที่ไม่เพียงแค่ช่วยวางแผนการท่องเที่ยวเท่านั้น แต่ยังสามารถจองที่พักและตั๋วเครื่องบินให้ได้อีกด้วย
นี่เป็นผลมาจากการมอบ เครื่องมือ (tools) ให้กับ LLM เหล่านี้ ซึ่งจริง ๆ แล้วเครื่องมือก็เป็นเพียงฟังก์ชัน (function) ที่ถูกเขียนขึ้นมาด้วยภาษาโปรแกรมมิ่งแบบหนึ่ง เมื่อรวม LLM ที่สามารถใช้เครื่องมือได้เข้ากับ workflow ซึ่งช่วยประสานการทำงานของขั้นตอนต่าง ๆ ที่มีระยะยาวและซับซ้อนเข้าด้วยกัน ก็ทำให้ agentic workflow เหล่านี้สามารถปลดล็อคผลลัพธ์ใหม่ ๆ ที่ LLM เพียงอย่างเดียวไม่สามารถทำมาก่อนได้

นั่นทำให้รูปแบบของการใช้งาน LLM มีความเป็น agentic มากยิ่งขึ้น ซึ่งก็มาพร้อมกับแนวคิดรูปแบบใหม่ในการสร้าง agent อย่าง context engineering (วิศวกรรมบริบท) นั่นเอง
Context engineering เป็นทั้งศาสตร์และศิลป์ในการออกแบบและจัดการ context (บริบท) หรือก็คือสิ่งที่เป็นข้อมูลนำเข้าให้กับ LLM ในแต่ละขั้นตอนของ workflow เพื่อให้ LLM มีข้อมูลที่เพียงพอ ไม่มากไปและไม่น้อยไป เหมาะสมกับการทำงานในขั้นปัจจุบันที่กำลังทำอยู่ โดย context engineering ได้กลายมาเป็นส่วนสำคัญที่ทำให้ workflow ต่าง ๆ ที่มี LLM ทำงานได้อย่างมีประสิทธิภาพและเชื่อถือได้ (reliable) สิ่งนี้เองเกิดจากการที่ LLM จะทำงานได้ดีหรือไม่ดีขึ้นอยู่กับข้อมูลนำเข้า (input) ที่ LLM มี อาจจะพูดได้ว่า context เปรียบเสมือนโลกทั้งใบของ LLM ก็ว่าได้
ถึงแม้ว่าจะพูดแบบนี้ แต่ข้อมูลนำเข้าที่พูดถึงก็ไม่ได้นับแค่คำสั่งโดยตรงจากผู้ใช้ (user prompt) หรือคำสั่งที่กำหนดไว้ล่วงหน้า (system prompt) เท่านั้น แต่ยังรวมถึงสิ่งที่ LLM สร้าง (generate) ขึ้นมาด้วย (response) นั่นหมายความว่าประวัติการคุยทั้งหมด (conversation) และผลลัพธ์ที่ได้ที่ได้จากการที่ LLM ไปเรียกใช้เครื่องมือต่าง ๆ ถือเป็นส่วนหนึ่งของ context เช่นเดียวกัน และการที่จัดการสิ่งต่าง ๆ เหล่านี้ได้ไม่ดีก็จะทำให้ LLM งงได้นั่นเอง เพราะ context เปรียบเสมือนความจำใช้งาน (working memory) ของ LLM ถ้ามีแต่สิ่งที่ไม่จำเป็นหรือสิ่งที่ขัดแย้งกันเองในความจำนี้เยอะ ก็จะทำให้ LLM ทำงานได้ผลลัพธ์ที่แย่ลง

การออกแบบ context ที่ดีจึงไม่ใช่เรื่องที่ง่ายเลย เพราะถ้ามีข้อมูลใน context มากไป ก็อาจจะทำให้โมเดลงงหรือไขว้เขวได้ แต่ถ้าหากมีข้อมูลน้อยไป โมเดลก็อาจจะตอบในสิ่งที่ไม่ถูกต้องหรือไม่มีอยู่จริงมาก (hallucinate) เพราะฉะนั้นการสร้าง context ที่ดีให้กับโมเดลจึงเป็นเรื่องที่ต้องทำอย่างใส่ใจเกี่ยวกับข้อมูลที่เราจะเลือกให้มาเป็นส่วนหนึ่งของ context รวมไปถึงการลำดับและจัดระเบียบข้อมูลให้มีความเหมาะสมกับแต่ละขั้นตอนของการสร้าง agent นั่นเอง
ยกตัวอย่างง่าย ๆ ลองนึกว่า ถ้าอยากสร้าง agent สำหรับช่วยเป็นไกด์วางแผนการท่องเที่ยว แต่ถ้าเราไม่ได้ให้เครื่องกับ LLM ในการไปค้นหารีวิวแหล่งท่องเที่ยวต่าง ๆ แบบที่เป็นปัจจุบัน LLM ก็คงไม่สามารถสร้างแผนการท่องเที่ยวที่ดีและเป็นปัจจุบันได้ เช่น LLM อาจจะเคยรู้ว่าร้านอาหารแห่งนี้เป็นร้านชื่อดังทำอาหารอร่อย แต่ข้อมูลที่ LLM รู้ก็เป็นข้อมูลที่เก่าแล้ว แล้วปัจจุบันลูกค้ารีวิวว่าร้านอาหารเจ้านี้ทำอาหารไม่อร่อยแล้ว แล้วก็ LLM วางแผนมา มันก็จะอ้างอิงจากข้อมูลเก่าที่คิดว่ารู้แต่ไม่เป็นปัจจุบัน ทำให้ได้แผนการท่องเที่ยวที่อาจจะไม่ประทับใจนั่นเอง
โดยสรุป เราอาจจะกล่าวพูดได้ว่าในเรื่องของ context นั้น LLM ก็มีความคล้ายคนอยู่ไม่น้อย ถ้ามีข้อมูลที่ไม่เป็นปัจจุบัน หรือมีข้อมูลไม่เพียงพอ เราก็คงไม่ได้สามารถคาดหวังผลลัพธ์ที่เป็นปัจจุบันได้และแม่นยำได้

ในช่วงหลายสัปดาห์ที่ผ่านมา ผมมีโอกาสได้ใช้ Typhoon 2.5 ซึ่งเป็นเวอร์ชันล่าสุดของ Typhoon โดยในเวอร์ชันนี้ โมเดลได้ถูกออกแบบให้ทำงานได้ดีกับงาน agentic ในรูปแบบต่าง ๆ โดยเฉพาะ
ซึ่งในบทความนี้ผมก็จะมาแชร์ 20 หลักการที่ผมเชื่อว่าเป็น best practices รวมไปถึงทริคและแนวคิดต่าง ๆ ที่ได้มาจากการลองผิดลองถูก ออกแบบ agentic workflow โดยใช้ Typhoon 2.5 และตอบคำถามหลักข้อนี้กัน
Evaluation-Driven Development ไฟส่องนำทางความสำเร็จที่วัดผลได้

ก่อนที่เราจะไปพูดกันถึงเรื่องของ context engineering เรามาพูดถึงแนวคิด evaluation-driven development (EDD) กันก่อนดีกว่า มันอาจจะฟังดูแปลก ๆ ไปบ้างแต่การมีชุดทดสอบถือได้ว่าเป็นสิ่งที่สำคัญที่สุดก่อนจะสร้าง agenetic workflow ใด ๆ ก็ตาม เพราะชุดทดสอบที่ดีนั้นก็เปรียบเสมือนเข็มทิศที่จะช่วยบอกเราว่าเรากำลังพัฒนา workflow ของเราไปในทิศทางที่ถูกต้องหรือไม่
EED จริง ๆ แล้วเป็นแนวคิดที่ใกล้เคียงกับ test-driven development (TDD) ในกระบวนการการพัฒนาซอฟต์แวร์ แต่แตกต่างกันที่ว่าแทนที่เราจะเขียนชุดทดสอบเพื่อทดสอบโค้ด เราออกแบบชุดทดสอบสำหรับทดสอบโมเดลและ workflow ของเราแทน
โดยชุดทดสอบที่ดีนั้นจะต้องถูกออกแบบมาให้สามารถรันได้บ่อย (frequent) ให้ผลลัพธ์ที่เที่ยงตรง (reliable) และถูกต้อง (accurate) เพราะว่าสัญญาณ (signal) ที่
- ถูกต้อง (Accurate) จะทำให้สามารถตัดสินใจได้อย่างมั่นใจ
- เที่ยงตรง (Reliable) จะทำให้สามารถเชื่อในผลลัพธ์ได้แม้ว่าระบบจะเปลี่ยนไป
- รวดเร็ว (Fast) เพื่อให้สามารถรันได้บ่อยระหว่างการพัฒนา
ถ้าไม่มีชุดทดสอบเหล่านี้เป็นพื้นฐานแล้วมันแทบจะเป็นไปไม่ได้เลยที่เราจะรู้ว่าการเปลี่ยนแปลงต่าง ๆ ที่เกิดขึ้นระหว่างการพัฒนาช่วยส่งผลให้ระบบดีขึ้นหรือไม่ แม้ว่าระหว่างการพัฒนาในฐานะของคนพัฒนาแล้ว เราอาจจะสามารถบอกด้วยความรู้สึกของเราได้ว่าระบบกำลังดีขึ้นหรือไม่แต่นั่นก็เป็นเพียงความรู้สึกของเราเท่านั้น ถ้าเกิดมีใครสักคนถามเราขึ้นมาในระหว่างการประชุมว่าระบบที่เรากำลังทำอยู่นั้นมันดีขึ้นจริง ๆ หรือเปล่าเราก็คงไม่มีข้อมูลอะไรที่สามารถมาช่วยสนับสนุนได้ว่าระบบของเรานั้นดีขึ้นจริง ๆ
ดังนั้นชุดทดสอบสามารถที่จะให้ข้อมูลสนับสนุนเหล่านี้ได้ไม่ว่าจะเป็นตัวเลข สัญญาณ หรือหลักฐานบางอย่างที่ทำให้เราสามารถตอบได้อย่างมั่นใจว่าระบบของเรานั้นดีขึ้นจริง ๆ เพราะเรามีข้อมูลเหล่านี้มาช่วยในการสนับสนุน การมีชุดทดสอบนี้เองทำให้เราสามารถตัดสินใจแบบใช้ข้อมูลได้ตลอดกระบวนการการพัฒนา
ถึงแม้ว่าหลายหลายคนอาจจะรู้สึกว่าการทดสอบนั้นดูไม่ได้มีความเกี่ยวข้องกับ context engineering สักเท่าไหร่แต่จริง ๆ แล้วมันก็ถือเป็นพื้นฐาน เพราะเราจะสามารถพัฒนาคำสั่ง workflow หรือเครื่องมือที่ดีขึ้นได้อย่างไร ถ้าเราไม่รู้ว่าปัจจุบันระบบของเราทำงานได้ดีหรือไม่ EDD จะเข้ามาตอบคำถามนี้ และทำให้เราสามารถมีวิธีวัดเพื่อจะติดตามเส้นทางการพัฒนาของสิ่งที่เราสร้างได้นั่นเอง
แต่ก็อาจจะมีบางคนแย้งว่า จริง ๆ เราก็แค่ลองเล่นดูได้หรือเปล่านะ (vibe check) จะได้รู้ว่าตอนนี้มันให้ ความรู้สึกประมาณไหน ก็ต้องขอบอกตรงนี้แหละว่าจริง ๆ แล้วผมเองก็ทำเหมือนกัน มันสนุกนะ แล้วบางทีมันก็เป็นวิธีที่เร็วที่สุดที่จะได้ sense บางอย่าง ว่าเรากำลังทำไปในทิศทางที่ถูกต้องหรือเปล่า
แต่อยากให้ทุกคนลองคิดภาพตามว่าถ้าเกิด workflow ของเรามันเริ่มใหญ่ขึ้นเรื่อย ๆ และมีความซับซ้อนมากขึ้น การทดสอบโดยการลองเล่นดูแบบนี้มันจะเริ่มเป็นไปไม่ได้ละ เพราะว่าระบบของเราต้องรองรับเหตุการณ์ต่าง ๆ มากขึ้นนั่นทำให้เราต้องเสียเวลาทำการทดสอบรูปแบบเหตุการณ์เหล่านี้มากขึ้นไปด้วย นอกจากนี้เราจะมั่นใจได้ยังไงว่าการแก้ไขข้อผิดพลาดหนึ่งจะไม่ทำให้เกิดข้อผิดพลาดเพิ่มขึ้นในที่อื่นที่เราไม่ได้ตรวจสอบ
นี่เป็นเหตุผลว่าทำไมการทดสอบแบบอัตโนมัติถึงสามารถช่วยเหลือเราในแง่มุมนี้ได้
agentic workflow อาจจะให้ความรู้สึกที่แตกต่างจากการพัฒนาซอฟต์แวร์ทั่วไป แต่ถึงอย่างไร workflow มันก็เป็นซอฟต์แวร์ชนิดหนึ่งเช่นกัน เพราะฉะนั้นหลักการต่าง ๆ ที่สามารถทำให้เราสร้างซอฟต์แวร์ที่ดีได้ เช่น TDD เราสามารถนำมาปรับใช้ได้เช่นกัน
TDD สนับสนุนให้นักพัฒนาสร้างชุดทดสอบขึ้นมาก่อนการเขียนโค้ด ซึ่งหลักการ EDD เอง เป็นไปในทิศทางเดียวกัน เราควรจะสนใจก่อนว่าเราจะสามารถวัด (measure) สิ่งที่เราเรียกว่าความสำเร็จได้อย่างไรก่อนที่เราจะลงมือพัฒนา นี่จะทำให้รูปแบบของการพัฒนาเปลี่ยนจากการใช้ความรู้สึกไปเป็นการใช้ข้อมูลเพื่อช่วยในการตัดสินใจ
หลักการข้อที่ 1: กำหนดตัวชี้วัด (Metric) ที่ใช้วัดผลความสำเร็จ
หนึ่งในหัวใจสำคัญของการพัฒนาแบบ EDD คือการเลือกตัวชี้วัด (metric) ที่ถูกต้อง หรือถ้าจะให้พูดอีกแบบหนึ่งมันคือการกำหนดนิยามว่าความสำเร็จหน้าตาเป็นยังไง สิ่งชี้วัดที่ดีนั้นขึ้นอยู่กับปัญหาและวัตถุประสงค์ที่ agent ของเราที่ต้องการทำการแก้ไข มันไม่มีคำตอบตายตัวว่าตัวชี้วัดที่ดีเป็นยังไง สิ่งสำคัญคือ ตัวชี้วัดที่เลือกมานั้นสามารถสะท้อนความสำเร็จที่เราต้องการได้
อย่างเช่นหากเราต้องการสร้าง agent สำหรับเป็นฝ่ายบริการลูกค้า เราก็อาจจะให้ความสนใจว่าระบบของเราสามารถตอบกลับลูกค้าได้เร็วแค่ไหน และสามารถแก้ไขปัญหาของลูกค้าได้หรือไม่ ในทางกลับกันหากเรากำลังออกแบบ agent สำหรับแก้ไขโค้ด สิ่งที่เราต้องการวัดนอกเหนือไปจากการที่โค้ดสามารถทำงานได้ก็อาจจะเป็นเรื่องของการทำให้โค้ดอ่านได้ง่าย (readable) และสามารถบำรุงรักษาได้ (maintainable) สำหรับนักพัฒนาในอนาคต
จะเห็นได้ว่ามันไม่ใช่แค่เรื่องของการเลือกตัวชี้วัดเท่านั้น แต่ตัวชี้วัดที่เราเลือกหรือออกแบบมาต้องสามารถให้คำตอบที่แม่นยำในสิ่งที่เราสนใจได้ด้วย ดังนั้นตัวชี้วัดที่ดีจึงเปรียบเสมือน feedback loop ที่บอกได้ว่าตอนนี้สิ่งที่เรากำลังทำมันช่วยให้ระบบพัฒนาไปในทิศทางที่ถูกต้องหรือกำลังพัฒนาไปในทิศทางตรงกันข้าม
เอาล่ะ ลองมาดูตัวอย่างสิ่งชี้วัดที่ทุกคนมักใช้กันดีกว่า
🎯 ความแม่นยำและอัตราความสำเร็จ
อัตราความสำเร็จบอกเราว่า workflow หรือ agent ของเราสามารถบรรลุผลลัพธ์ได้มากน้อยแค่ไหน
นี่เป็นหนึ่งในตัวชี้วัดที่พบบ่อยและตรงไปตรงมามากที่สุด โดยสามารถนำไปใช้ได้ในหลายระดับ ไม่ว่าจะเป็นที่ระดับของเครื่องมือ agent หรือทั้งระบบ โดยทั่วไปแล้ว อัตราความสำเร็จจะแสดงออกมาเป็นเปอร์เซ็นต์ของจำนวนครั้งที่ทำสำเร็จ
🕣 เวลาประมวลผล
เวลาประมวลผลบอกเราว่าต้องใช้เวลานานแค่ไหนกว่า workflow หรือ agent ของเราให้ผลลัพธ์กลับคืนมา
การวัด latency ที่ระดับระบบโดยรวมและแต่ละองค์ประกอบในระบบช่วยให้เราสามารถระบุจุดที่มีปัญหาในเชิงประสิทธิภาพได้ สำหรับ LLMs เรามักจะวัด เวลาถึงโทเค็นแรก (time to first token; TTFT) ซึ่งบอกเราว่านานแค่ไหนก่อนที่ผู้ใช้จะเห็นผลลัพธ์ส่วนแรก และความหน่วงระหว่างโทเค็น (inter-token latency; ITL) ซึ่งบอกเราว่า ความเร็วในการ generate แต่ละโทเค็นเป็นเท่าไหร่ ทั้งสองตัวชี้วัดนี้จะส่งผลกระทบโดยตรงต่อประสบการณ์การใช้งานของผู้ใช้
⚙️ ประสิทธิภาพโดยรวมของระบบ
นอกเหนือไปจากความถูกต้องแล้ว เรามักจะให้ความสนใจกับ scalability และ throughput อีกด้วย ตัวชี้วัดเหล่านี้บอกเราว่าระบบสามารถรองรับการใช้งานจริงได้มากน้อยแค่ไหน สามารถรองรับจำนวนผู้ใช้ได้เท่าไหร่ หรือระบบสามารถประมวลผลได้กี่โทเค็นต่อวินาที
สิ่งเหล่านี้มีความสำคัญเพราะว่าถึงแม้ว่าเราจะมีระบบที่สามารถให้ผลลัพธ์ได้อย่างแม่นยำแต่ถ้าหากมันตอบสนองได้ช้า ผู้ใช้ก็อาจจะหมดความสนใจก่อนที่มันจะสามารถประมวลผลได้เสร็จสิ้น
ดังนั้นประสิทธิภาพโดยรวมเชิงระบบจึงช่วยให้เราสามารถที่จะบาลานซ์ระหว่างคุณภาพและประสบการณ์ในการใช้งาน
การเลือกและติดตามตัวชี้วัดที่ถูกต้องจะทำให้เรามีข้อมูลสำหรับใช้ในการตัดสินใจ ตัวชี้วัดไม่ได้เป็นเพียงแค่ตัววัดความก้าวหน้าเท่านั้น แต่ยังเป็นสิ่งที่ทำให้เกิดความก้าวหน้าขึ้นอีกด้วย
หลักการข้อที่ 2: ออกแบบชุดทดสอบสำหรับ Agentic Workflow

รูปประกอบในบทความนี้สร้างด้วย AI จึงมีคำผิดอยู่บ้าง
EDD ก็คล้ายกับ TDD ที่เราต้องเริ่มจากการสร้างชุดทดสอบก่อนซึ่งชุดทดสอบต่างๆ เหล่านี้จะถูกออกแบบมาล้อไปกับ user journey ของ workflow เรา
คำแนะนำหนึ่งคือให้โฟกัสที่การสร้างชุดทดสอบสำหรับกรณีที่ทุกอย่างเป็นไปตามที่คิดก่อน (happy path) แล้วค่อย ๆ ขยายสำหรับกรณีที่พบได้ยาก (edge case) หรือมีข้อผิดพลาด (unhappy path) ซึ่งจะทำให้เราสามารถพัฒนาระบบได้อย่างมั่นใจมากขึ้น แล้วค่อย ๆ ทำให้ระบบมีความ resilience กับเหตุการณ์ต่าง ๆ
ใครก็ตามการพัฒนาระบบ agentic ก็มีความแตกต่างจากการพัฒนาซอฟต์แวร์ทั่วไป เพราะข้อมูลนำเข้า (input) ของ agentic workflow มันมารูปแบบของภาษาธรรมชาติ (natural language) ซึ่งมีความเป็นไปได้แทบไม่มีที่สิ้นสุด ผู้ใช้สามารถพิมพ์หรือสั่งอะไรก็ได้ตามที่ตนเองต้องการ ซึ่งนั่นก็รวมไปถึงข้อความที่พิมพ์ผิด ข้อความที่มีความหมายไม่ชัดเจน หรือแม้แต่ร้องขออะไรที่เป็นไปไม่ได้กับระบบในปัจจุบัน นี่ยังไม่รวมถึงกรณีที่ผู้ใช้อาจจะพยายามทำให้ระบบเกิดข้อผิดพลาดด้วยคำสั่งที่อันตรายอีกด้วย
เทคนิคหนึ่งเลยที่สามารถทำได้คือเริ่มจากการออกแบบชุดทดสอบสำหรับ happy path ด้วยตัวเองก่อน แล้วจากนั้นให้ LLMs ช่วยคิดกรณีเพิ่มเติมที่อาจมองข้ามไป ซึ่งมักจะเกิดจากการที่ข้อมูลนำเข้าเป็นภาษาธรรมชาติ LLMs ค่อนข้างเก่งเรื่องพวกนี้และทำงานได้ค่อนข้างดี เช่น สามารถสร้างคำสั่งที่คล้าย ๆ กันแต่เปลี่ยนระดับของภาษาไป หรืออาจจะเป็นคำสั่งแปลก ๆ ซึ่งมาจากกลุ่มผู้ใช้ที่หลากหลายได้ ทำให้ได้ตัวอย่างข้อมูลนำเข้าที่มีความใกล้เคียงกับของจริงมากยิ่งขึ้น
หลักการข้อที่ 3: รับมือกับความไม่แน่นอนด้วย LLM as a Judge
อาจจะฟังดูเหมือนปรัชญาในการใช้ชีวิต (ซึ่งก็อาจจะใช่) แต่นี่ก็รวมถึงการทำงานกับ LLM ด้วย เพราะการพัฒนา workflow ที่ใช้ LLM ซึ่งเป็นโมเดลแบบ non-deterministic โมเดลแบบนี้จะให้ผลลัพธ์ที่แตกต่างกันออกไปทุกครั้ง ถึงแม้ว่าข้อมูลนำเข้าและอาจจะรวมไปถึงสภาพแวดล้อมเหมือนเดิมก็ตาม ทำให้การออกแบบชุดทดสอบแบบเดิม ๆ ที่อาจจะมีการใช้ keyword matching ไม่มีประสิทธิภาพอีกต่อไป เพราะ LLM อาจจะให้ผลลัพธ์ที่ถูกต้อง แต่ใช้คำที่อาจจะนึกไม่ถึงตอนออกแบบ keywords ดังนั้นเราต้องทำความเข้าใจว่าความไม่แน่นอนนี้เป็นส่วนหนึ่งของคุณสมบัติของ LLMs
ถ้าอย่างนั้น เราทำอะไรได้บ้างเพื่อให้ชุดทดสอบสามารถจัดการกับเหตุการณ์เหล่านี้ได้? วิธีการหนึ่ง คือ เราสามารถใช้แนวทางที่เรียกว่า LLM as a judge หรือใช้ LLM เป็นตัวตัดสินใจนั่นเอง โดยในรูปแบบนี้เราจะสั่งให้ LLM (ซึ่งอาจจะเป็นตัวเดียวกันกับตัวที่สร้างผลลัพธ์ก็ได้) มาตัดสินว่าผลลัพธ์นั้นมีความเทียบเท่าเชิงความหมายกับผลลัพธ์ที่คาดหวังหรือไม่ โดยตัวตัดสินจะให้ผลลัพธ์กลับมาว่าผลลัพธ์นั้นดี เทียบเท่า หรือแย่ในเชิงความหมาย
อย่างไรก็ตามโมเดลเหล่านี้มักจะยังไม่เก่งในการให้ผลการตัดสินที่เป็นตัวเลข เพราะฉะนั้นการให้โมเดลเหล่านี้ตัดสินเป็นหมวดหมู่ เช่น แย่ ปานกลาง ดี ดีมาก หรือให้เปรียบเทียบผลลัพธ์กับข้อมูลอ้างอิง จะได้ผลการตัดสินที่มีความแม่นยำกว่า จริง ๆ แล้วเรื่องนี้เองก็คล้ายกับมนุษย์เราเลย เรามักจะสามารถเปรียบเทียบได้ดีกว่าการตัดสินใจให้คะแนนเป็นตัวเลข
แต่ถึงจะพูดแบบนี้ ก็ไม่ได้หมายความว่าทุกกรณีทดสอบ (test case) จำเป็นต้องใช้ LLM ในการตัดสินทั้งหมด เพราะการใช้ LLM ในการตัดสินก็มีข้อเสียในเรื่องของประสิทธิภาพและค่าใช้จ่าย เพราะฉะนั้นสำหรับกรณีที่มีความตรงไปตรงมาหรือสามารถตรวจสอบได้จากสิ่งอื่น ๆ เช่น call trace ก็อาจจะเป็นการดีกว่าที่จะใช้สิ่งเหล่านั้น
สรุป EDD
EDD เป็นพื้นฐานของการสร้าง agentic workflow เพราะมันทำให้เรามีข้อมูลสำหรับการพัฒนาได้อย่างมั่นใจผ่านตัวชี้วัดต่าง ๆ และชุดทดสอบที่เตรียมไว้ ทำให้เราสามารถตัดสินใจได้อย่างมีประสิทธิภาพบนพื้นฐานของข้อมูลนอกเหนือจากการใช้ลางสังหรณ์เพียงอย่างเดียว นอกจากนี้ EDD ยังทำให้เรามั่นใจได้ทุกครั้งที่เราปรับปรุงส่วนต่าง ๆ ของ workflow ว่ามันจะไม่ทำให้ความสามารถเก่า ๆ หายไป หรือทำให้ข้อผิดพลาดที่แก้ไขไปแล้วกลับคืนมาอีกครั้ง
EDD ทำให้เราสามารถพัฒนาไปแบบ iterative โดยอาศัย feedback จากชุดทดสอบ เพื่อบอกว่าการเปลี่ยนแปลงที่สร้างขึ้นมาให้ผลลัพธ์ที่ดีหรือไม่ ทำให้สามารถทำการทดลองปรับเปลี่ยนส่วนต่าง ๆ ของ workflow ได้อย่างมั่นใจ ก่อให้เกิดวงจร สร้าง → ทดสอบ → เรียนรู้ → ปรับปรุง ที่นำไปสู่ผลลัพธ์ที่ดีขึ้นในทุก ๆ ครั้ง
จนถึงตรงนี้เราก็มีเครื่องมีสำหรับวัดแล้วว่าระบบทำงานได้อย่างที่ต้องการหรือไม่ นั่นก็พาเราไปสู่ส่วนถัดไป นั่นก็คือ context นั่นเอง
อย่างที่เกริ่นไปว่า context ถือเป็นหัวใจของการพัฒนา agentic workflow เพราะมันเป็นตัวกำหนดสิ่งที่โมเดลรู้ จดจำ และเข้าใจเกี่ยวกับสภาพแวดล้อมในแต่ละขั้นตอนของ workflow ดังนั้น context ที่ดีจึงช่วยให้โมเดลทำงานได้อย่างประสบความสำเร็จนั่นเอง ในส่วนถัดไปเราจะมาพูดถึงศาสตร์และศิลป์ของ context engeering ที่จะช่วยให้เราออกแบบ จัดการ และปรับปรุงข้อมูลที่ LLM ใช้ทำงานได้อย่างมั่นใจ
ถ้าพร้อมแล้วก็ไปกันเลย!
Context Engineering
ก่อนที่เราจะลงลึกในเรื่องของ context engineering เรามาดูกันก่อนดีกว่าว่า context จริง ๆ แล้วคืออะไร แล้วทำไมมันถึงสำคัญสำหรับระบบ agentic
รู้จักกับ Context Engineering ฉบับรวบรัด

ทำไม Context ถึงสำคัญ?
จริง ๆ แล้วก็เหมือนพวกเราที่เป็นมนุษย์เลย LLMs เองก็ตัดสินใจบนพื้นฐานของข้อมูลที่มันสามารถเข้าถึงได้ เพราะฉะนั้นผลของการตัดสินใจจะดีหรือไม่ดีก็ขึ้นอยู่กับข้อมูลที่ทำหน้าที่เป็นบริบท (context) ของ LLM นั่นเอง
Context ของมนุษย์มาจากสิ่งแวดล้อมรอบตัวเรา ไม่ว่าจะเป็นสิ่งที่เรามองเห็น สิ่งที่เราได้ยิน หรือในตัวเรา เช่น สิ่งที่เราจำได้ และความรู้ที่เรามี ข้อมูลต่าง ๆ เหล่านี้ที่มาจากประสาทสัมผัสและประสบการณ์ของเรา ช่วยให้เราสามารถทำความเข้าใจและใช้ชีวิตอยู่บนโลกนี้ได้
เมื่อเราเริ่มมีข้อมูลเพิ่มขึ้น เช่น ความรู้ หรือประสบการณ์ใหม่ ๆ เราก็สามารถตัดสินใจได้ดีขึ้นโดยอาศัยข้อมูลเหล่านั้น แต่ในทางกลับกัน หากเราไม่มีข้อมูลแต่จำเป็นต้องตัดสินใจ เราก็มักจะต้องเดาซึ่งก็อาจจะนำไปสู่ความผิดพลาดได้ LLM เองก็เป็นเช่นเดียวกัน และผลของการขาดข้อมูลใน context ที่ดี ก็มักจะนำไปสู่การทำงานที่ผิดพลาดหรือ hallucination
ลองนึกภาพตามง่าย ๆ สมมติว่ามีร้านคาเฟ่เปิดใหม่วันนี้ ซึ่งทำให้ยังไม่มีรีวิวและคำแนะนำอะไร รวมไปถึงเราเองก็ยังไม่มีประสบการณ์กับร้านนี้ด้วย แต่เราอยากกินมัทฉะมาก ๆ สิ่งที่เราทำได้ก็คือลองสั่งดู ปรากฎว่าร้านนี้ทำมัทฉะไม่อร่อยเท่าไร ตอนนี้เรามีประสบการณ์แล้ว เราเลยรู้ว่าครั้งหน้าเราไม่ควรสั่งมัทฉะ พอวันถัดมาเราไปลองสั่งลาเต้แทน แล้วปรากฎว่าร้านนี้ทำได้อร่อยเลย เราก็จะจดจำไว้ว่าร้านนี้ทำอะไรอร่อยหรือไม่อร่อย
จริง ๆ เรื่องนี้เองแสดงให้เห็นว่าหากเทียบกลับไปเป็นโมเดลแล้ว ในสภาพแวดล้อมที่โมเดลไม่คุ้นเคย โมเดลเองก็ต้องมีการลองผิดลองถูกไปเรื่อย ๆ ซึ่งการลองผิดลองถูกเหล่านี้ก็จะกลายเป็นส่วนหนึ่งของ context ที่โมเดลรับรู้และก็ช่วยให้โมเดลสามารถตัดสินใจในอนาคตได้ดีขึ้น
เพราะฉะนั้นทุก ๆ การโต้ตอบกับ agent ทุก ๆ เครื่องมือที่โมเดลลองใช้ รวมถึงผลลัพธ์ที่ได้กลับมาจากสภาพแวดล้อม ต่างก็ช่วยให้ context ของ LLM มีข้อมูลที่เป็นประโยชน์มากยิ่งขึ้น และนำไปสู่การตัดสินใจที่ดีขึ้น
แล้ว Context คืออะไรกันแน่?
สำหรับ LLM แล้ว Context คือ ทุกสิ่ง ที่โมเดลสามารถเข้าถึงได้สำหรับใช้ในการสร้างข้อความ ซึ่งสิ่งที่ว่านั่นนอกจาก คำสั่งจากผู้ใช้ (user prompt) แล้ว ยังรวมไปถึง
- คำสั่งรูปแบบอื่น ๆ เช่น คำสั่งระบบ (system prompt) หรือข้อความนักพัฒนา (developer message)
- ประวัติการสนทนา ซึ่งไม่เพียงแต่มีคำสั่ง (prompt) ต่าง ๆ เท่านั้น แต่ยังรวมไปถึงข้อความที่โมเดลสร้างขึ้นมาด้วย
- ผลลัพธ์จากเครื่องมือ เช่น ข้อมูลที่ดึงมาจาก API ภายนอก หรือผลลัพธ์จากการรันโปรแกรม
- ข้อมูลที่เข้าถึง เช่น ข้อมูลต่าง ๆ ที่ดึงมาจากฐานข้อมูลหรือไฟล์เอกสารต่าง ๆ
- และอื่น ๆ อีกมากมาย
พูดง่าย ๆ context ก็คือความจำระยะสั้นของโมเดลสำหรับใช้ทำงานนั่นเอง ซึ่งจะกำหนดสิ่งที่โมเดลรู้ในแต่ละขั้นตอน และส่งผลกระทบต่อพฤติกรรมและการปรับตัวในสภาพแวดล้อมนี้
มาถึงตรงนี้ หลาย ๆ คนอาจจะสงสัยว่า แล้วนี่ไม่ใช่ prompt engineering (วิศวกรรมคำสั่ง) หรอ? คำตอบก็คือ context engineering เป็นสิ่งที่กว้างกว่า prompt engineering และ prompt engineering เองก็เป็นส่วนหนึ่งของ context engineering นี่เป็นเพราะว่า context หมายรวมไปถึงสิ่งอื่น ๆ นอกเหนือไปจากคำสั่ง (prompt) แบบลิสต์ด้านบนนั่นเอง เพราะฉะนั้นเราจะไม่ได้ให้ความสนใจแค่การปรับคำสั่งให้โมเดลทำสิ่งต่าง ๆ ตามความต้องการเท่านั้น แต่ยังรวมไปถึงการจัดการข้อมูลใน contex ด้วย และการไหลของข้อมูลใน workflow ด้วย เช่น เราอาจจะตัดสินใจที่จะลบข้อมูลบางอย่างออก เพราะมันไม่มีความจำเป็นในขั้นตอนปัจจุบัน และนี่ก็คือสิ่งที่ทำให้ context engineering เป็นมากกว่า prompt engineering นั่นเอง
ข้อจำกัดของ Context Window

น่าเสียดายว่า LLM เองก็เหมือนมนุษย์ที่ไม่ได้มีพื้นที่สำหรับจดจำได้อย่างไม่จำกัด แต่ละโมเดลเองก็มีขีดความสามารถในการจดจำหรือขนาดของ context (context window) ที่แตกต่างกัน และโดยทั่วไปแล้วเจ้า context window ที่ว่าก็เป็นตัวกำหนดว่าโมเดลจะสามารถประมวลผลได้สูงสุดทั้งหมดกี่โทเค็น เมื่อมีจำนวนโทเค็นสูงจนถึงขึดจำกัดนี้แล้วและยังอยากที่จะประมวลผลต่อ ก็จำเป็นที่ต้องตัดลบหรือสรุปข้อมูลบางอย่างใน context เพื่อให้ context ไม่เกิดจำนวนนั้นอีกครั้ง
อย่างไรก็ตาม ต่อให้โมเดลสามารถรองรับการประมวผลจำนวนโทเค็นเยอะ ๆ ได้ การใช้ context ที่ยาวมาก ๆ ก็ไม่ได้ดีเสมอไป เพราะว่ายิ่ง context ยาวขึ้น ก็จะส่งผลให้การประมวลผลช้าลงด้วย และมาพร้อมกับค่าใช้จ่าย (ในเชิงการประมวลผลหรือเงิน) สูงขึ้นตาม นอกจากนี้โมเดลก็มักจะชอบ hallucinate เวลา context ยาว ๆ อีกด้วย ซึ่งส่งผลให้ขีดความสามารถของโมเดลลดลง
ดังนั้นระบบที่ดีจึงบาลานซ์ระหว่างความกว้างและความลึกของข้อมูลที่อยู่ใน context เพื่อให้โมเดลมีข้อมูลที่พอดีและสามารถตัดสินใจได้อย่างมีประสิทธิภาพ
บทบาทของ Context Engineering
Context engineering เป็นทั้งศาสตร์และศิลป์ของการสร้าง context ที่เปรียบเสมือนหน่วยความจำที่โมเดลใช้ทำงาน ดังนั้นทุก ๆ โทเค็นที่อยู่ใน context จึงควรจะทำหน้าที่โดยไม่สูญเปล่า
Context ที่ดีนั้น ประกอบไปด้วยคุณสมบัติเหล่านี้
- เกี่ยวข้อง (Relevant) ข้อมูลมีประโยชน์และเกี่ยวข้องกับงานที่กำลังทำอยู่
- เป็นระเบียบ (Structured) ข้อมูลถูกจัดการในรูปแบบที่โมเดลสามารถเข้าใจได้ง่ายและไม่สับสน
- ปรับเปลี่ยนตามความเหมาะสม (Adaptive) context มีการเปลี่ยนแปลงไปตามข้อมูลใหม่ ๆ ที่ได้รับเพิ่ม และความเข้าใจที่มากขึ้นเกี่ยวกับสภาพแวดล้อมนั้น ๆ
Context engineering ตอบคำถามที่สำคัญนี้
ทำยังไงเราถึงจะช่วยโมเดลให้เข้าใจโลกได้ดีขึ้นในสภาวะที่มีความจำกัดของสิ่งที่โมเดลจดจำได้
เราจะไปสำรวจกลยุทธ์ต่าง ๆ ในการสร้างและบริหาร context ภายในส่วนนี้ของบทความกันภายหลัง โดยจะเริ่มตั้งแต่การออกแบบคำสั่งไปจนถึงการออกแบบ workflow สำหรับให้ agent ทำงานร่วมกัน นอกจากนี้เรายังพาทุกคนไปดูว่าการออกแบบ context อย่างตั้งใจจะช่วยให้โมเดลกลายเป็นระบบ agentic ได้อย่างไร
แต่ก่อนอื่น เรามาสำรวจต้นกำเนิดของ context engineering กันก่อนดีกว่า
หลักการข้อที่ 4 Context Engineering เป็นทั้งศาสตร์และศิลป์
คำว่า “context engineering” ถูกเสนอขึ้นครั้งแรกโดยคุณ Tobi Lütke CEO ของ Shopify โดยเขาอธิบายว่า context engineering คือ ศิลป์ของการให้ข้อมูลแวดล้อมสำหรับงานที่สามารถทำได้ด้วย LLM
I really like the term “context engineering” over prompt engineering.
— tobi lutke (@tobi) June 19, 2025
It describes the core skill better: the art of providing all the context for the task to be plausibly solvable by the LLM.
โดยต่อมา คุณ Andrej Karpathy ก็ได้ขยายความเพิ่มเติม และเป็นจุดที่ทำให้ context engineering เป็นที่รู้จักในวงกว้างขึ้น โดยเขาอธิบายว่า context engineering นั้น จริง ๆ แล้วเป็นทั้งศาสตร์ (science) และศิลป์ (art) ต่างหาก
[…] context engineering เป็นศิลปะที่มีความละเอียดอ่อนและเป็นวิทยาศาสตร์ของการใส่ข้อมูลเข้าไปใน context window ด้วยข้อมูลที่เพียงพอและถูกต้องสำหรับขั้นตอนถัดไป
เขายังได้อธิบายเพิ่มเติมอีกด้วยว่ามันเป็นวิทยาศาสตร์ เพราะมัน “เกี่ยวข้องกับรายละเอียดและคำอธิบายของงาน ตัวอย่างของงานนั้น ๆ RAG ข้อมูลที่เกี่ยวข้อง (ที่อาจจะเป็นรูปแบบใดก็ได้ เช่น รูปภาพ) เครื่องมือ สถานะ (state) และประวัติการสนทนา ถูกรวมเข้าไว้ด้วยกัน ถ้ามีน้อยไปหรือผิดรูปแบบ LLM ก็จะไม่มี context ที่ถูกต้องสำหรับการทำงานอย่างมีประสิทธิภาพ ถ้ามีมากไปหรือไม่เกี่ยวข้อง ค่าใช้จ่ายของ LLM ก็อาจจะแพงขึ้นและประสิทธิภาพก็จะลดลง” แต่มันก็เป็นศิลปะด้วย เพราะว่าการจะทำสิ่งนี้ให้ได้ดีนั้น ต้องใช้เซนส์ด้วย “สัญชาตญาณสำหรับนำทางในการออกแบบโดยอิงจากจิตวิทยาของ LLM ที่เกี่ยวข้องกับผู้คน”
+1 for "context engineering" over "prompt engineering".
— Andrej Karpathy (@karpathy) June 25, 2025
People associate prompts with short task descriptions you'd give an LLM in your day-to-day use. When in every industrial-strength LLM app, context engineering is the delicate art and science of filling the context window… https://t.co/Ne65F6vFcf
ในอีกความหมายหนึ่ง context engineering นั้นไม่เพียงแต่เป็นการป้อนข้อมูลให้กับ LLM เท่านั้น แต่ยังหมายรวมไปถึงการคัดสรรข้อมูลเกี่ยวข้องสภาพแวดล้อมนั้น ๆ อีกด้วย วิธีการที่เลือกมาใช้ในการรวบรวม เรียงลำดับ และจัดวางข้อมูลส่งผลโดยตรงต่อความสามารถของโมเดล หากน้อยเกินไป โมเดลก็จะไม่มีข้อมูลเพียงพอที่จะทำงานได้อย่างชาญฉลาด หากมากเกินไปหรืออยู่ในรูปแบบที่ไม่ถูกต้อง ก็ทำให้ context window ของ LLM บวมขึ้นและทำให้การประมวลผลช้าลง รวมถึงได้ผลลัพธ์ที่แย่ลง
ความที่ context engineering เป็นทั้งวิศวกรรมศาสตร์และการใช้สัญชาตญาณนี้เองที่ทำให้ context engineering มีความท้าทายแต่ก็ทรงพลังไปในเวลาเดียวกัน
เอาละ เรามาเริ่มสำรวจวิธีการที่เราจะสร้าง context ขึ้นมากันดีกว่า นี่หมายความว่าเราต้องมีความเป็นเจ้าของของข้อมูลที่เราจะนำไปใช้ LLM ทำงาน และยังเกี่ยวข้องกับการออกแบบข้อมูลที่มีให้ LLM ใช้ในแต่ละขั้นตอนของ agentic workflow อย่างตั้งใจ
การสร้าง Context

ลองคิดภาพว่า context engineering ก็เหมือนการเป็นนักสืบ โดยเป้าหมายหลักคือการให้เบาะแสที่เพียงพอกับโมเดล เพื่อที่จะสามารถไขคดีได้ พูดอีกอย่างก็คือเพื่อให้เข้าใจว่าผู้ใช้ต้องการอะไร ใช้เหตุผลกับสถานการณ์ที่เกิดขึ้น และตัดสินใจว่าจะทำอะไรต่อ ข้อมูลทุกชิ้น ผลลัพธ์จากเครื่องมือ และฟีดแบ็กจากผู้ใช้ ต่างก็เปรียบเสมือนกับเบาะแสที่จะช่วยให้พื้นที่ของการสืบสวนลดลง และทำให้โมเดลตัดสินใจได้ดีขึ้น
การทำสิ่งนี้ให้ได้ดีหมายความว่าเราต้องหัดที่จะคิดให้เหมือนกับ LLM เราต้องคาดการณ์ว่าโมเดลจะรู้หรือไม่รู้อะไรบ้าง และหลักฐานแบบไหนที่จะช่วยให้โมเดลสามารถทำงานได้อย่างถูกต้อง Mindset ที่ว่าเราต้องเป็นเจ้าของ context นี้สำคัญมาก และจะช่วยเปลี่ยนจะคนเขียนคำสั่งให้เป็นนักออกแบบระบบ
เรื่องนี้ซับซ้อนมากกว่าที่ทุกคนคิด เพราะว่าแต่ละโมเดลก็มีความสามารถ สไตล์ และคุณลักษณะที่แตกต่างกัน กลยุทธ์ที่ทำงานได้ดีสำหรับโมเดลหนึ่งอาจจะทำงานได้แย่กับอีกโมเดลหนึ่ง การพยายามสร้างสัญชาตญาณสำหรับความแตกต่างเหล่านี้ไม่สามารถหาได้จากกการอ่านเอกสารอย่างเดียว แต่มาจากการลองใช้งานโมเดลเหล่านั้น และทดลองทำสิ่งต่าง ๆ จนสามารถรับรู้สิ่งต่าง ๆ เหล่านั้นได้ผ่านความรู้สึก
แต่ก็ไม่ต้องเป็นกังวลไป เพราะว่าผมเองก็มีหลักการพื้นฐานที่สามารถนำไปปรับใช้ได้กับทุกโมเดลมาฝากกัน
หลักการข้อที่ 5: เริ่มต้นด้วยเจตนา (Intent)
ก่อนที่ทุกคนจะเพิ่มอะไรเข้าไปใน context ลองถามตัวเองดูก่อนว่า ในขั้นถัดไป โมเดลจะต้องทำหรือตัดสินใจอะไร
การถามคำถามนี้จะช่วยให้เราคิดว่าทุก ๆ โทเค็นที่เราใส่เพิ่มเข้าไปนั้น ช่วยให้โมเดลสามารถทำงานได้ดีขึ้จริงรึเปล่า ยกตัวอย่างเช่น หากอยู่ในขั้นตอนแรก ๆ ของ workflow โมเดลอาจจะยังไม่มีความรู้เกี่ยวกับผู้ใช้หรือสภาพแวดล้อมมากนัก ดังนั้นข้อมูลที่มีประโยชน์ใน context ก็ควรจะเป็นข้อมูลเกี่ยวกับผู้ใช้ หรือวัตถุประสงค์ของสิ่งที่ผู้ใช้ต้องการ หรือข้อมูลที่เกี่ยวข้องสำหรับการทำงานอื่น ๆ
ในทางกลับกัน เมื่อถึงจุดที่โมเดลทำงานไปได้สักระยะแล้วใน workflow มันก็เป็นเรื่องปกติที่เราจะปรับ context ให้เหมาะกับงานที่มีความจำเพาะเจาะจงมากยิ่งขึ้น เพราะเรารู้แล้วว่าผู้ใช้ต้องการทำอะไร
หลักการข้อที่ 6: รวบรวมข้อมูลที่เกี่ยวข้อง
ในแต่ละขั้นตอน ลองคิดว่าอะไรจะเป็นชุดของข้อมูลที่น้อยที่สุดที่โมเดลต้องการและไม่ต้องการมากไปกว่านั้น เช่น
- ข้อมูลของผู้ใช้หรืองานที่เกี่ยวข้องโดยดึงมาจากเครื่องมือ
- สรุปของประวัติการสนทนาก่อนหน้า
- ผลลัพธ์หรือข้อผิดพลาดจากการเรียกใช้เครื่องมือ
- คำอธิบายของเครื่องมือที่มีอยู่และวิธีการทำงานของมัน
กระบวนการในการจัดระเบียบข้อมูลนี้ควรจะล้อกันไปกับ workflow ของโมเดล เช่น หากโมเดลกำลังจะตัดสินใจโดยอิงจากความชอบของผู้ใช้ ข้อมูลความชอบของผู้ใช้ก็ต้องมีอยู่ในรูปแบบใดรูปแบบหนึ่ง ถ้าไม่มีข้อมูลนี้ โมเดลก็จะไม่สามารถทำงานตามที่ต้องการได้
หลักการข้อที่ 7: สร้างความเข้าใจให้เหมาะสมกับขั้นตอน
แต่ละช่วงของ workflow ต้องการ context ที่แตกต่างกัน
- ช่วงแรก → ให้ข้อมูลเกี่ยวกับตัวตน เป้าหมาย และภูมิหลัง
- ช่วงกลาง → รวมผลลัพธ์ระหว่างทาง ข้อมูลภายนอกที่เกี่ยวข้อง และฟีดแบ็กจากการดำเนินการ
- ช่วงปลาย → มุ่งเน้นที่การสรุปผลลัพธ์สุดท้าย และการตรวจสอบความถูกต้อง
กระบวนการพัฒนาแบบนี้ช่วยให้โมเดลคงความสนใจไว้กับสิ่งสำคัญ และป้องกันการกระจัดกระจายของข้อมูลใน context ซึ่งหมายถึง การเพิ่มขึ้นของข้อมูลที่ไม่เกี่ยวข้องหรือซ้ำซ้อน
โบนัส: เปลี่ยนแปลงประวัติศาสตร์ด้วยการแก้ไขประวัติสนทนา

เนื่องจากประวัติการสนทนา (conversation history) จริง ๆ แล้วเป็นแค่ array ของ message object นั่นแปลว่าเราสามารถ แก้ไขหรือแทรกข้อความ ได้โดยตรงเพื่อช่วยชี้นำความเข้าใจของโมเดล
การเพิ่มคำสั่งของผู้ใช้หรือผู้ช่วยใหม่ด้วยตนเอง เช่น การเตือนสั้น ๆ เกี่ยวกับบริบท หรือการอธิบายเจตนาอย่างชัดเจน สามารถช่วยให้โมเดลปรับทิศทางและตัดสินใจได้อย่างแม่นยำมากขึ้นในขั้นตอนต่อไป ในทำนองเดียวกัน การแก้ไขข้อความที่มีอยู่เพื่อ ลบผลลัพธ์จากเครื่องมือที่ไม่เกี่ยวข้องหรือข้อมูลเก่า ก็ช่วยให้ context เล็กลงและมีความชัดเจนมากขึ้น การปรับแต่งโดยตรงในลักษณะนี้ถือเป็นหนึ่งในวิธีที่ทรงพลังที่สุดในการควบคุมระบบ agentic โดยไม่ต้องเทรน่หรือเขียนคำสั่งใหม่
สรุป Context Engineering
โดยสรุปแล้ว การสร้าง context คือ การสร้าง สภาพแวดล้อม ที่ช่วยให้โมเดลสามารถคิดได้อย่างชัดเจน ข้อความแต่ละข้อความ ผลลัพธ์จากเครื่องมือ และข้อมูลที่ดึงมาแต่ละชิ้น ล้วนกลายเป็นส่วนหนึ่งของหน่วยความจำขณะทำงานของโมเดล และหน้าที่ของเราก็คือการทำให้หน่วยความจำนั้น ถูกต้อง ตรงประเด็น และเป็นประโยชน์
ตอนนี้เรามาเริ่มกันที่องค์ประกอบแรกของบริบทของเรากันดีกว่ากับ คำสั่ง (prompt)
วิศวกรรมคำสั่ง (Prompt Engineering)

เมื่อมีข้อมูลที่ถูกต้องได้แล้ว ความท้าทายอันถัดไป คือ วิธีการสื่อสารข้อมูลนั้น ซึ่งนั่นคือ วิศวกรรมคำสั่ง (prompt engineering) นั่นเอง กระบวนการนี้เกี่ยวข้องกับการจัดโครงสร้าง รูปแบบ และการใช้ถ้อยคำ เพื่อให้ LLM ตีความได้อย่างถูกต้อง คำสั่งคือส่วนที่ปรับแต่งได้ชัดเจนที่สุดของ context แต่ประสิทธิภาพของมันขึ้นอยู่กับหลายปัจจัย
เรามาลองดูหลักการสำคัญห้าประการ ที่ผมพบว่ามีประโยชน์เป็นพิเศษเมื่อทำการปรับปรุงและพัฒนาคำสั่งใน agentic workflow
หลักการข้อที่ 8: กำหนดเวอร์ชันให้คำสั่ง (Prompt)
ปฏิบัติกับ คำสั่ง (prompt) เป็นส่วนหนึ่งของซอร์สโค้ด ตรวจสอบและบันทึกไว้ใน version control (เช่น Git) ควบคู่ไปกับโค้ดของ workflow และจดบันทึกพฤติกรรมที่สังเกตได้รวมถึงการเปลี่ยนแปลงด้านประสิทธิภาพในแต่ละเวอร์ชันของคำสั่ง การทำเช่นนี้จะช่วยให้เข้าใจว่าการแก้ไขเพียงเล็กน้อยส่งผลต่อพฤติกรรมโดยรวมของระบบอย่างไร
Agentic workflow แตกต่างจากซอฟต์แวร์แบบดั้งเดิมในแง่ที่ว่าระบบสามารถเปลี่ยนแปลงได้อย่างมากโดยไม่ต้องแก้ไขโค้ดแม้แต่บรรทัดเดียว เพียงแค่เปลี่ยนคำ ๆ เดียว หรือรูปแบบการเขียนในคำสั่ง โดยมันก็อาจส่งผลต่อวิธีที่ agent วางแผน ให้เหตุผล หรือใช้เครื่องมือได้ การติดตามการเปลี่ยนแปลงเหล่านี้อย่างเป็นระบบจะช่วยเปลี่ยนกระบวนการปรับแต่งคำสั่งจากการเดาโดยสัญชาตญาณให้กลายเป็นกระบวนการที่สามารถวัดผลและทำซ้ำได้อย่างมีประสิทธิภาพ
หลักการข้อที่ 9: ทำทุกอย่างให้ง่ายเข้าไว้
กฎเดียวกับที่ใช้ในวิศวกรรมซอฟต์แวร์ก็ใช้ได้กับ agentic workflow เช่นกัน นั่นก็คือ ทำให้ง่ายเข้าไว้ (Keep it simple)
คำสั่งที่ซับซ้อน รก หรือมีโครงสร้างไม่ดีจะสร้างความสับสนให้ทั้งกับมนุษย์และกับโมเดล คำสั่งที่เป็นระเบียบและเรียบง่ายจะเป็นประโยชน์กับทุกฝ่าย ทั้งนักพัฒนา ผู้ใช้ และตัว LLM เอง
ความเรียบง่ายช่วยเพิ่มความชัดเจน ลดการใช้จำนวนโทเคน และเพิ่มความเร็วตอน inference เมื่อโมเดลได้รับคำสั่งที่กระชับและไม่กำกวม มันจะใช้เวลาในการตีความน้อยลงและมีเวลาให้เหตุผลเกี่ยวกับงานมากขึ้น
อย่างไรก็ตาม “คำสั่งที่เรียบง่าย” ไม่ได้หมายความว่าต้อง “สั้น” เสมอไป คำสั่งที่เรียบง่ายควรให้ข้อมูลเพียงพอสำหรับให้ LLM ทำงานได้อย่างมีประสิทธิภาพ ไม่มากเกินไปและไม่น้อยเกินไป อาจจะยาว แต่ทุกโทเค็นควรมีจุดประสงค์ที่ชัดเจน
ในความเป็นจริง หลักการเดียวกันนี้ใช้ได้กับการเขียนหนังสือที่ดี: ความยาวไม่ใช่ปัญหา คำที่ไม่จำเป็นต่างหากที่เป็นปัญหา
เคล็ดลับเพิ่มเติม: XML เป็นโครงสร้างที่มีประโยชน์ในการจัดกลุ่มข้อมูลที่เกี่ยวข้องอย่างชัดเจน คำสั่งที่มีโครงสร้างแบบนี้ช่วยให้ LLM เข้าใจความสัมพันธ์ระหว่างกลุ่มข้อมูลได้ดีขึ้น ลดความกำกวม และยังคงดูแลรักษาได้ง่าย ยกตัวอย่างเช่น
หลักการข้อที่ 10: ให้แนวทาง (Guideline) ดีกว่าให้ตัวอย่าง
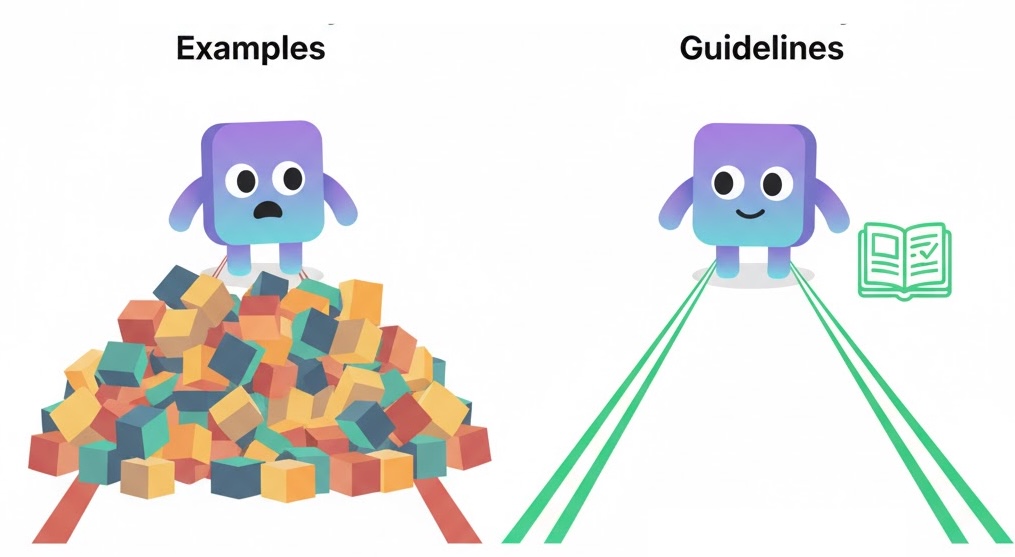
สำหรับ LLM ในยุคแรก ๆ แล้ว ก็ใช้ตัวอย่าง (few-shot examples) ในคำสั่ง เคยเป็นสิ่งจำเป็นเพื่อให้ได้ผลลัพธ์ที่ดี แต่ในปัจจุบัน โมเดลส่วนใหญ่ถูกฝึกให้ปฏิบัติตามคำสั่งของผู้ใช้ (instruction-tuned models) ทำให้ไม่จำเป็นต้องใช้ตัวอย่างเหล่านั้นอีกต่อไป และใน agentic workflows ที่มีดำเนินการต่อเนื่องและทำงานนาน (long context) ตัวอย่างเหล่านี้อาจส่งผลเสียต่อประสิทธิภาพได้ด้วยซ้ำ
เพราะการใช้ตัวอย่างจะกินพื้นที่ของ context และอาจทำให้โมเดลเกิดความสับสน โดยเข้าใจผิดว่าตัวอย่างเป็นคำสั่งจริงของผู้ใช้ ในบางกรณี โมเดลอาจเข้าใจผิดว่าข้อความตัวอย่าง คือ อินพุตของผู้ใช้เอง ซึ่งนำไปสู่การสร้างข้อมูลเท็จ (hallucination) หรือพฤติกรรมที่ไม่ต้องการ
แทนที่จะเติมคำสั่งด้วยตัวอย่างมากมาย ข้อแนะนำของผม คือ เราควรให้แนวทางที่ชัดเจนเพื่อกำหนดความคาดหวังและขอบเขตการทำงานมากกว่า โดยสงวนการใช้ตัวอย่างไว้เฉพาะในงานที่มีโครงสร้างชัดเจนเท่านั้น (เช่น การจัดรูปแบบโค้ดหรือการปรับสไตล์ข้อความ) ซึ่งในกรณีเหล่านี้ ตัวอย่างจะช่วยเพิ่มคุณค่าได้จริง
หลักการข้อที่ 11: หลึกเลี่ยงข้อมูลที่ขัดกันเอง
คำสั่งที่ขัดแย้งกันคือศัตรูตัวร้ายของโมเดล และบ่อยครั้งก็เป็นศัตรูของนักพัฒนาด้วยเช่นกัน แนวทางที่ไม่สอดคล้องกันอาจเกิดขึ้นได้ไม่เพียงแค่ในคำสั่งหลัก (prompt) เท่านั้น แต่ยังอาจแฝงอยู่ในคำอธิบายของเครื่องมือ เอกสารประกอบ หรือแม้แต่ในการอัปเดต context
ตรวจสอบให้แน่ใจว่าคำสั่งและข้อมูลทุกส่วนสอดคล้องและชี้ไปในทิศทางเดียวกัน หากมีหลายองค์ประกอบที่อธิบายความรับผิดชอบซ้ำซ้อนกัน ควรปรับให้เข้ากันตั้งแต่ต้น เช่นเดียวกับทีมมนุษย์ สัญญาณที่ไม่ชัดเจนจะก่อให้เกิดความสับสน ความลังเล และผลลัพธ์ที่คาดเดาไม่ได้ ชุดคำสั่งที่สอดคล้องกันคือแกนหลักของระบบ agentic ที่มั่นคง
หลักการข้อที่ 12: บอก Agent ให้รับรู้ถึง Workflow และเครื่องมือ
LLM ควรรู้จัก โลกที่มันอาศัยอยู่ การบอกภาพรวมของ workflow พร้อมกับเครื่องมือที่โมเดลสามารถเข้าถึงได้และข้อแนะนำถึงช่วงเวลาที่ควรใช้งานของเครื่องมือนั้น ๆ จะช่วยให้กระบวนการทำงานของโมเดลสอดคล้องกับการออกแบบของระบบมากขึ้น
การระบุเครื่องมือที่สามารถใช้ได้ผ่านโค้ด (API) เพียงอย่างเดียวมักไม่เพียงพอ โดยเฉพาะสำหรับโมเดลขนาดเล็ก เราควรอธิบายอย่างชัดเจนว่า
- เครื่องมือแต่ละตัวทำอะไร และควรใช้เมื่อใด
- ความสัมพันธ์ระหว่างเครื่องมือต่าง ๆ เป็นอย่างไร
- โมเดลควรทำอะไร ก่อน หรือ หลัง การใช้เครื่องมือแต่ละตัว
ความเข้าใจในระดับนี้ช่วยให้ agent สามารถวางแผนและให้เหตุผลได้อย่างเป็นระบบ แทนที่จะเพียงเรียกใช้เครื่องมือแบบไร้ทิศทาง
โบนัส: เขียนคำสั่งเป็นภาษาอังกฤษ (แม้ว่าโมเดลจะต้องตอบในภาษาอื่น)
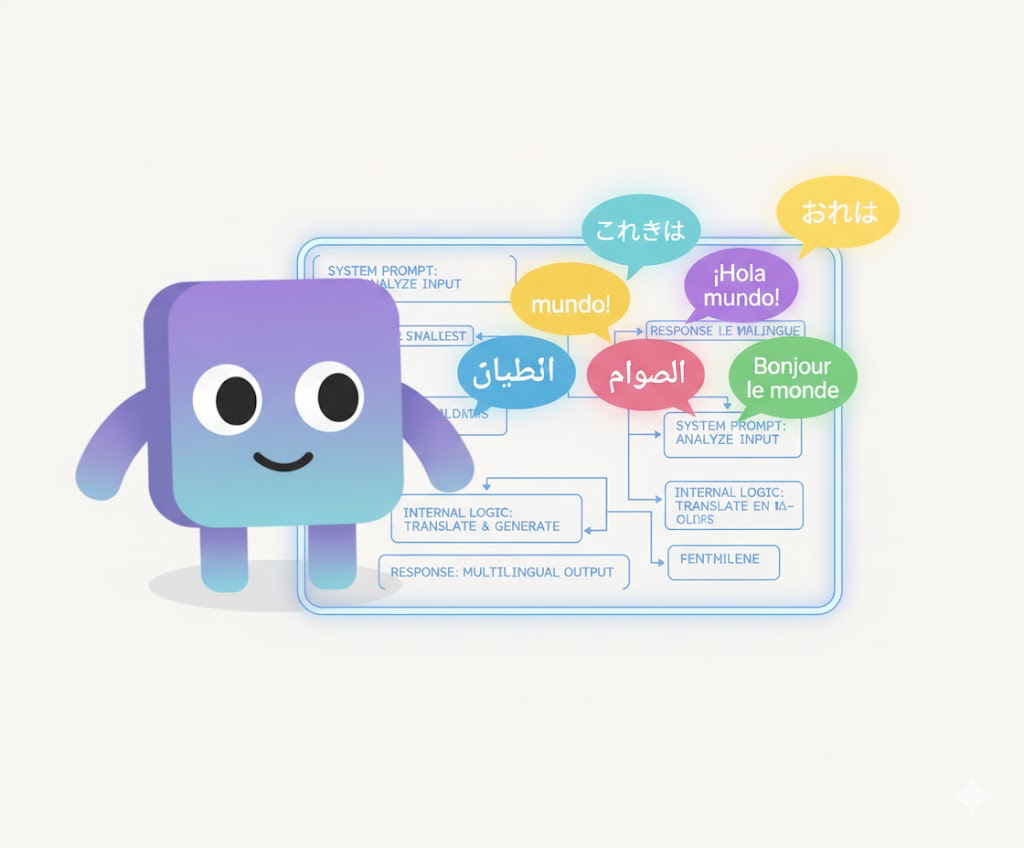
หลาย ๆ คนมักมองข้ามไป แต่ว่าการเขียน system prompt และคำอธิบายเครื่องมือเป็นภาษาอังกฤษ แม้ว่าผู้ใช้ของคุณจะโต้ตอบด้วยภาษาอื่น นั่นเป็นหนึ่งในเทคนิคที่สำคัญที่สุด
LLM สมัยใหม่ส่วนใหญ่ได้รับการฝึกด้วยข้อมูลภาษาอังกฤษเป็นหลัก ทำให้มีความสามารถในการเข้าใจและปฏิบัติตามคำสั่งภาษาอังกฤษได้แม่นยำกว่าภาษาอื่น การเขียนคำสั่งของระบบพื้นฐานเป็นภาษาอังกฤษจึงช่วยให้โมเดลตีความคำสั่งได้อย่างถูกต้องสูงสุด
ถึงแม้ว่า workflow ของเราจำเป็นจำต้องรองรับหลายภาษา (ข้อมูลนำเข้าและข้อมูลส่งออกของผู้ใช้ด้วยเป็นภาษาอื่น) แต่เราก็ควรให้ “ชั้นความคิด” (system prompts, internal notes, tool specs) เป็นภาษาอังกฤษไว้ในกรณีส่วนใหญ่ เพราะโดยทั่วไปจะช่วยให้การให้เหตุผลของโมเดลชัดเจนขึ้นและลดความไม่สอดคล้องได้มากเมื่อเป็นภาษาอังกฤษ ส่วนการตอบกลับไปยังผู้ใช้นั้นเพียงแค่ระบุให้โมเดลตอบกลับเป็นภาษาของผู้ใช้ก็จะช่วยให้รักษาประสบการณ์การใช้งานที่ดีได้แล้ว
สรุป Prompt Engineering
การออกแบบคำสั่งที่ดีไม่ใช่แค่เรื่องของการใช้ถ้อยคำที่ซับซ้อนหรือชาญฉลาดเท่านั้น แต่เป็นเรื่องของ ความชัดเจน ความสม่ำเสมอ และการควบคุมได้
คำสั่งที่ดีจะช่วยให้โมเดลคิดอย่างมีเหตุผล จดจ่อกับงาน และทำงานได้อย่างน่าเชื่อถือ เพราะท้ายที่สุดแล้ว คำสั่งที่ดีที่สุดคือคำสั่งที่ “กลืนไปกับ workflow” จนเหลือเพียงประสบการณ์การใช้งานที่ดีเท่านั้น
ขยายความสามารถของ LLM ด้วยเครื่องมือ

ถ้าคำสั่ง (prompts) กำหนดว่า LLM คิดอย่างไร เครื่องมือ (tools) ก็เป็นสิ่งที่กำหนดว่า มันจะลงมือทำอย่างไร
ใน agentic workflow “เครื่องมือ” หมายถึง ฟังก์ชัน (programmatic functions) ใด ๆ ที่ LLM สามารถเรียกใช้เพื่อเข้าถึงข้อมูลเพิ่มเติม หรือกระทำสิ่งใดที่ส่งผลต่อโลกภายนอก ตั้งแต่การสืบค้นฐานข้อมูล การอ่านไฟล์ ไปจนถึงการส่งข้อความหรือสร้างภาพ
อย่างไรก็ตาม การออกแบบเครื่องมือที่ดีไม่ใช่เรื่องง่าย เราต้องคิดเหมือนกับ LLM ซึ่งถูกปล่อยลงในสภาพแวดล้อมที่ไม่คุ้นเคย โมเดลมีความรู้เบื้องต้น และใช้เหตุผลได้ แต่ไม่รู้ว่ากลไกของโลกภายนอกทำงานอย่างไร เครื่องมือที่ออกแบบดีควรสื่อถึงวัตถุประสงค์ของเครื่องมือนั้น ๆ ได้ชัดเจน และเข้าใจความสามารถของเครื่องมือได้ง่าย รวมถึงช่วยชี้นำให้โมเดลใช้มันได้อย่างมีประสิทธิภาพ
เครื่องมือสามารถแบ่งออกได้เป็นสองประเภทใหญ่ ๆ
- เครื่องมือข้อมูล (Information tools) มอบความรู้เพิ่มเติมให้กับ LLM ในสิ่งที่มันยังไม่รู้ (เช่น ข้อมูลเฉพาะทาง โปรไฟล์ผู้ใช้ หรือข้อความที่สกัดจากภาพ)
- เครื่องมือลงมือทำ (Action tools) เปิดโอกาสให้ LLM เปลี่ยนแปลงสภาวะของโลก (เช่น การอัปเดตข้อมูล บันทึกไฟล์ หรือเรียกใช้ workflow ภายนอก)
ต่อไปนี้คือห้าหลักการสำคัญที่สุจากประสบการณ์ของผมที่ควรคำนึงถึงเมื่อออกแบบเครื่องมือสำหรับระบบแบบ agentic
หลักการข้อที่ 13: ตั้งชื่อ, เขียน doc, ส่งค่า
เช่นเดียวกับฟังก์ชันในซอฟต์แวร์ที่ควรจะดูแลรักษาได้ง่าย เครื่องมือที่ดีควรมี ชื่อที่ชัดเจน มีเอกสารกำกับ และซื่อสัตย์ ต่อสิ่งที่มันทำจริง ๆ
ตัวอย่างเช่น ตั้งชื่อของเครื่องมือให้เรื่มด้วยด้วย คำกริยา ที่บ่งบอกเจตนาอย่างชัดเจน เช่น fetch_user_profile, generate_summary, update_record ชื่อแต่ละชื่อควรสะท้อนวัตถุประสงค์ของเครื่องมือได้ทันที และ parameters ทุกตัวควรมีชื่อที่อธิบายได้เองและมีความหมาย นอกจากนี้ เอกสารประกอบ (documentation) ควรอธิบายอย่างครบถ้วนว่า เครื่องมือทำอะไร ใช้ เมื่อใด และ อินพุตและเอาต์พุต แต่ละอย่างมีความหมายอย่างไร ลองดูตัวอย่างของเครื่องมีที่ดีดังต่อไปนี้
และสิ่งที่สำคัญที่สุด อย่าโกหกโมเดล
หากเอกสารของฟังก์ชันระบุพฤติกรรมที่เครื่องมือไม่สามารถทำได้จริง LLM จะเชื่อและปฏิบัติตามตามนั้น เมื่อความเชื่อใจนี้ถูกทำลาย ระบบ workflow ทั้งหมดอาจพังทลายได้จากการที่ LLM พยายามดำเนินการบางอย่างด้วยฟังก์ชันที่ผิดแล้วติดอยู่ในลูป การจัดทำเอกสารที่ชัดเจนและซื่อสัตย์จึงเป็นรากฐานของความน่าเชื่อถือ ทั้งสำหรับมนุษย์และสำหรับโมเดล
นอกจากนี้ การสร้างเครื่องมือมักเป็นกระบวนการแบบ ลองผิดลองถูก (trial-and-error) แม้ว่าคุณจะตั้งชื่อเครื่องมือและเขียนเอกสารไว้อย่างดีแล้วก็ตาม LLM อาจยังตีความผิด หรือเข้าใจผิดว่าเครื่องมือสามารถทำสิ่งที่มันไม่สามารถทำได้ การใช้ EDD จะช่วยตรวจจับปัญหาเหล่านี้ โดยเปิดเผยจุดที่ความเข้าใจของโมเดลเบี่ยงเบนจากเจตนาของคุณ จากนั้นคุณสามารถปรับปรุงได้ต่อเนื่อง ไม่ว่าจะเป็นการเปลี่ยนชื่อเครื่องมือ การปรับแต่งคำอธิบาย หรือเพิ่มแนวทางและข้อจำกัดที่ชัดเจนว่าเครื่องมือสามารถหรือไม่สามารถทำอะไรได้บ้าง
สุดท้าย อย่าลืมว่า LLM ทำงานอยู่ใน โลกของภาษาธรรมชาติ ดังนั้นจึงมักจะดีกว่าที่จะส่งคืนผลลัพธ์ในรูปแบบข้อความที่อธิบายได้ชัดเจน การจัดโครงสร้างข้อมูลให้อ่านได้เข้าใจง่ายจะช่วยให้โมเดลเชื่อมโยงข้อมูลเหล่านั้นเข้ากับ context ได้ดีขึ้น และช่วยเพิ่มความแม่นยำในการตีความและให้เหตุผลของ LLM
หลักการข้อที่ 14: LLM ก็เหมือนวาทยากร

วิธีหนึ่งที่มีประโยชน์ในการทำความเข้าใจเครื่องมือ คือการจินตนาการว่า LLM เป็นนักประพันธ์เพลง (composer) และเครื่องมือของคุณคือ ทำนองดนตรีแต่ละท่อน
เครื่องมือแต่ละชิ้นควรทำหน้าที่ได้ครบถ้วนในตัวเอง เป็นการกระทำที่ชัดเจนและมีความหมาย แต่ไม่ควรซับซ้อนจน “เล่นทั้งเพลง” เอง
ในทางปฏิบัติ นั่นหมายถึงการมอบเครื่องมือให้ LLM ที่เป็น องค์ประกอบเชิงความหมาย (semantically meaningful building blocks) ซึ่งสามารถนำมาประกอบกันเพื่อบรรลุเป้าหมายได้ เช่นเดียวกับนักประพันธ์ที่เรียบเรียงทำนองจากวลีดนตรี LLM ก็ควรสามารถจัดเรียงการเรียกใช้เครื่องมือ (tool calls) เพื่อวางแผน ให้เหตุผล และลงมือทำได้อย่างยืดหยุ่น หากเครื่องมือมีความละเอียดเกินไป โมเดลจะติดอยู่กับรายละเอียดเล็ก ๆ น้อย ๆ แต่ถ้ามันเป็นนามธรรมเกินไป (เครื่องมือทำทั้งกระบวนการ) โมเดลก็จะสูญเสียการควบคุมเชิงสร้างสรรค์ สมดุลที่เหมาะสมจะทำให้ LLM “ประพันธ์” ได้อย่างมีประสิทธิภาพ มีเจตนาแน่ชัด แต่ยังสามารถด้นสดได้ภายในกรอบที่กำหนด
ลองมาดูตัวอย่างที่ชัดเจน สมมติว่าเรากำลังออกแบบ workflow สำหรับการสรุปอีเมล เราอาจเริ่มต้นด้วยเครื่องมือที่มีความละเอียดสูงมาก เช่น
ในกรณีนี้ LLM ต้องเรียกใช้ฟังก์ชันทุกตัวตามลำดับ เช่น connect_to_email_server() → fetch_email_headers() → fetch_email_body() → และอื่น ๆ เพียงเพื่อให้ได้ข้อความที่พร้อมใช้งาน โมเดลจึงกลายเป็นเพียง คนเรียกใช้ฟังก์ชัย (function executor) ไม่ใช่ระบบที่ให้เหตุผลได้จริง มันเพียงแค่ทำตามขั้นตอนแบบท่องจำ แทนที่จะวางแผนในระดับสูงอย่างมีโครงสร้างและความสร้างสรรค์
ตอนนี้ลองจินตนาการถึงอีกสุดขั้วหนึ่ง กับฟังก์ชันขนาดใหญ่เพียงตัวเดียวที่พยายามทำทุกอย่าง
สิ่งนี้นามธรรม เกินไป LLM ถูกลดบทบาทให้แค่กรอก arguments ให้คำสั่งสำเร็จรูป ทำให้สูญเสียความยืดหยุ่นในการออกแบบว่า “ขั้นตอนต่อไปควรทำอะไร”
ทั้งสองแบบไม่ใช่ทางเลือกที่ดีและสุดขั้วเกินไป
การออกแบบที่ดีกว่าคือการหาจุดกึ่งกลางที่พอดี เช่น
ตอนนี้ LLM สามารถ “ประพันธ์” การเรียกใช้ฟังก์ชันเหล่านี้ได้อย่างยืดหยุ่น: ดึงอีเมลใหม่ สรุป ย้ายที่เหลือไปเก็บถาวร ตอนนี้ระดับของความละเอียดในการทำงานมีความพอเหมาะแล้ว ทำให้โมเดลสามารถลงมือทำอย่างชาญฉลาด โดยไม่ทำให้ API ซับซ้อนเกินไป
ข้อสังเกตสำคัญอีกประการ คือ เรากำลังสร้างเครื่องมือ เพื่อให้ LLM ใช้ ไม่ใช่เพื่อโมดูลโค้ดส่วนอื่น ดังนั้นจงคิดกับ LLM ให้เหมือนผู้ร่วมงานมนุษย์ ไม่ใช่ส่วนประกอบในซอฟต์แวร์ นั่นหมายความว่าเครื่องมือแต่ละชิ้นไม่จำเป็นต้องเปิดเผย API เชิงเทคนิคในระดับต่ำสุด ที่จริงบ่อยครั้ง ไม่ควร ด้วยซ้ำ เครื่องมือที่ดีสามารถจัดการ หลายขั้นตอนเชิงกำหนด (deterministic) ภายในได้เอง (กระบวนการที่ควรทำเหมือนเดิมทุกครั้ง) ปล่อยให้โค้ดเชิงโปรแกรมที่ดูแลขั้นตอนเหล่านั้น แทนที่จะปล่อยให้ LLM ด้นสด (ซึ่งบางครั้งก็คาดเดาไม่ได้)
ตัวอย่างเช่น เราไม่ควรให้ LLM จัดการการชำระเงินแบบทีละขั้น “ดึงข้อมูล → ตรวจสอบ → ดำเนินการจ่ายเงิน” แล้วหวังว่าจะสมบูรณ์ไร้ที่ติทุกครั้ง และมันก็มีโอกาสสูงว่าจะไม่เป็นเช่นนั้น งานประเภทนี้ควรถูกรวมให้เรียบร้อยอยู่ในเครื่องมือเดียว แล้วให้ LLM เรียกใช้เมื่อจำเป็น
โดยสรุป งานที่เป็นเชิงกำหนดให้อยู่ในฟังก์ชัน งานที่ต้องตีความให้เป็นของ LLM อย่าเอาโน้ตดนตรีที่สะกดทุกตัวโน้ตไปให้โมเดล และก็อย่าขอให้มันแต่งซิมโฟนีจากศูนย์ จงมอบ “ท่อนเพลง” ที่แข็งแรงและนำกลับใช้ซ้ำได้ แล้วปล่อยให้มันประพันธ์เองภายในกรอบนั้น
หลักการข้อที่ 15: อธิบายข้อผิดพลาด
เราอาศัยอยู่ในโลกที่เต็มไปด้วยความไม่แน่นอน เซิร์ฟเวอร์อาจจะล่ม เครือข่ายอาจจะหลุด API อาจจะหมดเวลาก่อนได้ตอบกลับ ข้อผิดพลาดเป็นสิ่งที่หลีกเลี่ยงไม่ได้ ระบบที่ดีไม่ใช่ระบบที่ “ไม่มีข้อผิดพลาด” แต่คือระบบที่ จัดการข้อผิดพลาดอย่างโปร่งใส หลักการเดียวกันนี้ใช้ได้กับเครื่องมือเช่นกัน
หากเครื่องมือเกิดข้อผิดพลาดขึ้น มันควรสื่อสารข้อผิดพลาดนั้นอย่างชัดเจนด้วยภาษาธรรมชาติ แทนที่จะซ่อนหรือส่งกลับรหัสข้อผิดพลาดที่เข้าใจยาก วิธีนี้จะช่วยให้ LLM สามารถตัดสินใจได้ว่าจะจัดการอย่างไรต่อ เช่น จะลองใหม่อีกครั้ง เปลี่ยนวิธีการ หรือแจ้งผู้ใช้ให้ตัดสินใจ
เมื่อเครื่องมือเกิดข้อผิดพลาดแต่เลือกที่จะเงียบเอาไว้ (silent failure) โมเดลมักจะเข้าใจผิดว่าการทำงานสำเร็จ และดำเนินการให้เหตุผลต่อไปบนพื้นฐานที่ไม่ถูกต้อง ซึ่งอาจสร้างความเสียหายมากกว่าข้อผิดพลาดเดิมเสียอีก ดังนั้น ควรเปิดเผยปัญหาอย่างตรงไปตรงมาเสมอ เพื่อให้ agent สามารถตอบสนองได้อย่างชาญฉลาด
นอกจากนี้ตอบกลับด้วยข้อความผิดพลาดที่เข้าใจยาก (cryptic errors) แม้ว่าเราอาจมีรหัสข้อผิดพลาดภายในสำหรับใช้กันเองก็ตาม แต่ควรหลีกเลี่ยงใช้รหัสเหล่านั้นโดยตรง เพราะ LLM จะไม่เข้าใจว่ารหัสเหล่านั้นหมายถึงอะไร (และถ้ามัน “เข้าใจ” ขึ้นมา เราก็น่าจะต้องเริ่มกังวลแล้วว่าโมเดลรู้ได้อย่างไร ถ้าเราไม่เคยบอก!) ทางที่ดีควรสื่อสารข้อผิดพลาดอย่างชัดเจนในลักษณะบรรยาย และถ้าเป็นไปได้ ให้เพิ่มคำแนะนำที่ช่วยให้ LLM แก้ไขข้อผิดพลาดได้อย่างเหมาะสม
แน่นอนว่าบางข้อผิดพลาดสามารถให้เครื่องมือจัดการได้โดยตรงโดยไม่ต้องพึ่ง LLM หากการแก้ไขง่ายและชัดเจน ก็ไม่จำเป็นต้องผลักภาระนั้นไปให้ LLM จัดการเอง
หลักการข้อที่ 16: จริง ๆ แล้วเครื่องมือเป็นอะไรก็ได้
“เครื่องมือ” (tool) จริง ๆ แล้วก็คือฟังก์ชันหนึ่งเท่านั้น และฟังก์ชันนั้นสามารถทำอะไรก็ได้ ไม่จำเป็นต้องจำกัดอยู่แค่ API หรือฐานข้อมูลเท่านั้น แต่ยังสามารถเรียกใช้ โมเดลอื่น ๆ ได้ด้วย
ตัวอย่างเช่น
- โมเดล OCR สามารถกลายเป็นเครื่องมือที่ช่วยให้ LLM ซึ่งทำงานเฉพาะกับข้อความ สามารถอ่านข้อความจากภาพได้
- โมเดลสร้างภาพ (generative image model) สามารถทำหน้าที่เป็นเครื่องมือที่ช่วยให้ agent “วาดภาพ” จากสิ่งที่โมเดลจินตนาการขึ้นมา
- โมเดลให้เหตุผลขนาดเล็ก (small reasoning model) สามารถทำหน้าที่เป็นเครื่องมือช่วยในงานจำแนกประเภทหรือสรุปข้อมูลเฉพาะทาง
ความสามารถในการประกอบรวมกันได้ (composability) แบบนี้ช่วยขยายศักยภาพของ agent ได้อย่างมาก เมื่อเชื่อมต่อ LLM เข้ากับโมเดลอื่น ๆ ผ่านเครื่องมือที่ออกแบบอย่างดี เราก็สามารถสร้างระบบที่ทำงานกับข้อมูลประเภทอื่น (multi-modal) หรือทำงานกับโมเดลจำนวนมาก (multi-agent) ที่แต่ละองค์ประกอบมีความเชี่ยวชาญเฉพาะของตนเองและทำงานร่วมกันได้อย่างกลมกลืน
หลักการข้อที่ 17: ต้องใช้เครื่องมือจริง ๆ หรอ?
บางครั้ง เครื่องมือที่ดีที่สุดคือไม่ต้องมีเครื่องมือเลย
โมเดลแต่ละตัวมีพฤติกรรมต่างกัน บางตัวมีแนวโน้มที่จะเรียกใช้เครื่องมือบ่อยเกินไป แม้คำตอบจะมีอยู่แล้วใน context ปัจจุบันก็ตาม ซึ่งอาจทำให้ workflow ช้าลง เปลืองโทเค็น และเกิดการเรียกใช้เครื่องมือซ้ำซ้อนโดยไม่จำเป็น วิธีแก้ที่เรียบง่ายแต่มักได้ผลดีคือการ กำหนดคำสั่งให้โมเดลตรวจสอบข้อมูลใน context ที่มีอยู่ ก่อนที่จะเรียกใช้เครื่องมือใด ๆ โดยสามารถระบุไว้ใน system prompt หรือในขั้นตอนของ workflow ได้เลย
การเตือนเล็ก ๆ แบบนี้มักช่วยป้องกันการเรียกใช้เครื่องมือโดยไม่จำเป็น และทำให้ agent ประพฤติตัวเหมือน “นักวางแผนที่รอบคอบ” มากกว่า “ผู้เรียก API โดยสัญชาตญาณ”
สรุปเรื่องการใช้เครื่องมือ
เครื่องมือ (tools) คือสิ่งที่ทำให้ LLM สามารถเชื่อมโยงระหว่าง ความคิด และ การกระทำ ได้ มันขยายขอบเขตทั้งในสิ่งที่โมเดล “รู้” และสิ่งที่มัน “ทำได้” แต่ในขณะเดียวกัน เครื่องมือที่เราออกแบบก็มีส่วนกำหนดพฤติกรรมของโมเดลเช่นกัน เครื่องมือที่มีชื่อชัดเจน มีเอกสารครบถ้วน และมีขอบเขตที่เหมาะสม จะช่วยให้ agent ทำงานได้อย่างมีประสิทธิภาพ ส่วนเครื่องมือที่ออกแบบไม่ดีจะทำให้มันสับสนหรือถูกจำกัด
การออกแบบเครื่องมืออย่างตั้งใจโดยปล่อยให้รายละเอียดเชิงกำหนด (deterministic details) อยู่ภายในฟังก์ชัน และให้ LLM เป็นผู้ควบคุมการทำงานเหล่านั้นด้วยความคิดสร้างสรรค์และเป้าหมายที่ชัดเจน เพราะนั่นคือจุดที่ “ความฉลาดที่แท้จริง” ปรากฏขึ้น ไม่ใช่แค่ใน การคิด แต่ใน การลงมือทำอย่างถูกทาง ด้วย
Agentic Workflow รวมทุกสิ่งเข้าด้วยกัน
ตอนนี้เรามีทั้งคำสั่ง (prompts) ที่ดีและเครื่องมือ (tools) ที่ชาญฉลาดแล้ว ก็ถึงเวลานำพวกมันมาทำงานร่วมกัน ซึ่งนั่นก็คือบทบาทของ agentic workflow
โดยพื้นฐานแล้ว agentic workflow คือแนวทางในการเชื่อมโยงวิธีที่ LLM “คิด” “กระทำ” และ “ให้เหตุผล” ตลอดเวลา มันคือวิธีที่คำสั่ง เครื่องมือ และ context ทำงานร่วมกันจนกลายเป็นระบบที่ปรับตัวได้ และไม่เพียงแค่ “ตอบสนอง” แต่ยัง “แสดงพฤติกรรม” อย่างมีจุดมุ่งหมาย
แต่ก่อนที่เราจะเริ่มวาดแผนผังการทำงาน ลองถามคำถามง่าย ๆ ที่สำคัญก่อนว่า
บางครั้งคำตอบก็คือ “ไม่”
หากกรณีของคุณเรียบง่าย เช่น เพียงต้องการดึงข้อมูลบางอย่างหรือประมวลผลงานสั้น ๆ คำสั่ง (prompt) ที่ออกแบบดีและเครื่องมือไม่กี่ชิ้นก็เพียงพอแล้ว ไม่จำเป็นต้องสร้างระบบให้ซับซ้อนเกินไป
แต่เมื่อสถานการณ์เริ่มซับซ้อนขึ้น เมื่อระบบต้องให้เหตุผลหลายขั้นตอน ตัดสินใจด้วยตนเอง หรือทำงานร่วมกันข้ามขอบเขต นั่นคือเวลาที่คุณควรเริ่มคิดในมุมของ workflow
และนี่คือแนวคิดสำคัญที่เป็นตัวชี้ชะตาว่า workflow จะดีหรือไม่ดี
นั่นแหละคือสิ่งที่เปลี่ยน LLM จากเพียงแค่แชตบอต ให้กลายเป็นผู้ช่วยส่วนตัว
หลักการข้อที่ 18: Agent Loop
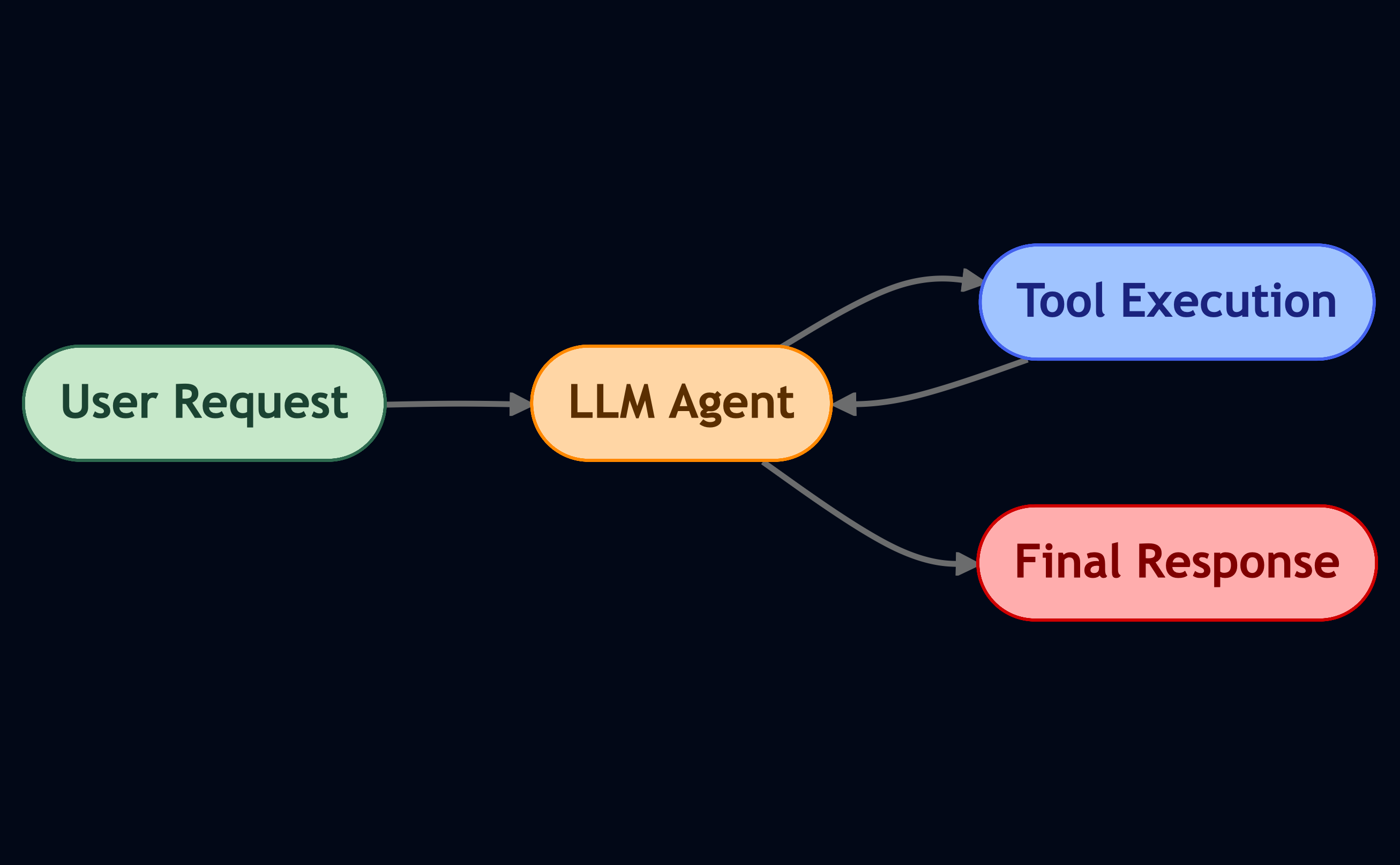
เริ่มจากพื้นฐานกันก่อน Agent loop คือหัวใจของระบบแบบ agentic ส่วนใหญ่
มันคือรูปแบบคลาสสิกของ “คิด–ทำ–สังเกต” (think–act–observe) เมื่อ LLM ได้รับคำขอ มันจะคิดว่าจะทำอะไร จากนั้นอาจเรียกใช้เครื่องมือ รับผลลัพธ์กลับมา สังเกตผลลัพธ์แล้วคิดถึงขั้นตอนถัดไป แล้ววนซ้ำไปเรื่อย ๆ จนกว่าจะพร้อมตอบกลับ
หากเคยได้ยินเกี่ยวกับ ReAct มันก็คือแนวคิดคล้าย ๆ กันเนี่ยแหละ การให้เหตุผล (reasoning) + การลงมือทำ (acting) ภายในลูปเดียว
ลองนึกถึงสิ่งนี้ว่าเป็น “บทพูดภายในใจ” ของ LLM มันให้เหตุผล เรียกใช้เครื่องมือ ดูผลลัพธ์ แล้วตัดสินใจว่าจะทำอะไรต่อไป
นอกจากนี้เรายังสามารถเพิ่ม โหนดที่ไม่ใช่ LLM ลงในลูปได้ด้วย เช่น ฟังก์ชันเชิงกำหนด (deterministic function) สำหรับจัดการสิ่งที่ไม่ต้องการให้โมเดลด้นสดเอง
สมดุลระหว่างส่วนที่เป็นเชิงกำหนดและส่วนที่เป็นเชิงสร้างสรรค์นี้เอง คือสิ่งที่ทำให้ workflow ทรงพลังและควบคุมได้ในเวลาเดียวกัน
หลักการข้อที่ 19: Human in the Loop

บางครั้ง agent ก็อาจต้องการ “ความช่วยเหลือเล็กน้อย” หรืออย่างน้อยก็แค่ให้ใครสักคนช่วยตรวจสอบความถูกต้อง นั่นคือจุดที่รูปแบบ human-in-the-loop เข้ามามีบทบาท
เราสามารถออกแบบระบบให้เมื่อใดก็ตามที่ LLM มาถึงจุดตัดสินใจสำคัญ มันจะ “หยุดชั่วคราว” เพื่อรอการยืนยันจากมนุษย์ก่อนดำเนินการต่อ การหยุดแบบนี้เรียกว่า interrupt แนวคิดที่ยืมมาจากระบบปฏิบัติการ (operating systems) ซึ่งกระบวนการหนึ่งจะหยุดชั่วคราวจนกว่าจะได้รับสัญญาณภายนอกให้ทำงานต่อ
รูปแบบนี้มีประโยชน์อย่างยิ่งในกรณีที่คุณไม่ต้องการให้ agent ดำเนินการอัตโนมัติกับงานที่อ่อนไหว เช่น การส่งอีเมลจริง หรือการแก้ไขข้อมูลในฐานข้อมูล มันช่วยให้มนุษย์ยังคงควบคุมระบบได้ ขณะเดียวกันก็เปิดโอกาสให้ระบบทำงานแบบอัตโนมัติได้เป็นส่วนใหญ่
หลักการข้อที่ 20: ความทรงจำ
ถ้าทุกคนเคยทำงานกับ LLM มานานพอ ทุกคนคงรู้ดีว่าความจำของมันนั้น...ไม่ค่อยดีเท่าไรนัก โมเดลจำได้แค่สิ่งที่อยู่ใน context window ของมัน และการขยายขอบเขตนั้นก็มีต้นทุนที่สูงมาก
ตรงนี้เองที่ กลไกหน่วยความจำ (memory mechanisms) สามารถเข้ามาช่วยได้ แทนที่จะเก็บทุกอย่างไว้ทั้งหมด ระบบ workflow ที่ดีจะใช้ “หน่วยความจำอย่างมีกลยุทธ์” ดังนี้:
- หน่วยความจำระยะสั้น (Short-term memory) สรุปของการกระทำล่าสุดและผลลัพธ์จากเครื่องมือ
- หน่วยความจำระยะกลาง (Mid-term memory) บันทึกแบบมีโครงสร้างหรือแผนงานที่คงอยู่ระหว่างลูป แต่ยังอยู่ในเซสชันเดียวกัน
- หน่วยความจำระยะยาว (Long-term memory) ระบบภายนอก เช่น Mem0 หรือ vector store ที่ช่วยให้โมเดลเรียกข้อมูลจากเซสชันก่อนหน้าได้
ลองนึกถึงวิธีที่เราจำสิ่งต่าง ๆ เราไม่ได้จำทุกคำของบทสนทนา แต่จำเฉพาะ “สาระสำคัญ” เท่านั้น agent ของคุณก็ควรทำงานแบบเดียวกัน
โบนัส: เทคนิค Pub/Sub

นี่คือเคล็ดลับเล็ก ๆ ที่ทำให้ workflow รู้สึกเหมือน “มีชีวิต” นั่นคือ Pub/Sub
ใน workflow ที่ทำงานยาวนาน agent อาจใช้เวลาคิด เรียกใช้เครื่องมือ และปรับแต่งผลลัพธ์ แทนที่จะปล่อยให้ผู้ใช้จ้องดูตัวโหลดหมุนไปเรื่อย ๆ เราสามารถเผยแพร่ (publish) อัปเดตระหว่างทาง (เช่น “กำลังดึงข้อมูล…”, “กำลังวิเคราะห์เอกสารที่ 3 จาก 5”) ผ่านแนวการออกแบบระบบที่เรียกว่า Pub/Sub เหมือนที่ระบบซอฟต์แวร์ทั่วไปใช้กัน
สิ่งนี้ช่วยให้ผู้ใช้รับรู้ความคืบหน้า และ สร้างความเชื่อมั่นในระบบได้ในเวลาเดียวกัน
ในระบบที่ซับซ้อนยิ่งขึ้น workflows ยังสามารถ “สมัครรับข้อมูล” (subscribe) จากกันและกันได้ด้วย เช่น เมื่อ workflow หนึ่งทำงานถึงจุดหนึ่ง ก็สามารถกระตุ้นให้ workflow อื่นเริ่มทำงานต่อได้ ช่วยให้ทุกอย่างทำงานประสานกันอย่างลงตัว
Workflow แบบมี Agent ตัวเดียวหรือหลายตัว
เอาละ ลองถอยออกมาพิจารณาเรื่องนี้กันหน่อย
Workflow แบบมี Agent ตัวเดียว
นี่คือโครงสร้างพื้นฐานที่ง่ายที่สุดของคุณ มีเพียง LLM เครื่องมือไม่กี่ชิ้น และลูป
มันเรียบง่าย ยืดหยุ่น และเหมาะสำหรับการสร้างต้นแบบ (prototype) แต่เมื่อระบบของคุณเติบโตขึ้น ทุกอย่างก็อาจเริ่มซับซ้อนขึ้นอย่างรวดเร็ว Agent เพียงตัวเดียวต้องรับมือกับเครื่องมือและความรับผิดชอบมากเกินไป จนเกิดความสับสน หรือแม้กระทั่งการ “มโนคำตอบ” (hallucination) ขึ้นมาได้
Workflow แบบมี Agent หลายตัว
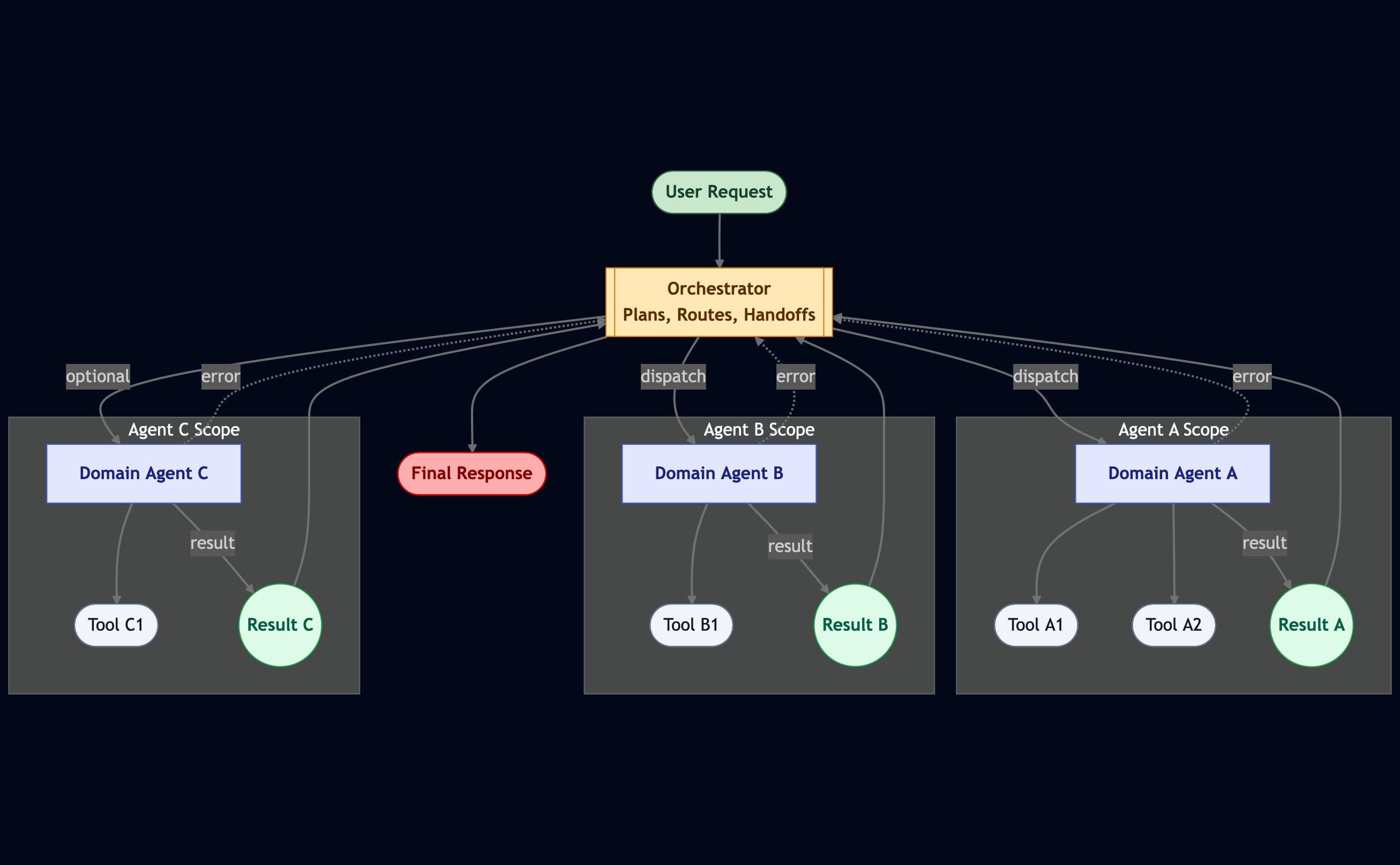
เมื่อ workflow เริ่มมีขนาดใหญ่ขึ้น ก็ถึงเวลาที่ต้องใช้กลยุทธ์ แบ่งแล้วยึดครอง (divide and conquer)
ใน multi-agent workflow แต่ละ agent ควรจะรับผิดชอบโดเมนเฉพาะของตน เช่น agent ที่เก่งในการวิจัย agent ที่เก่งในการเขียน หรืออื่น ๆ
แต่ละ agent จะมีเครื่องมือ บุคลิก และจุดโฟกัสของตัวเอง วิธีนี้ช่วยให้ context อยู่ในรูปแบบที่ดี ลดความสับสน และยังสามารถเร่งความเร็วของระบบได้เมื่อบางส่วนของ workflow ทำงานแบบขนาน (parallel)
แน่นอนว่า สิ่งนี้ก็มาพร้อมกับความท้าทายใหม่นั่นก็คือ การประสานงาน (coordination)
ใครจะเป็นผู้ตัดสินว่า agent ตัวไหนควรทำงานใด? แล้วจะจัดการการส่งต่องาน (handoff) อย่างไร?
ตรงนี้เองที่ orchestrator เข้ามามีบทบาท orchestrator เป็น agent พิเศษที่ทำหน้าที่ถือแผนภาพรวม กำหนดงานให้แต่ละ agent และปรับแผนแบบไดนามิกเมื่อผลลัพธ์เริ่มเข้ามา ลองนึกถึง orchestrator ว่าเป็น “วาทยากร” ของวงออร์เคสตรา AI มันทำให้แน่ใจว่า “ทุกคนเล่นเพลงเดียวกัน” และไม่มีใคร “แย่งเสียงกันเอง”
การตั้งค่าระบบแบบ multi-agent ยังช่วยแก้ปัญหาใหญ่อีกอย่างหนึ่งด้วย: แทนที่จะมี mega-prompt เดียวที่พยายามครอบคลุมทุกอย่าง เราจะออกจะได้คำสั่งที่มีขนาดเล็กแต่เฉพาะทางสำหรับแต่ละ agent แทน
ผลลัพธ์คือระบบที่สะอาดกว่า เร็วกว่า และดูแลง่ายกว่า โดยเฉพาะเมื่อเราใช้ LLM ขนาดเล็กหลายตัวร่วมกัน
สรุปเรื่องจำนวน Agent
เริ่มจากสิ่งที่เรียบง่ายก่อน นั่นก็คือการใช้ agent loop เพียงตัวเดียว จากนั้นค่อยเพิ่มมนุษย์ (human-in-the-loop) หรือจุด interrupt เข้ามาเมื่อจำเป็น และขยายระบบด้วยการ orchestrate เมื่อความซับซ้อนเพิ่มขึ้น
นั่นแหละคือเส้นทางจาก “แชตบอตธรรมดา” ไปสู่ ระบบที่สามารถคิด วางแผน และทำงานร่วมกันได้จริง
เลือกโมเดลยังไงดี?

ตอนนี้เราได้พูดถึงเรื่อง คำสั่ง เครื่องมือ และ workflows กันไปแล้ว มาปิดท้ายด้วยคำถามที่หลายคนมักจะถามมากที่สุด
ทุกวันนี้มีตัวเลือกของโมเดลมากมายให้เลือกใช้ แต่โดยทั่วไปแล้ว โมเดลเหล่านี้สามารถแบ่งออกได้เป็นไม่กี่หมวดหลัก ๆ ซึ่งแต่ละหมวดก็มีทั้งข้อดี ข้อจำกัด และจุดเหมาะสมในการใช้งานแตกต่างกันไป
โมเดลแบบใช้เหตุผล หรือ LLMs

ปัจจุบันคุณจะเห็นโมเดลอยู่สองประเภทใหญ่ ๆ คือ LLMs และโมเดลที่ใช้เหตุผล (reasoning models)
โมเดลที่ใช้เหตุผล เป็นโมเดลกลุ่มใหม่ของ LLM ที่ออกแบบมาเพื่อคิดให้นานขึ้นก่อนจะให้คำตอบ โมเดลพวกนี้ใช้เวลา “คิด” นานขึ้นแต่โดยทั่วไปจะให้ผลลัพธ์ที่ดีกว่าในงานที่ซับซ้อนหรือมีหลายขั้นตอน เช่น การเรียกใช้เครื่องมือหลายตัว (tool chain) หรือการให้เหตุผลข้ามเอกสารหลายชุด
ดังนั้น หาก workflow เกี่ยวข้องกับการให้เหตุผลเชิงลึก การเรียกใช้เครื่องมือหลายครั้ง หรือการตัดสินใจที่ซับซ้อนแบบไดนามิก การเลือกใช้ โมเดลที่ใช้เหตุผล ก็มักคุ้มค่ากับเวลาประมวลผลที่เพิ่มขึ้น
ที่น่าสนใจก็คือ แม้ โมเดลที่ใช้เหตุผลจะ “ช้ากว่าในทฤษฎี” แต่บางครั้งโมเดลเหล่านี้กลับสามารถทำงานเสร็จเร็วกว่าในทางปฏิบัติ เพราะมักให้คำตอบที่ถูกต้องตั้งแต่ครั้งแรก แทนที่จะต้องใช้เวลาซ้ำไปมาเพื่อแก้ไขข้อผิดพลาด
ถ้าใครไม่รู้ว่าจะเริ่มต้นกับโมเดลไหนดี ผมเองขอแนะนำ Typhoon 2.5 โมเดลภาษาเวอร์ชันล่าสุดจาก Typhoon ที่ถูกออกแบบมาสำหรับงานแบบ agentic โดยเฉพาะ พร้อมกับความสามารถด้านภาษาไทยที่ดีขึ้น หรือถ้าใครอยากลองใช้โมเดลที่ใช้เหตุผล Typhoon เองก็มี Typhoon 2.1 Gemma โมเดลภาษาแบไฮบริดที่สามารถเปิดโมเดลใช้เหตุผลเพื่อให้โมเดลคิดนานขึ้นได้
ทุกวันนี้เองโลกของ AI ไปไวมาก และโมเดลใหม่ ๆ ก็มาอยู่ตลอด ถ้าใครอยากรู้ว่าตอนนี้มีโมเดลอะไรกำลังอินเทรนด์อยู่ หรือว่าโมเดลไหนกำลังเป็นที่นิยม ผมแนะนำให้ติดตามหน้า Hugging Face Models ซึ่งจะจัดอันดับโมเดลตามความนิยม ทำให้ไม่หลุดเทรนด์แน่นอน
Multimodal Models เพิ่มประสาทสัมผัสให้กับโมเดล

นอกจากโมเดลที่ทำงานกับข้อความเท่านั้นแล้ว ตอนนี้ multimodal LLMs ก็เริ่มเป็นที่แพร่หลายและเข้าถึงได้มากขึ้นเรื่อย ๆ
ลองนึกถึงโมเดลเหล่านี้เหมือนกับการ “เพิ่มประสาทสัมผัส” ให้กับ agent เสมือนกับเพิ่มตาและหูให้กับโมเดล โมเดลแบบ multimodal สามารถประมวลผลภาพ ภาพหน้าจอ กราฟ แผนภูมิ หรือแม้แต่เสียงได้ ซึ่งเปิดประตูสู่งานรูปแบบใหม่ เช่น การค้นหาด้วยภาพ (visual search) การทำความเข้าใจเอกสาร (document understanding) หรือการให้เหตุผลแบบข้อมูลหลายประเภท(multimodal reasoning)
หาก workflow ของเราจำเป็นต้องเชื่อมโยง “ภาษา” เข้ากับ “การรับรู้” เช่น การอ่านกราฟ วิเคราะห์ไฟล์ PDF หรือบรรยายภาพ โมเดลแบบ multimodal คือสิ่งที่ควรลองใช้
ว่าด้วยเรื่องของขนาด ใหญ่ขึ้นก็ไม่ได้ดีขึ้นเสมอไป

เมื่อพูดถึงการเลือกขนาดของโมเดล จริง ๆ แล้ว ไม่มีสูตรตายตัว โดยทั่วไปแล้ว โมเดลขนาดใหญ่จะให้ประสิทธิภาพที่ดีกว่า แต่ก็มาพร้อมกับต้นทุนที่สูงขึ้นและเวลาตอบสนองที่ช้าลง ขณะที่โมเดลขนาดเล็กกลับสามารถทำงานได้ดีเกินคาด โดยเฉพาะเมื่อเราออกแบบ คำสั่ง และ context ได้อย่างเหมาะสม
เคล็ดลับคือการจับคู่ขนาดของโมเดลให้เหมาะกับ ความซับซ้อนของ workflow และ ระดับความทนต่อความหน่วง (latency tolerance) ของความต้องการ
- สำหรับงานที่ต้องโต้ตอบแบบเรียลไทม์หรือความเร็วสูง โมเดลขนาดเล็กมักเป็นตัวเลือกที่ดีที่สุด
- สำหรับงานที่ต้องใช้การให้เหตุผลเชิงลึกหรือความแม่นยำสูง ควรเลือกโมเดลที่ใหญ่กว่า
และอย่าลืมว่า โมเดลขนาดเล็กยังเปิดโอกาสให้คุณทำ fine-tuning ได้ง่ายกว่า ซึ่งสามารถทำให้มันเชี่ยวชาญเฉพาะด้านและมีประสิทธิภาพสูงได้อย่างน่าประทับใจในโดเมนเฉพาะ
ที่ Typhoon 2.5 เองก็มีให้เลือกสองขนาด ทั้งขนาดเล็ก 4B และขนาดที่ใหญ่ขึ้นมาอีกนิด 30B A3B ให้ทุกคนได้เลือกตามความเหมาะสม ซึ่งเจ้าตัว 30B เนี่ย มีความพิเศษตรงที่มันเป็นโมเดลแบบ Mixture-of-Experts (MoE) นั่นหมายความว่าตอนใช้งานจริงโมเดลตัวนี้นั้น activate พารามิเตอร์ขึ้นมาแค่ 3B เท่านั้น (เล็กกว่าโมเดล 4B อีก!) ทำให้เราได้ผลลัพธ์ที่เร็วขึ้นและฉลาดขึ้น แต่อย่างไรก็ตามโมเดลขนาด 30B นั้นก็ต้องการหน่วยความจำที่เพียงพอสำหรับใส่พารามิเตอร์ทั้งหมด 30B แม้ว่าจะใช้แค่ 3B ก็ตาม สำหรับข้อมูลเพิ่มเติมเกี่ยวกับการรันโมเดล ทุกคนสามารถเข้าไปดูได้ที่ คำแนะนำด้านฮาร์ดแวร์ในการโฮสต์
สั่ง (Prompting) ปรับ (Fine-Tuning) ปรับคำสั่ง (Prompt Optimization)

ในกรณีส่วนมากแล้ว เราไม่จำเป็นต้องทำการ fine-tune โมเดลเลย
การออกแบบคำสั่ง และ context ที่ดีสามารถพาเราไปได้ไกลมาก และทั้งสองอย่างนี้ยังสามารถปรับแต่งได้รวดเร็วและประหยัดกว่ามาก การปรับแต่งด้วยคำสั่งยังให้ วงจรป้อนกลับทันที (immediate feedback loop) (ปรับ → ทดสอบ → เห็นผลได้เลย)
อย่างไรก็ตาม การ fine-tune ก็ยังมีประโยชน์ในบางกรณี โดยเฉพาะเมื่อเรามีชุดข้อมูลที่คัดกรองมาอย่างดี และต้องการให้โมเดล “ซึมซับ” รูปแบบการเขียนเฉพาะ หรือความรู้ในโดเมนที่เฉพาะเจาะจง เพียงแต่ควรจำไว้ว่าการ fine-tune ต้องใช้เวลา ทรัพยากรประมวลผล และการทดลองหลายรอบ
แต่ก็ยังมีทางสายกลางอยู่ นั่นก็คือการปรับคำสั่งแบบอัตโนมัติ (automatic prompt optimization)
ถ้าเรามีชุดการประเมินผล (evaluation suite) อยู่แล้ว (ซึ่งควรมี!) เราสามารถใช้มันเป็นชุดตรวจสอบ (validation set) สำหรับการปรับแต่งคำสั่งโดยอัตโนมัติได้ เครื่องมืออย่าง DSPy ช่วยให้กระบวนการนี้เป็นระบบ ทำซ้ำได้ และมีต้นทุนต่ำกว่าการ fine-tune เต็มรูปแบบมาก
สรุปเรื่องการเลือกโมเดล
สุดท้ายแล้ว การเลือกโมเดลไม่ใช่เรื่องของการไล่ตามรุ่นที่ “ใหญ่ที่สุด” หรือ “ใหม่ที่สุด”
แต่มันคือการ เลือกพาร์ตเนอร์ที่เหมาะสม สำหรับ workflow ในเคสนั้น ๆ โมเดลที่สอดคล้องกับเป้าหมายของระบบ ความเร็วที่ต้องการ และระดับความซับซ้อนของการให้เหตุผล
หากเราออกแบบ context ได้ดี รักษา workflow ให้กระชับ และประเมินผลอย่างต่อเนื่อง ไม่ว่าโมเดลจะเป็นขนาดเล็ก ขนาดใหญ่ แบบ reasoning หรือแบบ multimodal เราก็จะสามารถแสดงศักยภาพสูงสุดได้
และถ้าทุกคนกำลังสงสัยว่าจะเริ่มต้นจากตรงไหนดี ผมก็มีคำตอบให้
Typhoon มีชุดโมเดลหลากหลายให้ทดลองใช้ ไม่ว่าคุณจะต้องการโมเดลที่เบาและตอบสนองเร็ว หรือโมเดลที่ “คิดก่อนตอบ” ได้ Typhoon ก็มีโมเดลเหล่านี้อยู่ เรารอให้ทุกคนลองนำไปใช้และหวังว่าทุกคนจะได้รับผลลัพธ์ที่เยี่ยมยอด!
โบนัส: โมเดลอื่น ๆ ใน Agentic Workflows

แม้ว่าบทความนี้จะพูดถึงการใช้ LLM เป็นหลัก แต่ก็ไม่ได้หมายความว่า workflow จะต้อง พึ่งพา LLM เพียงอย่างเดียว ยังมีโมเดลแมชชีนเลิร์นนิง (ML models) อีกมากมายที่สามารถทำงานบางอย่างได้ เร็วกว่า ถูกกว่า และดีกว่า
ตัวอย่างเช่นในบาง workflow อาจจะมี classifier ที่ใช้ระบุเจตนาของผู้ใช้ (user intent) และส่งคำขอต่อไปยัง agent หรือเครื่องมือที่เหมาะสม แน่นอนว่าเราสามารถใช้ LLM ทำงานนี้ได้ แต่ก็ไม่ใช่ทางเลือกที่ดีที่สุดเสมอไป เพราะ LLM มักมีขนาดใหญ่กว่าโมเดลอื่น ๆ ทำงานช้า และมีต้นทุนสูงสำหรับงานที่เรียบง่ายเช่นนี้ โมเดลขนาดเล็กที่ผ่านการปรับแต่ง เช่น BERT-based classifierมักจะทำงานได้ดีกว่าและตอบสนองแทบจะทันที
ในทำนองเดียวกัน แม้ว่า vision-language model จะสามารถจัดการงานเข้าใจภาพทั่วไปได้ แต่ก็อาจ “เกินความจำเป็น” สำหรับงานเฉพาะทางอย่าง object detection ซึ่งในกรณีนั้น โมเดลเฉพาะทางอย่าง YOLO มักจะเร็วกว่า แม่นยำกว่า และคาดการณ์ผลลัพธ์ได้ดีกว่า
การผสมผสานโมเดลเหล่านี้เข้าด้วยกัน ใช้ LLM สำหรับการให้เหตุผลและการจัดการ (reasoning & orchestration) และใช้โมเดลขนาดเล็กสำหรับการรับรู้ (perception) หรือการจำแนก (classification) มักจะให้ผลลัพธ์ที่ดีที่สุดและปิดจุดอ่อนของกันและกัน ทำให้เราได้ระบบที่ฉลาดขึ้นและมีประสิทธิภาพมากขึ้นในเวลาเดียวกัน
และอย่าลืมว่า LLM สามารถสร้างได้เพียง “ข้อความ” เท่านั้น หาก workflow ของคุณต้องสร้างเนื้อหาประเภทอื่น เช่น ภาพ เสียง หรือวิดีโอ ควรมอบหมายให้โมเดลสร้างเนื้อหา (generative AI) เฉพาะทาง จัดการแทน โมเดลเหล่านี้สามารถแปนแผนการของ LLM ออกมาเป็นสิ่งที่จับต้องได้มากขึ้น เช่น text-to-image, text-to-music หรือ text-to-video
สรุปสั้น ๆ อย่ามองว่า LLM คือ “วงออร์เคสตราทั้งหมด” บางครั้งทางเลือกที่ฉลาดที่สุดคือปล่อยให้โมเดลอื่น ๆ เล่นบทของมัน แล้วให้ LLM ทำหน้าที่เป็น “วาทยากร” ที่ควบคุมจังหวะทั้งหมดแทน
บทส่งท้าย

ปฏิเสธไม่ได้เลยว่าตอนนี้เรากำลังอยู่ ณ จุดเริ่มต้นของยุค agentic นี่คือช่วงเวลาที่ LLMs เปลี่ยนผ่านจากการเป็นเพียงแชทบอทที่ตอบโต้ได้ไปเป็นผู้ร่วมงานอย่างแท้จริง การเปลี่ยนคำสั่ง (prompt) หรือเครื่องมือ (tools) ไม่เพียงพอแล้วอีกต่อไปสำหรับการสร้างระบบต่าง ๆ เหล่านี้ มันเกี่ยวข้องกับการออกแบบ context อย่างเป็นระบบ การทดสอบ และการสร้าง workflow ที่สามารถคิดและปรับตัวได้
ถ้าเกิดจะมีอะไรซักอย่างนึงที่เป็นเหมือน theme ตลอดบทความนี้ นั่นคงเป็นว่า
ความมหัศจรรย์ไม่ได้เกิดจากโมเดลเพียงอย่างเดียวเท่านั้น แต่ขึ้นอยู่กับสิ่งต่างๆที่สร้างขึ้นมารอบโมเดลด้วย
ความสงสัย (curiosity) และการลองลงมือทำเป็นสิ่งที่ขาดไม่ได้อีกต่อไป ทุก ๆ ไอเดียที่ลองลงมือแก้ไข ไม่ว่าจะเป็นคำสั่ง เครื่องมือ โมเดล หรือ workflow ต่างก็สามารถช่วยให้ระบบพัฒนาไปได้อีกขั้น นี่แสดงให้เห็นถึงการร่วมมือกันระหว่างความคิดสร้างสรรค์ของมนุษย์และการประมวลของ AI
เพราะฉะนั้นอยากให้ทุกคนมองสิ่งต่าง ๆ เหล่านี้ให้เหมือนกับห้องทดลองขนาดใหญ่ที่เราสามารถลองเล่นอะไรก็ได้ เรียนรู้สิ่งต่าง ๆ ผ่านการลงมือทำ แล้วมันอาจจะกลายเป็นระบบที่ชาญฉลาดและมีประโยชน์อย่างไม่น่าเชื่อก็ได้
และถ้าหากอยากได้โมเดลที่เหมาะสมกับงานแบบ agentic ก็อย่าลืมไปลอง Typhoon 2.5 โมเดลรุ่นล่าสุดที่ออกแบบมาโดยเฉพาะสำหรับงานแบบ ****agentic Typhoon 2.5 ออกแบบมาให้สามารถรับมือกับการเรียกใช้เครื่องมือในสถานการณ์ที่มีความซับซ้อนและมีพลวัตได้ ไม่ว่าคุณกำลังสร้าง agent ทำงานได้ด้วยตัวเองเป็นครั้งแรก หรือกำลังออกแบบระบบที่ประกอบไปด้วย agents หลายตัว Typhoon 2.5 ก็ตอบโจทย์ทั้งนั้น
อย่าลืมมาอวดให้ดูด้วยละ ว่าทุกคนใช้ Typhoon 2.5 สร้างอะไรกันไปบ้าง!
🎉 เซอร์ไพร์ส!

สำหรับของอย่างแรก ผมได้เตรียมโปรเจกต์ตัวอย่างที่จะแสดงให้เห็นถึง best practices และหลักการต่าง ๆ ที่พูดถึงไปในโพสต์นี้ โดยทุกคนสามารถเล่นกับโปรเจกต์ได้เพื่อให้เข้าใจได้ดีขึ้น โปรเจกต์นี้เป็น agent สำหรับช่วยสนับสนุนด้าน IT (IT support desk) แบบง่าย ๆ ที่จะช่วยค้นหาข้อมูลที่เกี่ยวข้องจากเอกสารและตอบคำถามของผู้ใช้ รวมไปถึงช่วยจัดการ tickets ต่าง ๆ ให้
ทุกคนสามารถเข้าถึงโปรเจกต์ได้ที่ https://github.com/scb-10x/typhoon-it-support-agent
สำหรับของอย่างที่สอง เนื่องจากปัจจุบันหลายหลายคนได้ใช้เครื่องมือสำหรับการพัฒนาที่มี AI เช่น Claude Code หรือ Cursor ก็เลยมีของแถมเป็นไฟล์ AGENTS.md ที่สามารถใส่เข้าไปในโปรเจกต์แล้วให้ agent อ้างอิงถึงเพื่อช่วยปรับปรุงให้ระบบเป็นไปตามหลักการต่าง ๆ ที่ได้พูดถึงไปในบทความนี้
อย่าลืมกลับมาแชร์กับเราและ community ของ Typhoon ด้วยละว่าสร้างอะไรสนุก ๆ ขึ้นมาบ้าง :)

