

ที่ Typhoon เรามุ่งมั่นผลักดันให้การนำเทคโนโลยี Large Language Models (LLMs) มาใช้จริงเป็นเรื่องง่ายขึ้น พร้อมทั้งสนับสนุนการเติบโตของชุมชน Thai NLP อย่างต่อเนื่อง ซึ่งหมายถึงการทำให้โมเดล LLM ไม่ใช่แค่ฉลาดแต่ยังใช้งานได้จริงในบริบทภาษาไทย
แม้ว่าโมเดลอย่าง Typhoon2 70B จะได้รับความนิยมอย่างสูงในชุมชน แต่การใช้งานมักต้องพึ่งพา GPU ระดับสูงราคาแพง (เช่น 2×H100) ซึ่งเป็นข้อจำกัดสำหรับหลายองค์กร
วันนี้เรายินดีอย่างยิ่งที่จะประกาศเปิดตัวโมเดล Typhoon 2.1 “Gemma” ก้าวกระโดดครั้งใหม่ของเราในการทำให้ LLM มีขนาดเบาลง ติดตั้งง่ายขึ้น โดยไม่ลดทอนประสิทธิภาพ
Typhoon 2.1 เปิดตัวมาพร้อมกัน 2 ขนาด 4B และ 12B โดย 12B รองรับการใช้งานบน GPU กลาง ๆ อย่าง L4, การ์ดจอเกมมิ่งที่มีการทำ quantization หรือแม้กระทั่ง MacBook ชิป M-series ในขณะที่โมเดล 4B สามารถใช้งานโดยมีเพียง CPU ได้ เช่น โน้ตบุ๊กส่วนตัวและอุปกรณ์พกพา
จุดเด่น
-
สอง sizes ที่เข้าถึงได้: ไม่ว่าคุณจะรันบน CPU มาตรฐานหรือ GPU ประสิทธิภาพสูง Typhoon 2.1 มีทั้งรูปแบบ 4B และ 12B เพื่อให้เหมาะกับการตั้งค่าของคุณ
-
เล็กแต่แรง: โมเดล 4B นำ AI ที่เร็วและใช้งานง่ายมาอยู่ในอุปกรณ์ทั่วไป ในขณะที่โมเดล 12B ให้ผลลัพธ์ที่ดีที่สุดบน Macbook M Series และ GPU เล่นเกม
-
แซงรุ่นพี่: ทำผลงานดีกว่า Typhoon 2 70B Instruct ในการประเมินแบบทั่วไป ด้วยขนาดเพียงเศษเสี้ยว
-
การควบคุมที่ดีขึ้น: การจัดการคำสั่งที่ดีขึ้นและการทำงานระหว่างภาษาที่ดีขึ้นทำให้การโต้ตอบมีประโยชน์มากกว่าเดิม
-
โมเดลพื้นฐานที่แข็งแกร่ง: สร้างบน Gemma 3 ซึ่งเป็นหนึ่งในโมเดล LLM แบบโอเพ่นซอร์สที่ทรงพลังที่สุดจาก Google
-
โหมด "คิดลึก" หรือ "เร็วประหยัด" เลือกได้เอง: เปิดโหมดคิดลึก (thinking mode) เพื่อให้ได้ผลลัพธ์คุณภาพสูง หรือปิดเพื่อผลลัพธ์ที่เร็วและประหยัดต้นทุนมากกว่า
-
พร้อมใช้งานฟรี: ดาวน์โหลดได้ที่ Hugging Face และ Ollama.
บทนำ: พัฒนาการของโมเดล
ตลอดช่วงที่ผ่านมา โมเดลพื้นฐาน (base models) มีประสิทธิภาพสูงขึ้นและมีต้นทุนที่ถูกลง ทำให้เราสามารถพัฒนาโมเดล Typhoon ที่เน้นภาษาไทยและเข้าถึงได้ง่ายมากขึ้น เราเริ่มจากการสร้าง Typhoon 1 บนฐานของ Mistral และประเมินความรู้ด้วย ThaiExam ต่อมาใน Typhoon 2 เราหันมาเน้นเรื่อง instruction-following หรือความสามารถในการให้โมเดลเข้าใจคำสั่งและตอบคำถามที่มีประโยชน์และมีการให้เหตุผล
เมื่อมาถึงยุคของ Gemma 3 เราเห็นศักยภาพที่ยอดเยี่ยมในหลายแง่มุมของภาษาไทย แต่ความท้าทายก็เปลี่ยนไป
จากเดิมที่เน้นความรู้ → มาสู่ปัญหาเรื่อง alignment และ preference ของผู้ใช้งาน
แม้ว่า Gemma 3 จะเป็นโมเดล LLM ที่ทรงพลังมาก เทียบได้กับ DeepSeek v3 ที่มีพารามิเตอร์ 685B โดยใช้พารามิเตอร์เพียง 27B ก็ตาม แต่ยังมีปัญหาในเวอร์ชันขนาดเล็ก เช่น
-
เมื่อคุณผสมภาษาในพรอมต์ มันมักจะตอบเป็นภาษาอังกฤษ แม้ว่าจะได้รับคำสั่งให้ตอบเป็นภาษาไทยก็ตาม
-
ไม่มีความสามารถในการใช้คำนวณเพิ่มเติมหรือเข้าใจกระบวนการคิดสำหรับคำถามที่ยาก เช่น โมเดลด้านการให้เหตุผล
จากเรื่องราวนี้ จึงเกิดเป็น Typhoon 2.1 12B ซึ่งทัดเทียมกับ Typhoon 2 70B ในด้านประสิทธิภาพภาษาไทย ในขณะเดียวกันก็สามารถโฮสต์โดยใช้ GPU เกมมิ่งและ instance L4 หรือรันบน CPU เมื่อทำ quantization นอกจากนี้ยังมีเพิ่มฟีเจอร์ thinking mode เพื่อเปิดทางให้ผู้ใช้เลือกได้ระหว่างคำตอบเร็ว หรือคำตอบที่คิดลึกมากขึ้น
วิธีการเทรน
เพื่อพัฒนา Typhoon 2.1 Gemma3 เราใช้วิธีการใหม่โดยอาศัยการ supervised fine-tuning และ merging จากสูตรของ Typhoon 2 R1 เสริมด้วย RL finetuning ซึ่งเราจะเปิดเผยเป็นเปเปอร์หลังจากนี้ โดยหลักการคือเพื่อแก้ artifact ที่เกิดจาก merging และฝึกให้โมเดลสามารถคิดอย่างมีขั้นตอนเมื่อเจอโจทย์ซับซ้อน
การประเมินประสิทธิภาพ
เพื่อประเมิน Typhoon 2.1 เราใช้ชุดข้อมูลเดียวกับที่ใช้กับ Typhoon 2 เพื่อวัดความสามารถในการปฏิบัติตามคำสั่งในภาษาไทยและอังกฤษ
ประสิทธิภาพการปฏิบัติตามคำสั่งทั่วไป
-
MT-Bench: แพลตฟอร์มที่ประเมินความถูกต้อง ความคล่องตัว และการปฏิบัติตามคำสั่งในคำถามแบบเปิด เราใช้ทั้ง Thai MT-Bench และ English MT-Bench จาก LMSYS
-
IFEval: ประเมินความแม่นยำในการปฏิบัติตามคำสั่งตามกรณีทดสอบที่สามารถตรวจสอบได้ เราใช้ทั้ง IFEval ภาษาอังกฤษ และ เวอร์ชันภาษาไทย
-
Language Accuracy & Code-Switching: วัดว่าโมเดลตอบในภาษาที่ถูกต้องหรือไม่และรักษาความสอดคล้องทางภาษา เราตัวอย่างคำสั่งภาษาไทย 500 รายการจากชุดข้อมูล WangchanThaiInstruct ที่ใช้ใน Typhoon2
ประสิทธิภาพด้านคณิตศาสตร์และโค้ด
-
MATH500: ซับเซ็ตของ MATH Benchmark ที่มีปัญหาคณิตศาสตร์ขั้นสูง 500 ข้อเพื่อทดสอบการให้เหตุผลแบบขั้นตอน เราแปลเป็นภาษาไทยด้วย ทำให้มีทั้งหมด 1,000 ข้อ
-
LiveCodeBench: Benchmark การเขียนโปรแกรมแบบแข่งขันที่มีปัญหาจาก LeetCode, AtCoder, และ CodeForces รวมทั้งหมด 511 ข้อ เมื่อรวมกับเวอร์ชันแปลไทย จะมีทั้งหมด 1,022 ข้อ เราประเมินโดยการสุ่มตัวอย่าง 200 ข้อ
ผลการประเมิน
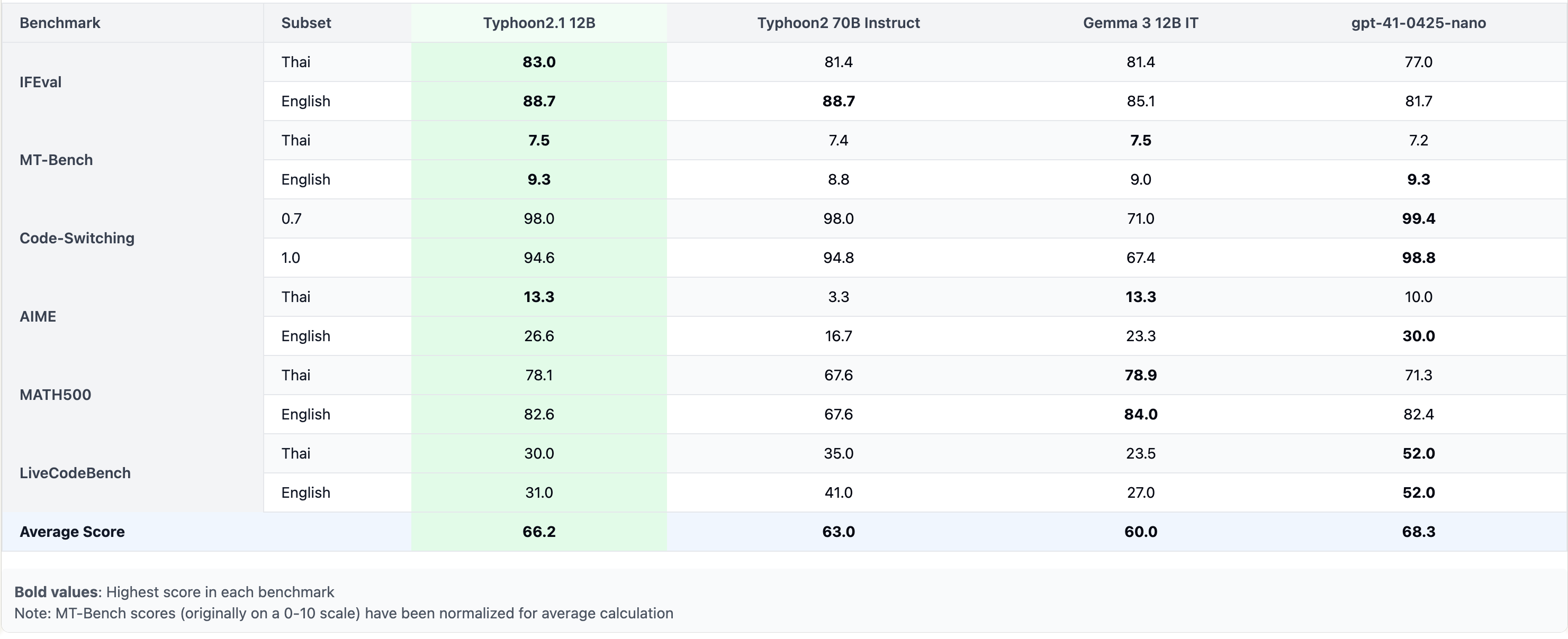
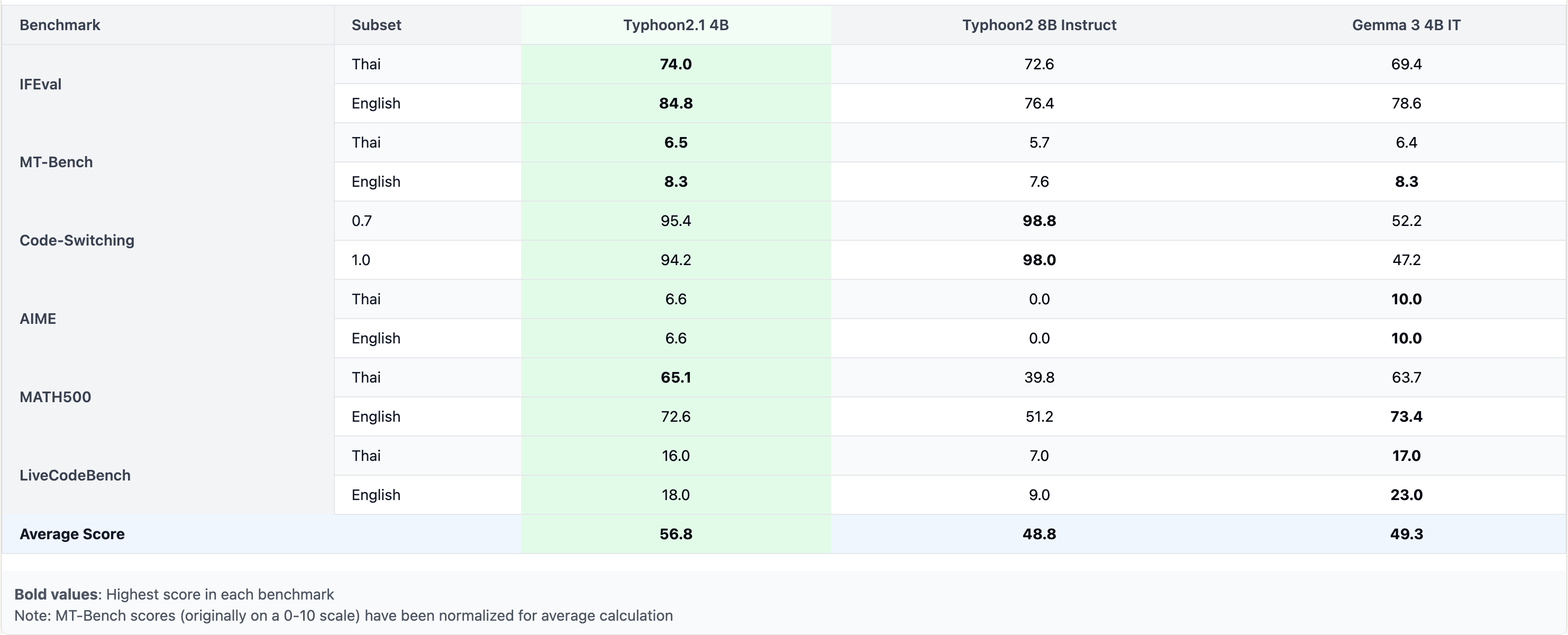
การอภิปรายผลจาก Benchmark
จากผลลัพธ์ เราสามารถเห็นว่า Typhoon 2.1 12B มีประสิทธิภาพใกล้เคียงกับ Typhoon 2 70B แต่มีขนาดเล็กกว่ามาก ในขณะเดียวกันก็ปรับปรุงประสิทธิภาพด้านความแม่นยำทางภาษาและการสลับโค้ดให้ดีขึ้นกว่า Gemma 3 มากกว่า 20% นอกจากนี้โมเดลขนาดเพียง 4B ก็ทำได้ดีกว่า Typhoon 2 8B Instruct
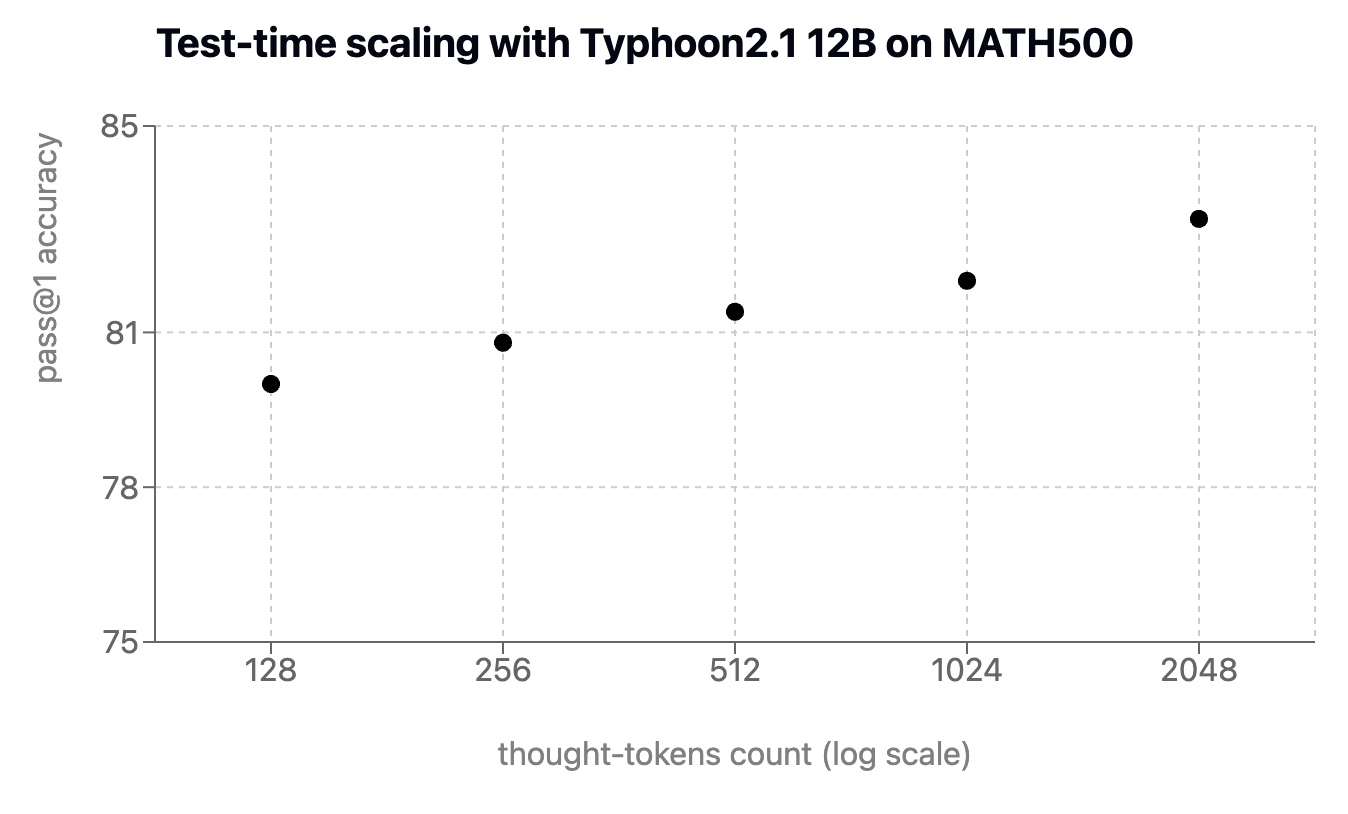
การใช้โทเคนมากขึ้นเพื่อเพิ่มประสิทธิภาพ
เพื่อแสดงพลังของการปรับขนาดในเวลาทดสอบ เราเทรน Typhoon 2.1 โดยมีลักษณะการคิดยาวแบบปรับได้ โดยใช้กลยุทธ์บังคับจาก s1 ซึ่งใช้ตัวอักษรเพิ่มเติมสำหรับการให้เหตุผลยาวในข้อมูลชุด MATH500 แสดงให้เห็นว่า Typhoon 2.1 12B มีประสิทธิภาพที่แข็งแกร่งขึ้นเมื่อมีการจัดสรรตัวอักษรเพิ่มเติม
สรุป
Typhoon 2.1 คืออีกก้าวสำคัญของเราในการทำให้ LLM ใช้งานได้จริงในบริบทของประเทศไทย รันได้บนเครื่องเล็ก เข้าใจภาษาไทยลึก และเปิดทางให้ทุกคนสร้างนวัตกรรมใหม่ ๆ ได้ง่ายขึ้น
เริ่มใช้งานได้เลยวันนี้:
👉 ทดลองใช้งานผ่าน API ที่ opentyphoon.ai
👉 อ่าน คู่มือ self-host บน Ollama (และบทความอื่น ๆ เร็ว ๆ นี้)
หมายเหตุ: เนื้อหาบางส่วนของบล็อกนี้เขียนโดย Typhoon 2.1 และ Typhoon 2 R1

